数据的完美贴合:SKlearn中的数据拟合方法全解
在数据分析和机器学习中,数据拟合是使用数学模型来描述数据的过程。一个好的拟合模型能够捕捉数据的关键特征,并对未来的数据进行预测。Scikit-learn(简称sklearn),作为Python中一个功能强大的机器学习库,提供了多种数据拟合方法。本文将详细介绍sklearn中用于数据拟合的方法,并提供实际的代码示例。
1. 数据拟合的重要性
数据拟合对于以下方面至关重要:
- 模式识别:通过拟合发现数据中的模式和趋势。
- 预测分析:基于历史数据预测未来的数据点。
- 决策支持:为基于数据的决策提供支持。
2. sklearn中的数据拟合方法
sklearn提供了多种数据拟合方法,主要包括:
- 线性回归:用于拟合线性关系的数据。
- 多项式回归:用于拟合非线性关系的数据。
- 支持向量机(SVM):用于拟合复杂的边界。
- 决策树和随机森林:用于拟合复杂的决策边界。
- K-近邻(KNN):用于基于邻近点的预测。
3. 使用线性回归进行数据拟合
线性回归是最基本的拟合方法,适用于线性数据。
from sklearn.linear_model import LinearRegression
import numpy as np
# 假设X是特征矩阵,y是目标变量
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 5, 4, 5])
# 创建线性回归模型实例
model = LinearRegression()
# 拟合模型
model.fit(X, y)
# 预测新数据
X_new = np.array([[6]])
y_pred = model.predict(X_new)
print("Predicted value:", y_pred)
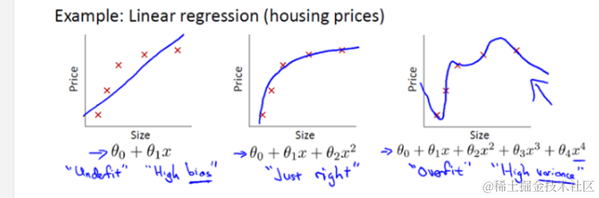
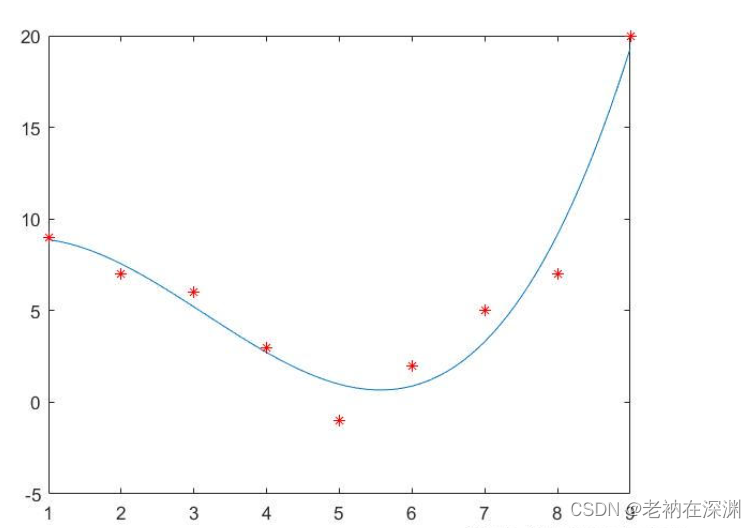
4. 使用多项式回归进行数据拟合
多项式回归可以拟合非线性数据。
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# 创建多项式特征
poly_features = PolynomialFeatures(degree=2)
X_poly = poly_features.fit_transform(X)
# 创建线性回归模型实例
model = LinearRegression()
# 拟合模型
model.fit(X_poly, y)
# 预测新数据
X_new = np.array([[6]])
X_new_poly = poly_features.transform(X_new)
y_pred = model.predict(X_new_poly)
print("Predicted value:", y_pred)
5. 使用支持向量机(SVM)进行数据拟合
SVM可以拟合复杂的非线性边界。
from sklearn.svm import SVR
# 创建SVM模型实例
model = SVR(kernel='rbf', C=100, gamma=0.1)
# 拟合模型
model.fit(X, y)
# 预测新数据
y_pred = model.predict(X_new)
print("Predicted value:", y_pred)
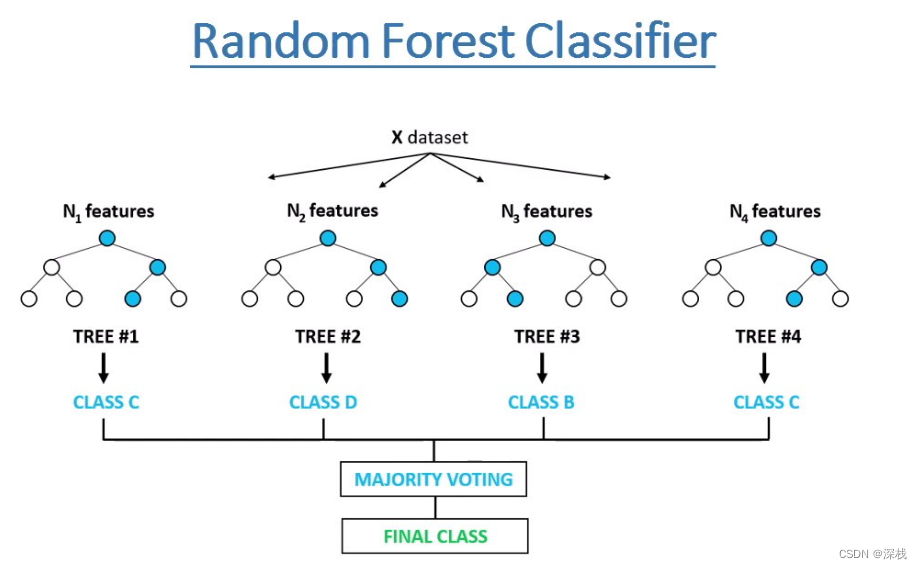
6. 使用决策树和随机森林进行数据拟合
决策树和随机森林可以拟合复杂的决策边界。
from sklearn.ensemble import RandomForestRegressor
# 创建随机森林模型实例
model = RandomForestRegressor(n_estimators=100, random_state=42)
# 拟合模型
model.fit(X, y)
# 预测新数据
y_pred = model.predict(X_new)
print("Predicted value:", y_pred)
7. 使用K-近邻(KNN)进行数据拟合
KNN基于邻近点进行预测。
from sklearn.neighbors import KNeighborsRegressor
# 创建KNN模型实例
model = KNeighborsRegressor(n_neighbors=3)
# 拟合模型
model.fit(X, y)
# 预测新数据
y_pred = model.predict(X_new)
print("Predicted value:", y_pred)
8. 结论
数据拟合是数据分析和机器学习中的一个基本步骤。sklearn提供了多种数据拟合方法,包括线性回归、多项式回归、支持向量机、决策树、随机森林和K-近邻等。每种方法都有其特定的应用场景和优势。
本文详细介绍了sklearn中不同的数据拟合方法,并提供了实际的代码示例。希望本文能够帮助读者更好地理解数据拟合的概念,并掌握在sklearn中实现这些技术的方法。随着数据量的不断增长和分析需求的提高,数据拟合将在数据科学领域发挥越来越重要的作用。

































![[C++]入门基础(1)](https://i-blog.csdnimg.cn/direct/6ccaf6ce38f24bd096a8d1aa543c35e4.png)

![[数据集][目标检测]睡岗检测数据集VOC+YOLO格式3290张4类别](https://img-blog.csdnimg.cn/direct/52daa1d19dec497ca781725b1fa22369.gif)