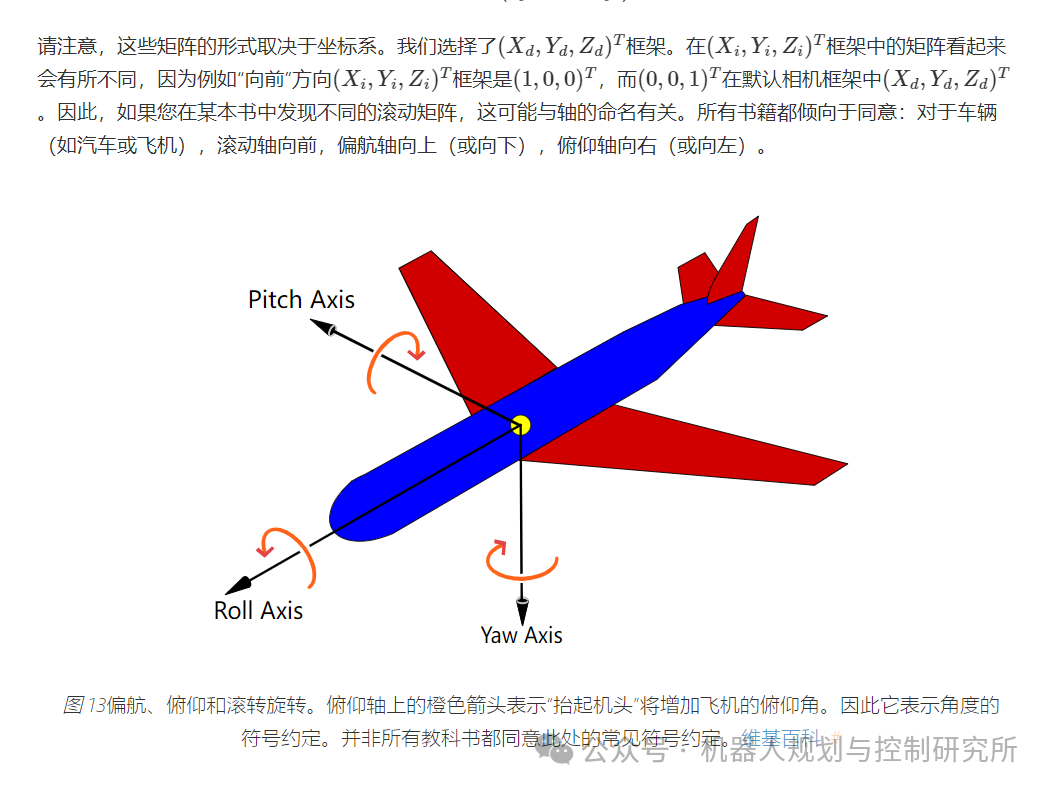
“
在本章中,我将指导您构建一个简单但有效的车道检测管道,并将其应用于Carla 模拟器中捕获的图像。管道将图像作为输入,并产生车道边界的数学模型作为输出。图像由行车记录仪(固定在车辆挡风玻璃后面的摄像头)捕获。车道边界模型是一个多项式
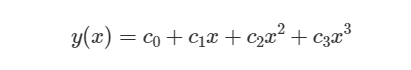
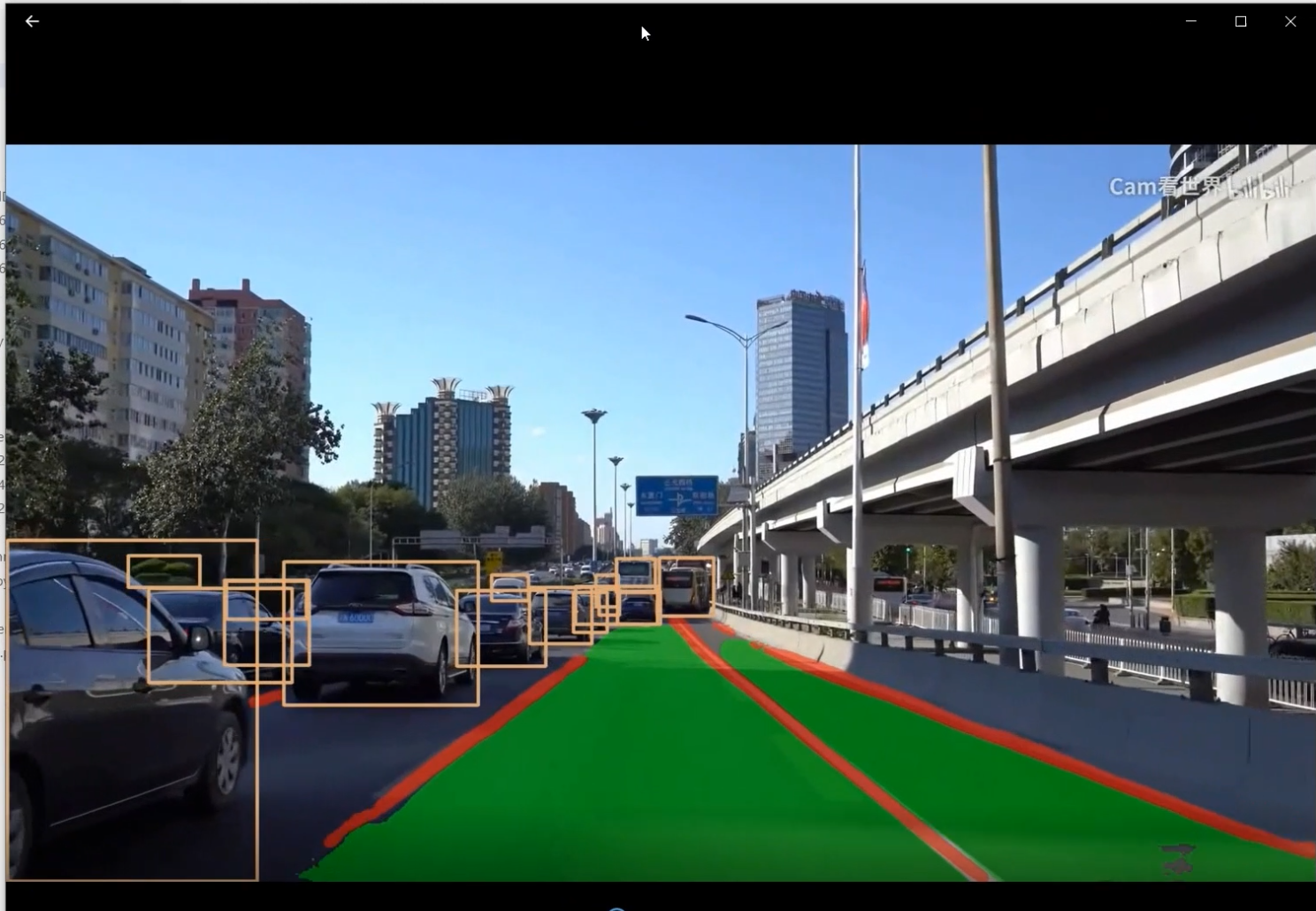
在这里,x𝑥和𝑦y以米为单位。它们在道路上定义了一个坐标系,如图1所示。
管道由两个步骤组成
使用神经网络,检测图像中车道边界的像素
将车道边界像素与道路上的点关联起来,
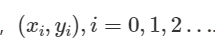
然后拟合多项式。
该方法的灵感来自参考文献[ GBN+19 ]中描述的“基线”方法,其性能接近最先进的车道检测方法。
”

图 1道路坐标系。该视角称为鸟瞰图。
01
—
图像基础

为了表示图像,我们使用形状为 (H,W,3) 的三维数组。我们称该数组有 H 行、W 列和 3 个颜色通道(红色、绿色和蓝色)。让我们用 Python 加载图像并查看一下!
import numpy as npimport matplotlib.pyplot as pltfrom pathlib import Pathimport cv2img_fn = str(Path("images/carla_scene.png"))img = cv2.imread(img_fn)# opencv (cv2) stores colors in the order blue, green, red, but we want red, green, blueimg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)plt.imshow(img)plt.xlabel("$u$") # horizontal pixel coordinateplt.ylabel("$v$") # vertical pixel coordinateprint("(H,W,3)=",img.shape)
