在人工智能的浩瀚宇宙中,自然语言处理(NLP)一直是一个充满挑战和机遇的领域。随着技术的发展,我们见证了从传统规则到统计机器学习,再到深度学习和预训练模型的演进。如今,我们站在了大型语言模型(LLM)的门槛上,它们正在重新定义我们与机器交流的方式。本文将深入探讨LLM的发展历程、技术路线、以及它们对未来AI领域的影响。
引言
自然语言处理(NLP)的目标是让机器能够理解、解释和生成人类语言。这一领域的发展经历了几个重要的阶段,每个阶段都标志着对语言理解深度的一次飞跃。从早期的基于规则的系统,到统计学习方法,再到深度学习模型,直至今日的大型语言模型(LLM),每一步都是对前一阶段的超越。

从规则到统计:NLP的早期探索
规则阶段(1956—1992)
在NLP的早期,研究者依赖于手工编写的规则来处理语言。这一阶段的技术栈包括有限状态机和基于规则的系统。例如,Apertium就是一个基于规则的机器翻译系统,它展示了早期研究者如何通过人工整理词典和编写规则来实现语言的自动翻译。

统计机器学习阶段(1993—2012)
随着时间的推移,研究者开始转向统计学习方法,使用支持向量机(SVM)、隐马尔可夫模型(HMM)、最大熵模型(MaxEnt)和条件随机场(CRF)等工具。这一阶段的特点是少量人工标注领域数据与人工特征工程的结合,标志着从手工编写规则到机器自动从数据中学习知识的转变。

深度学习的突破:开启新纪元
深度学习阶段(2013—2018)
深度学习的出现为NLP带来了革命性的变化。以编码器-解码器(Encoder-Decoder)、长短期记忆网络(LSTM)、注意力机制(Attention)和嵌入(Embedding)为代表的技术,使得模型能够处理更大规模的数据集,并且几乎不需要人工特征工程。Google的神经机器翻译系统(2016)就是这一阶段的代表之作。

预训练模型的兴起:知识的自我发现
预训练阶段(2018—2022)
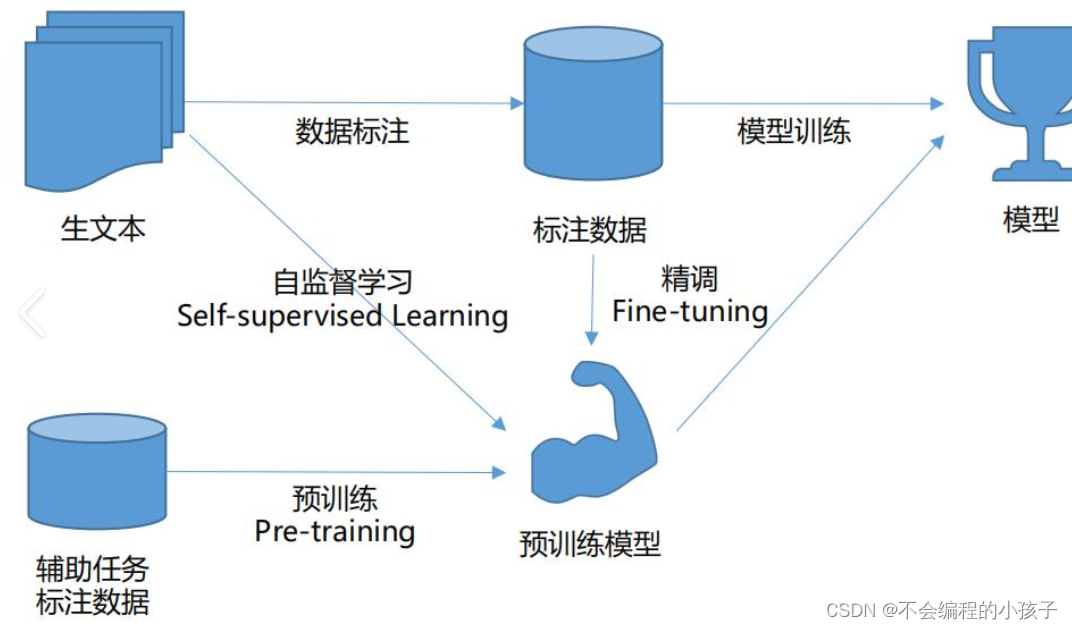
预训练模型的出现标志着NLP领域的又一次飞跃。以Transformer和注意力机制为核心的技术栈,结合海量无标注数据进行自监督学习,生成通用知识,再通过微调适应特定任务。这一阶段的突变性非常高,因为它扩展了可利用的数据范围,从标注数据拓展到了非标注数据。

LLM的新时代:智能与通用性的融合
LLM阶段(2023—?)
LLM代表了语言模型的最新发展,它们通常采用解码器为主的架构,结合了Transformer和强化学习人类反馈(RLHF)。这一阶段的特点是两阶段过程:预训练和与人类对齐。预训练阶段利用海量无标注数据和领域数据,通过自监督学习生成知识;与人类对齐阶段则通过使用习惯和价值观对齐,使模型能够适应各种任务。

回顾各个发展阶段可以看到以下趋势:
数据: 从数据到知识,越来越多数据被利用起来/未来:更多文本数据、更多其它形态数据→任何数据
算法: 表达能力越来越强;规模越来越大;自主学习能力越来越强;从专业向通用/未来:Transformer目前看够用,新型模型(应该强调学习效率)?→AGI?
人机关系: 位置后移,从教导者到监督者/未来:人机协作,机向人学习→人向机学习?→机器拓展人类知识边界