(H,W,3)= (512, 1024, 3)
让我们检查一下第 100 行和第 750 列的像素:
u,v = 750, 100img[v,u]
array([28, 59, 28], dtype=uint8)这意味着 处的像素具有红色强度 28、绿色强度 59 和蓝色强度 28。因此,它是绿色的。如果我们看一下图像,这是有道理的,因为 处有一棵树。此外,上面的输出“ ”告诉我们红色、绿色和蓝色强度存储为 8 位无符号整数,即。因此,它们是 0 到 255 之间的整数。u,v = 750, 100u,v = 750, 100dtype=uint8uint8
下面的示意图总结了我们迄今为止学到的关于存储数字光栅图像的知识:

如果您的数字图像是由相机拍摄的,那么数字图像中的像素与相机图像传感器中的“传感器像素”之间存在直接对应关系。

图像传感器由二维光电传感器阵列组成。每个光电传感器通过光电效应将入射光转换为电能,然后通过模数转换器将其转换为数字信号。为了获得颜色信息,一个“传感器像素”被分成 2×2 的光电传感器网格,并在这 4 个光电传感器前面放置不同的颜色滤镜。一个光电传感器仅通过蓝色滤镜接收光,一个仅通过红色滤镜接收光,两个通过绿色滤镜接收光。将这 4 个测量值结合起来可得到一个颜色三重奏:。这就是所谓的拜耳滤镜。(red_intensity, green_intensity, blue_intensity)

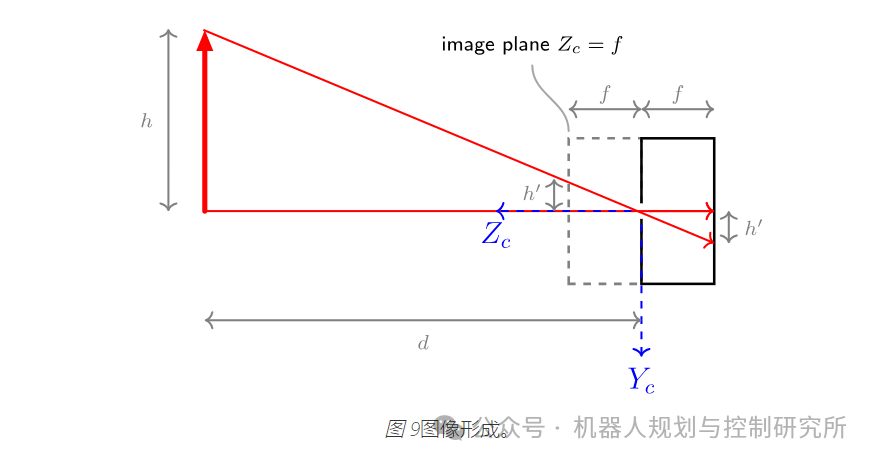
针孔相机模型
想象一下将图像传感器放在物体前面。
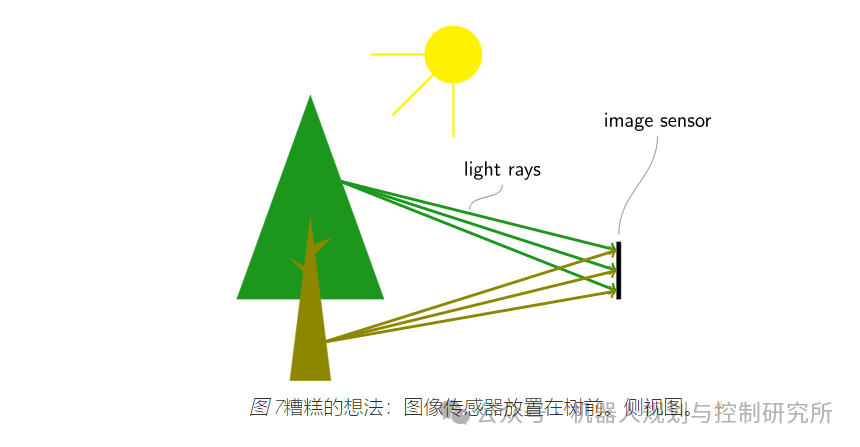
您将无法捕捉到如此清晰的图像,因为图像传感器上的某个点会受到整个环境光线的照射。现在想象一下将图像传感器放在一个带有非常小的针孔(也称为光圈)的盒子里。
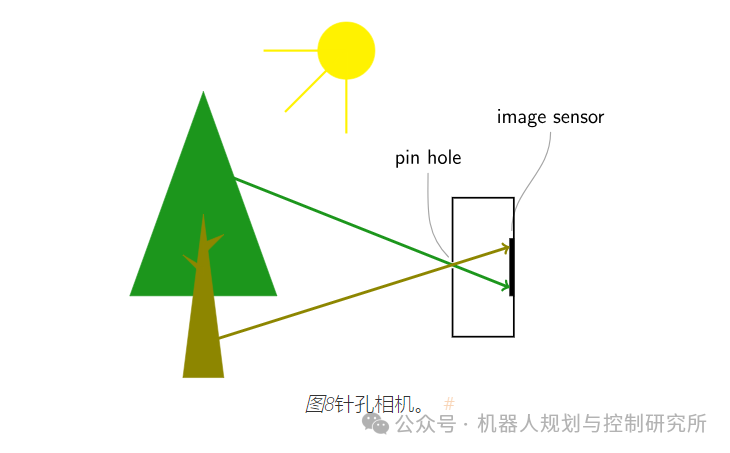
现在大部分光线都被挡住了,我们在图像传感器上得到了正确的图像。图像被上下翻转了,但这不应该困扰我们。在理想针孔的情况下,图像传感器上的每个点都只会被来自外部的一束光线击中。
理想针孔:一个很好的近似值
在现实世界中,孔的尺寸不能太小,因为进入盒子的光线不够。此外,我们还会遭受衍射的影响。孔也不能太大,因为来自不同角度的光线会照射到图像传感器上的同一点,图像会变得模糊。为了防止模糊,真实的相机中会安装镜头。我们将在本节讨论的针孔相机模型不包括镜头的影响。然而,事实证明,它非常接近带镜头的相机,也是相机的事实模型。因此,在下文中,我们可以继续将针孔视为理想的针孔。
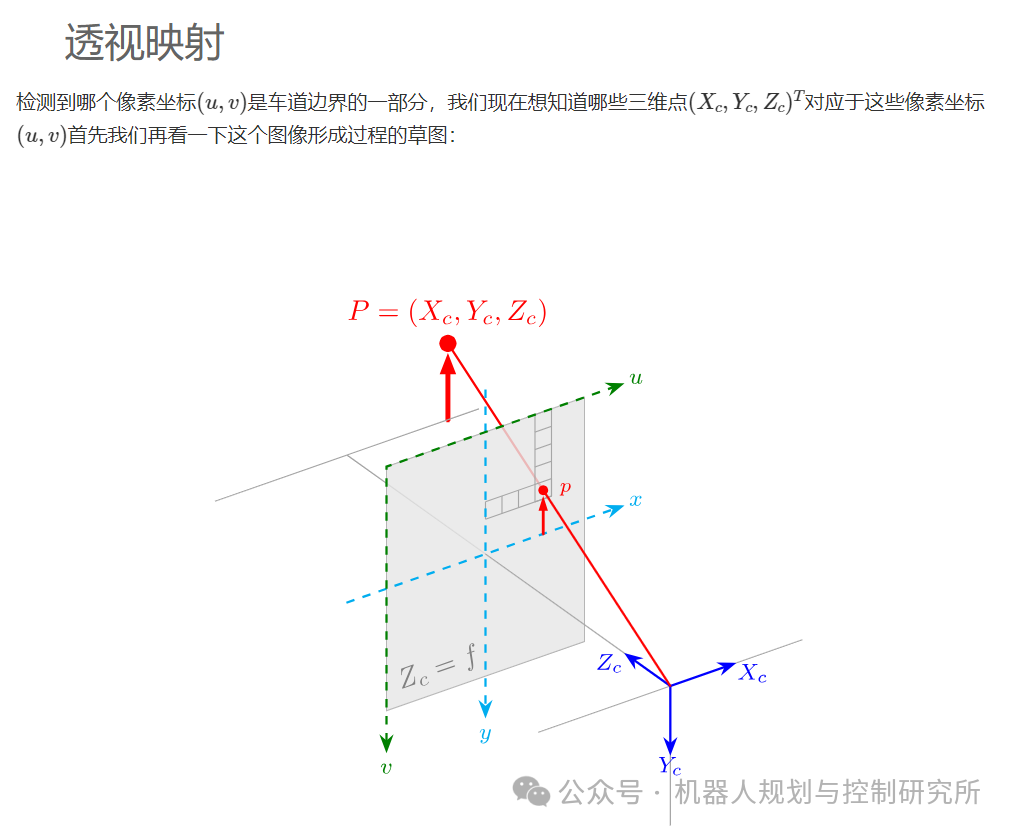
下面的草图介绍了图像平面:


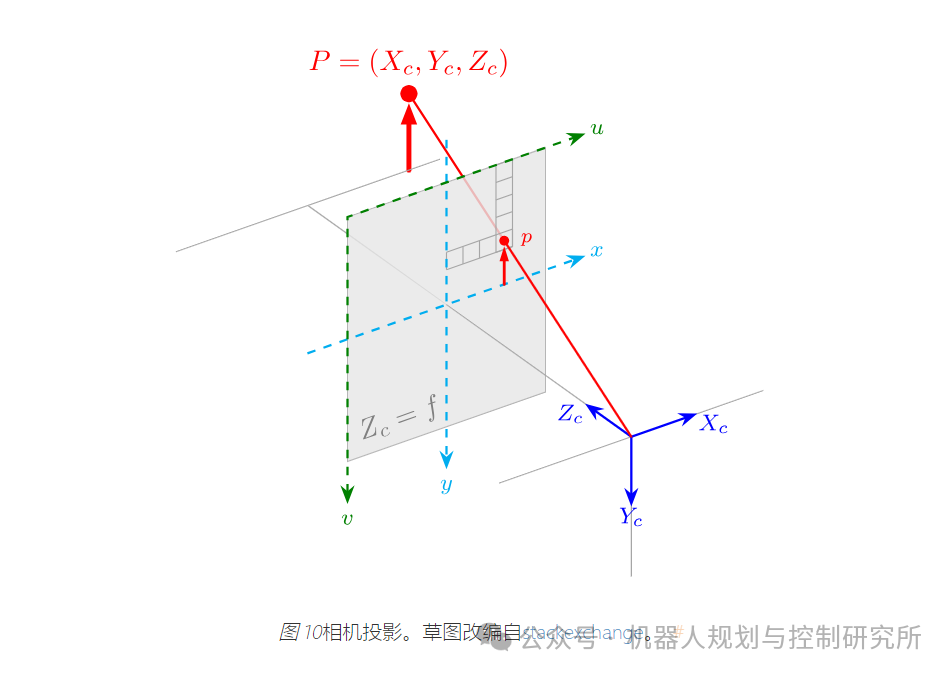
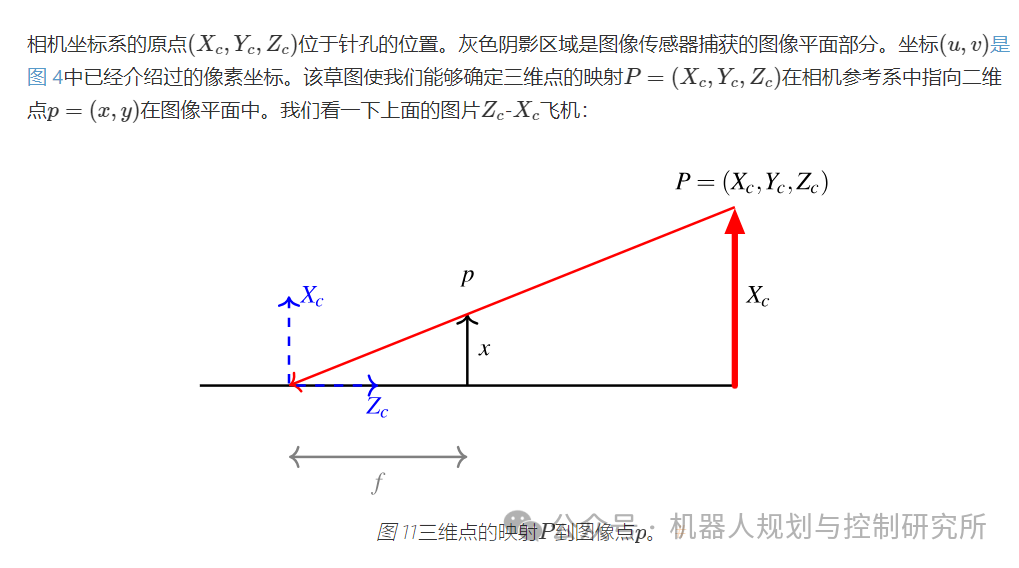







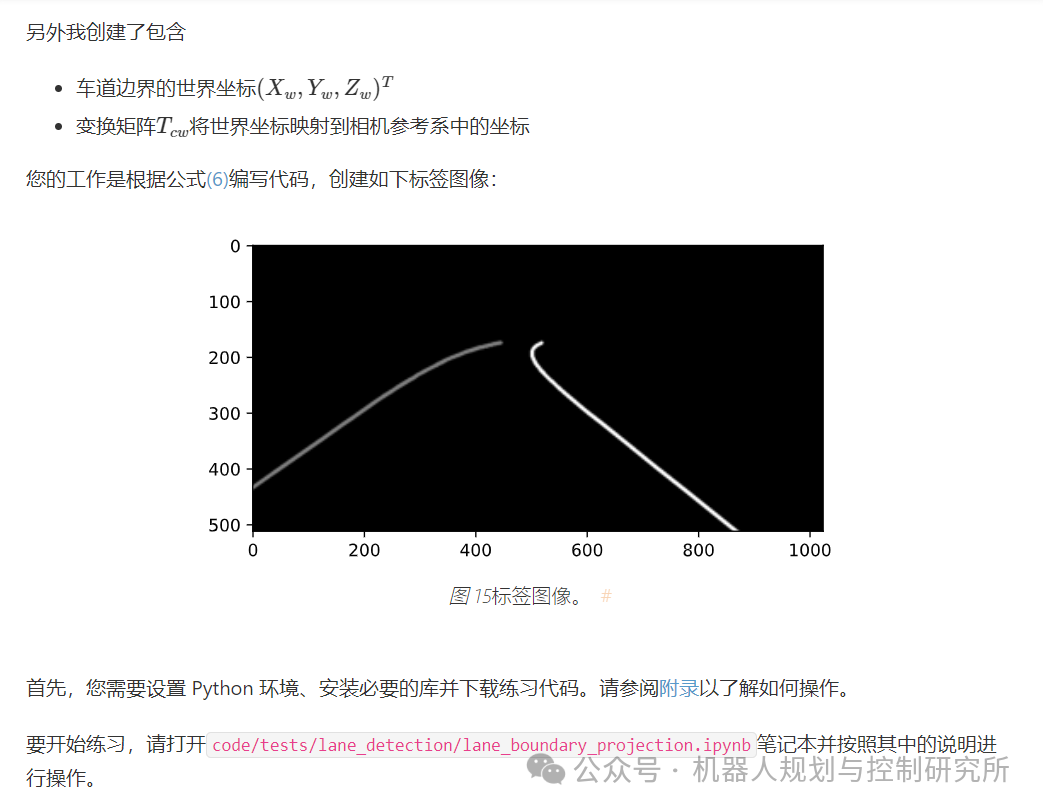
练习:将车道边界投影到图像
现在你应该开始做你的第一个练习了。对于这个练习,我为你准备了一些
数据。我使用安装在车辆上的相机传感器在 Carla 模拟器中捕捉到了一张
图片:

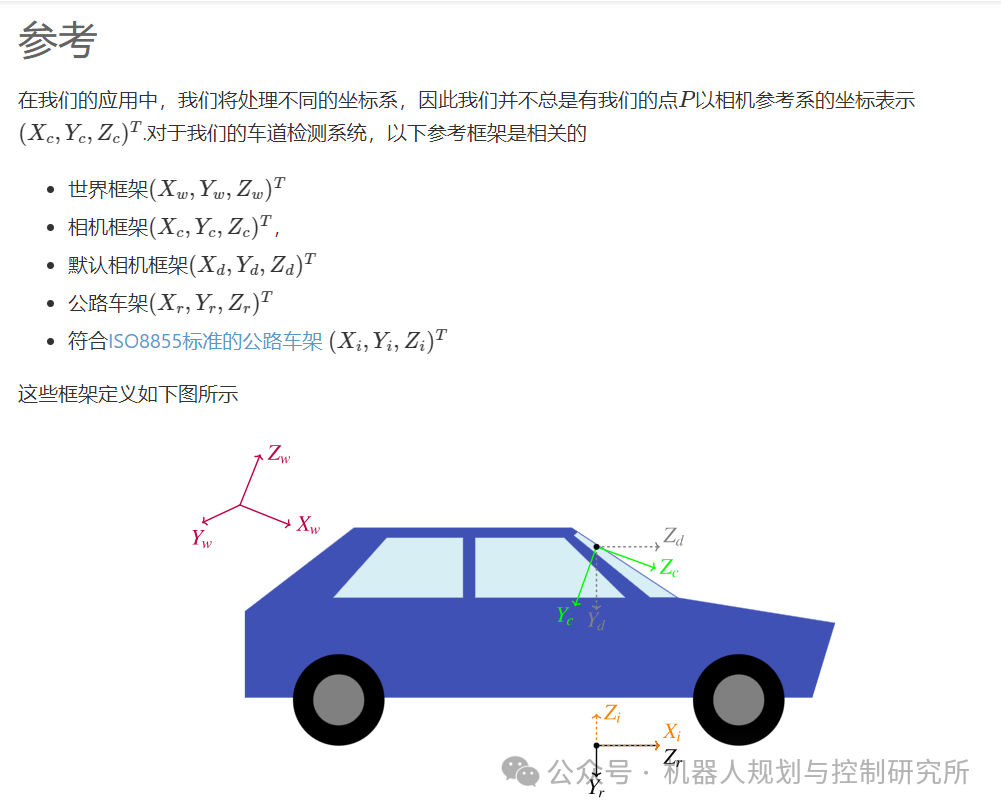
参考
HZ03
Richard Hartley 和 Andrew Zisserman。计算机视觉中的多
视图几何。剑桥大学出版社,2003 年。
02
—
车道边界分割
对于车道检测流程,我们想要训练一个神经网络,该神经网络会获取一张图像,并估计每个像素属于左车道边界的概率、属于右车道边界的概率以及不属于任何车道边界的概率。这个问题称为语义分割。
先决
对于本节,我假设以下内容
你知道什么是神经网络,并且之前自己训练过一个
你知道语义分割的概念
如果你不满足先决条件 1,我建议你查看以下免费资源之一
CS231n:用于视觉识别的卷积神经网络