LLM技术发展路线:多样化的路径
在过去的几年中,LLM技术发展呈现出多样化的路径,包括BERT模式、GPT模式和T5模式等。每种模式都有其特点和适用场景。

BERT模式(Encoder-Only)
BERT模式通过双向语言模型预训练和任务微调的两阶段(双向语言模型预训练+任务Fine-tuning)过程,适用于自然语言理解类任务。BERT预训练从通用数据中提取通用知识,而微调则从领域数据中提取领域知识。

适合解决的任务场景:比较适合自然语言理解类,某个场景的具体任务,专而轻;

GPT模式(Decoder-Only)
GPT模式则从单向语言模型预训练和zero shot/few shot prompt或指令的一阶段(单向语言模型预训练+zero shot/few shot prompt/Instruct)过程中发展而来,适合自然语言生成类任务。GPT模式的模型通常是目前规模最大的LLM,它们能够处理更广泛的任务。

适用场景:比较适合自然语言生成类任务,目前规模最大的LLM,都是这种模式:GPT 系列,PaLM,LaMDA……,重而通;生成类任务/通用模型 建议GPT模式;

T5模式(Encoder-Decoder)
T5模式结合了BERT和GPT的特点,适用于生成和理解任务。T5模式的填空任务(Span Corruption)是一种有效的预训练方法,它在自然语言理解类任务中表现出色。两阶段(单向语言模型预训练+Fine-tuning为主)

特点:形似GPT,神似Bert
适用场景:生成和理解都行,从效果上看比较适合自然语言理解类任务,国内很多大型LLM采取这种模式;如果是单一领域的自然语言理解类任务,建议使用T5模式;

为什么超大LLM都是GPT模式
超大LLM:追求zero shot/ few shot/instruct 效果
目前的研究结论
(模型规模不大时):
- 自然语言理解类:T5模式效果最好。
- 自然语言生成类:GPT模式效果最好。
- Zero shot: GPT模式效果最好。
如果Pretrain后引入多任务fine-tuning,则T5模式效果好(结论存疑:目前的实验Encoder-Decoder都是Decoder-only参数量的两倍,结论是否可靠?)
目前的研究结论(超大规模):
事实:几乎所有超过100B的LLM模型,都采取GPT模式
可能的原因:
1.Encoder-Decoder里的双向attention,损害zero shot能力(Check)
2.Encoder-Decoder结构在生成Token时,只能对Encoder高层做attentionDecoder-only结构在生成Token时,可以逐层Attention,信息更细粒度
3.Encoder-Decoder训练“中间填空”,生成最后单词Next Token,存在不一致性Decoder-only结构训练和生成方式一致
超大LLM的挑战与机遇
随着模型规模的增长,研究者面临着如何有效利用参数空间的挑战。Chinchilla模型的研究表明,在数据充足的情况下,当前的LLM规模可能比理想规模更大,存在参数空间的浪费,然而,Scaling Law也指出,模型规模越大,数据越多,训练越充分,LLM模型的效果越好。比较可行的思路是:先做小(GPT 3本来不应该这么大),再做大(充分利用模型参数后,继续做大)。

当然鉴于多模态LLM需要更丰富的现实环境感知能力,对此LLM参数也提出更高的要求。
多模态LLM:视觉输入(图片、视频)、听觉输入(音频)、触觉输入(压力)

面临问题:多模态LLM看着效果还不错,很大程度依赖于人工整理的大数据集
如 ALIGN:1.8B 图文/LAION:5.8B图文数据(经过CLIP过滤,目前最大图文数据)目前是文字带图像飞?
图像处理:自监督技术路线在尝试,尚未走通(对比学习/MAE)/如果能走通会是AI领域另外一次巨大技术突破;
如果能走通,目前的一些图像理解类任务(语义分割/识别等)估计会被融入LLM,进而消失

提升LLM的复杂推理能力
尽管当前的LLM具备一定的简单推理能力,但在复杂推理方面仍有不足。例如,多位数加法等任务对LLM来说仍然是一个挑战。研究者正在探索如何通过技术手段,如语义分解,将复杂推理能力蒸馏到更小的模型中。

当然也可以通过能力外包的形式绕过这个问题,如与工具结合:计算能力(外部计算器)、新信息查询(搜索引擎)等能力借助外部工具完成。

LLM与物理世界的交互
具身智能的概念将LLM与机器人技术结合起来,通过与物理世界的交互,利用强化学习获得具身智能。例如,Google的PaLM-E模型结合了540B的PaLM和22B的ViT,展示了LLM在多模态环境下的潜力。


其他研究方向
- 新知识的获取:目前有一定困难,也有一些手段(LLM+Retrieval)
- 旧知识的修正:目前有一些研究成果,尚需优化
- 私域领域知识的融入:Fine-tune?
- 更好的理解命令:尚需优化(一本正经的胡说八道)
- 训练推理成本的降低:未来一年到两年会快速发展
- 中文评测数据集的构建:能力试金石。英文目前有一些评测集,比如HELM/BigBench等,中文缺乏/多任务、高难度、多角度的评测数据集。
结语
本文深入探讨了LLM的发展历程、技术路线以及它们对未来AI领域的影响。LLM的发展不仅仅是技术的进步,更是我们对机器理解能力的一次深刻反思。从规则到统计,再到深度学习和预训练,每一步都为我们提供了新的视角和工具。如今,我们站在大型语言模型的新时代门槛上,面对着前所未有的机遇和挑战。