对于这门优秀的斯坦福课程,你可以在网上找到所有的学习材料。课程笔记还没有完成,但确实存在的笔记非常好!请注意,当你点击详细课程大纲时,你可以看到所有讲座的幻灯片。你可能想使用2017 年的版本,因为其中包含讲座视频。但是,对于练习,你应该使用2020版本(与 2017 年非常相似),因为你可以在Google Colab中进行编程。Google Colab 让你可以在 Google 服务器上免费使用 GPU(深度学习所需的昂贵硬件)。即使你不想使用 Colab,2020 年的课程也有更好的本地工作说明(包括 anaconda)。对于你可以在 tensorflow 和 pytorch 之间选择的练习,我建议你使用 pytorch。如果你真的渴望尽快回到这门课程,你可以在了解语义分割后停止 CS231n。
为程序员提供实用的深度学习
如果您的背景更多的是编码而不是数学/科学,那么我推荐这门课程。您可以在这里找到视频讲座,在这里找到用 jupyter 笔记本编写的书(如果您喜欢,还有一个印刷版本)。我建议使用 Google Colab 进行练习。fastai 课程使用 fastai 库进行讲授,该库可帮助您使用很少的代码行来训练 pytorch 模型。即使您选择不研究 fastai 课程,我也建议您查看fastai 库,因为它使训练模型变得非常容易。也许先从阅读计算机视觉教程开始)。
关于先决条件 2 ,我推荐Jeremy Jordan 撰写的这篇关于语义分割的非常好的博客文章(主要基于 CS231n)。
最后,你需要有 GPU 才能进行练习。但拥有GPU 并不是先决条件。你可以使用Google Colab,它允许你在 Google 服务器上运行 Python 代码。要在 Colab 上访问 GPU,你应该点击“运行时”,然后点击“更改运行时类型”,最后选择“GPU”作为“硬件加速器”。有关如何使用 Colab 的更多详细信息,请参阅附录。
练习:训练神经网络进行车道边界
车道分割模型应将形状为 (512,1024,3) 的图像作为输入。这里,512 是图像高度,1024 是图像宽度,3 代表红、绿、蓝三个颜色通道。我们使用形状为 (512,1024) 的输入图像和相应的标签来训练模型,其中label[v,u]可以取值为 0、1 或 2,表示像素(𝑢,𝑣)是“无边界”、“左边界”还是“右边界”。
模型的输出应是output形状为 (512,1024,3) 的张量。
这个数字
output[v,u,0]给出了像素(𝑢,𝑣)不属于任何车道边界的一部分。这个数字
output[v,u,1]给出了像素(𝑢,𝑣)是左车道边界的一部分。这个数字
output[v,u,2]给出了像素(𝑢,𝑣)是右侧车道边界的一部分。收集训练
我们可以使用 Carla 模拟器收集训练数据。我写了一个
collect_data.py脚本请注意,从四个数据项(图像、车道边界、交通矩阵、标签图像)中,只有图像和标签图像对于训练我们的深度学习模型是必要的。
所有数据均在“Town04”Carla 地图上收集,因为这是唯一一张有可用高速公路的地图(“Town06”的高速公路要么完全笔直,要么有 90 度转弯)。为简单起见,我们只为高速公路构建一个系统。因此,我们只使用地图中道路曲率较低的部分,不包括城市道路。
地图的一部分被任意选为“验证区”。在此区域中创建的所有数据的文件名都添加了字符串“validation_set”。
现在您需要将一些训练数据导入到您的机器上!我建议您下载我使用脚本为您创建的一些训练数据
collect_data.py。但如果您真的想要,您也可以自己收集数据。推荐:下载数据
只需继续打开中的启动代码
code/exercises/lane_detection/lane_segmentation.ipynb即可。它将有一个 Python 实用函数,可为您下载数据。替代方案:自己生成数据
存储来自相机传感器的图像
存储从 Carla 高清地图获得的车道边界的世界坐标
存储变换矩阵𝑇𝑐𝑤将世界坐标映射到相机参考系中的坐标
存储标签图像,该图像是根据车道边界坐标和变换矩阵创建的,如上一节练习中所示
在 Carla 地图上创建一辆车
将 RGB 摄像头传感器安装到车辆上
将车辆移动到不同的位置并
模型
为了创建和训练模型,您可以选择任何您喜欢的深度学习框架。
如果你需要一些指导,我建议使用 fastai。你可以使用fastai 文档中的语义分割示例,根据手头的数据集稍微修改一下,它就可以正常工作了!如果你愿意,你可以得到一些提示:
没有提示
好的,没有提示。如果您遇到困难,请尝试查看“有限提示”或“详细提示”。
基本提示高级提示
存储你的模型
您将需要训练好的模型来进行接下来的练习。因此,请将训练好的模型保存到磁盘。在 pytorch 中,您可以通过 执行此操作
torch.save。对于 fastai,您可以执行torch.save(learn.model, './fastai_model.pth')可选:参与 kaggle 活动
我为你准备的训练数据也可以在kaggle上找到。如果你愿意,你可以用 kaggle 笔记本在线创建你的模型。他们还提供免费的 GPU 访问。一旦你对你的解决方案感到满意,可以考虑在 kaggle 上发布你的笔记本。我很想看到它😃。
具体指引详见《https://thomasfermi.github.io/Algorithms-for-Automated-Driving/LaneDetection/Segmentation.html》
03
—
从像素转换米

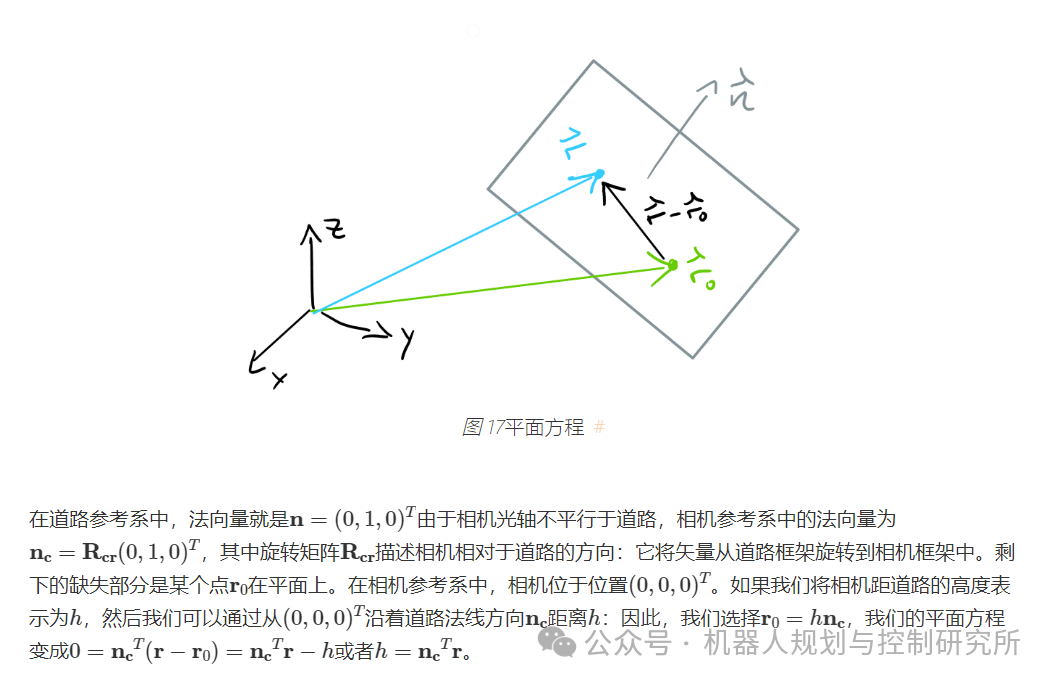


import numpy as npimport matplotlib.pyplot as plt
从车道边界分割中,我们知道我们的语义分割模型将以摄像头图像作为输入,并返回output形状为 (H,W,3) 的张量。具体来说,像素prob_left = output[v,u,1](𝑢,𝑣)是左车道边界的一部分。我将output[v,u,1]神经网络为一些示例图像计算的张量保存在 npy 文件中。让我们来看看。
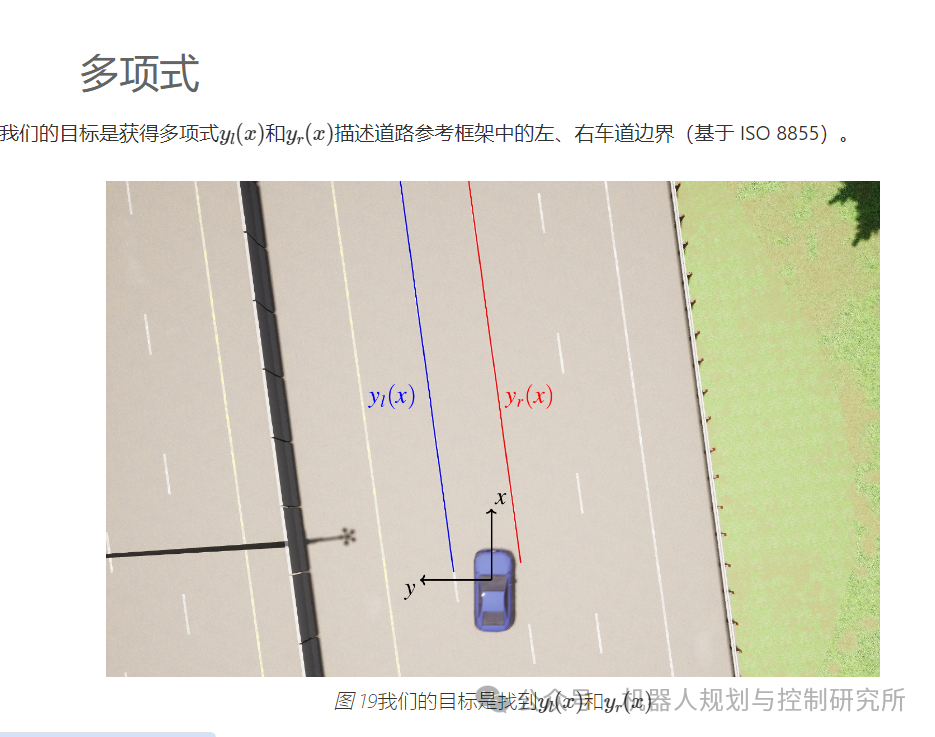
prob_left = np.load("../../data/prob_left.npy")plt.imshow(prob_left, cmap="gray")plt.xlabel("$u$");plt.ylabel("$v$");
上图显示prob_left[v,u]了每个(u,v)。现在想象一下,(u,v,prob_left[v,u])我们不是使用三元组,而是使用三元组(x,y,prob_left(x,y)),其中(𝑥,𝑦)是道路上的坐标,如图19所示。如果我们有这些三元组,我们可以过滤所有较大的(x,y,prob_left[x,y])点prob_left[x,y]。我们将获得一个点列表(𝑥𝑖,𝑦𝑖)它们是左车道边界的一部分,我们可以使用这些点来拟合多项式𝑦𝑙(𝑥)!但从 到(u,v,prob_left[v,u])实际上(x,y,prob_left[x,y])并不难,因为你uv_to_roadXYZ_roadframe_iso8855在上一个练习中实现了该函数。此函数将(𝑢,𝑣)进入(𝑥,𝑦,𝑧)(注意𝑧=0对于道路像素)
这意味着我们可以开始编写一些代码来收集三元组(x,y,prob_left[x,y])
import syssys.path.append('../../code')from solutions.lane_detection.camera_geometry import CameraGeometrycg = CameraGeometry()xyp = []for v in range(cg.image_height):for u in range(cg.image_width):X,Y,Z= cg.uv_to_roadXYZ_roadframe_iso8855(u,v)xyp.append(np.array([X,Y,prob_left[v,u]]))xyp = np.array(xyp)

x_arr, y_arr, p_arr = xyp[:,0], xyp[:,1], xyp[:,2]mask = p_arr > 0.3coeffs = np.polyfit(x_arr[mask], y_arr[mask], deg=3, w=p_arr[mask])polynomial = np.poly1d(coeffs)
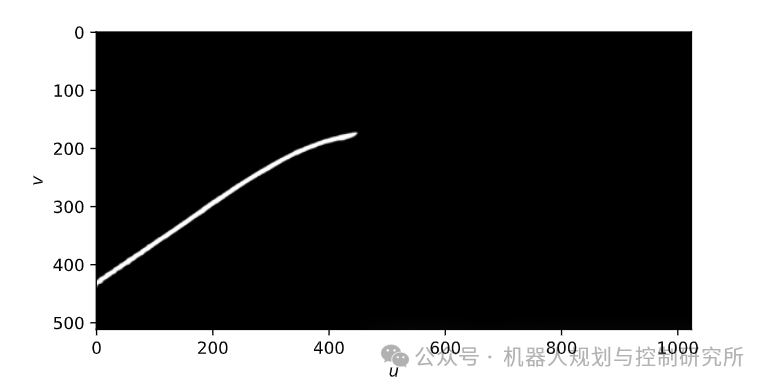
让我们绘制多项式:
x = np.arange(0,60,0.1)y = polynomial(x)plt.plot(x,y)plt.xlabel("x (m)"); plt.ylabel("y (m)"); plt.axis("equal");
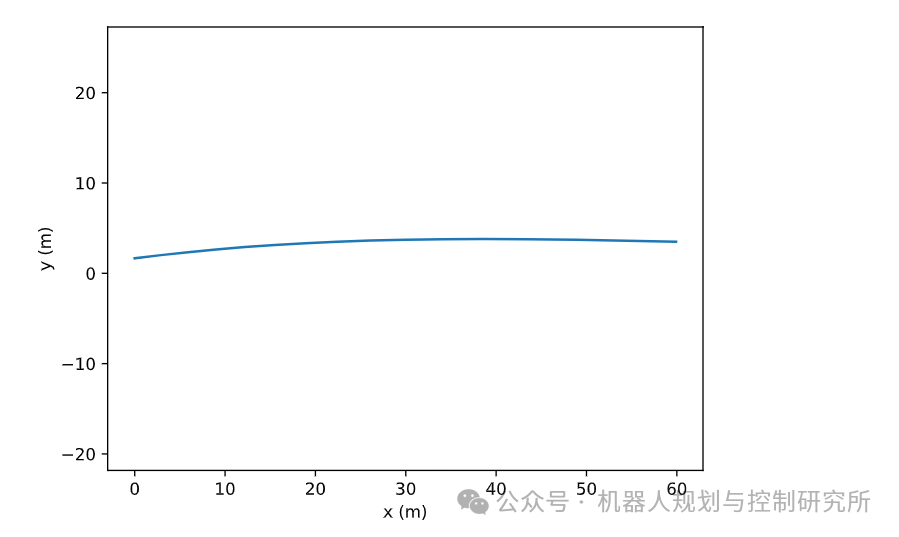
管道封装成一个
您现在已经了解了车道检测流程的两个步骤:车道边界分割和多项式拟合。为了便于将来使用,将整个流程封装到一个类中会很方便。在下面的练习中,您将实现这样一个LaneDetector类。现在,让我们看一下LaneDetector实际操作的示例解决方案。首先,我们加载一个图像
import cv2img_fn = "images/carla_scene.png"img = cv2.imread(img_fn)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)plt.imshow(img);

现在我们导入该类LaneDetector并创建它的一个实例。为此,我们指定使用 pytorch 函数存储的模型的路径save。
from solutions.lane_detection.lane_detector import LaneDetectormodel_path ="../../code/solutions/lane_detection/fastai_model.pth"ld = LaneDetector(model_path=model_path)
从现在开始,我们可以通过将任何图像(与训练集没有太大差别)传递给实例来获取车道边界多项式ld。
poly_left, poly_right = ld(img)
Reference
https://thomasfermi.github.io/Algorithms-for-Automated-Driving/LaneDetection/InversePerspectiveMapping.html