1. 引言
ChatGPT4相比于ChatGPT3.5,有着诸多不可比拟的优势,比如图片生成、图片内容解析、GPTS开发、更智能的语言理解能力等,但是在国内使用GPT4存在网络及充值障碍等问题,如果您对ChatGPT4.0感兴趣,可以私信博主为您解决账号和环境问题。同时,如果您有一些AI技术应用的需要,也欢迎私信博主,我们聊一聊思路和解决方案
近年来,随着自然语言处理(NLP)技术的飞速发展,BERT(Bidirectional Encoder Representations from Transformers)模型因其在多项NLP任务中的卓越表现,受到了广泛关注和应用。BERT通过预训练和微调的方式,极大地提升了文本处理的效果。本文将详细介绍BERT的基本原理,并结合具体案例,探讨BERT在大规模文本处理中的实际应用。
2. BERT模型概述
BERT由Google在2018年提出,是一种基于Transformer架构的双向编码模型。与传统的单向语言模型不同,BERT通过掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)两个任务进行预训练,从而捕捉到上下文的双向信息。
2.1 模型结构
BERT的核心结构是Transformer,主要包括编码器和解码器两部分。BERT仅使用编码器部分,其主要组件包括多头自注意力机制(Multi-head Self-Attention)、前馈神经网络(Feed-Forward Neural Network)和残差连接(Residual Connection)。
2.2 预训练任务
- 掩码语言模型(MLM):随机遮掩输入文本中的一些单词,并要求模型预测这些被遮掩的单词。
- 下一句预测(NSP):判断两个句子是否连续,从而帮助模型理解句子间的关系。
3. BERT在大规模文本处理中的应用
3.1 文本分类
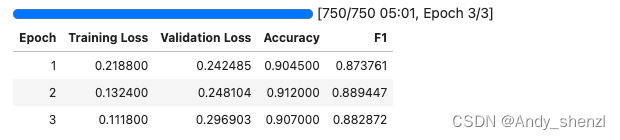
文本分类是BERT的一项重要应用,通过微调BERT,可以实现高精度的文本分类任务。以下是一个使用BERT进行文本分类的代码示例:
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import Trainer, TrainingArguments
# 加载BERT模型和分词器
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=8,
evaluation_strategy="epoch",
logging_dir='./logs',
)
# 训练数据
train_texts = ["I love this!", "This is bad."]
train_labels = [1, 0]
train_encodings = tokenizer(train_texts, truncation=True, padding=True)
train_dataset = Dataset(train_encodings, train_labels)
# 创建Trainer并开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset
)
trainer.train()
3.2 信息检索
信息检索(Information Retrieval, IR)是另一个BERT的重要应用场景,通过BERT的强大语义理解能力,可以大幅提升文档检索的准确性。BERT模型可以将查询和文档编码为向量,计算它们之间的相似度来实现检索。
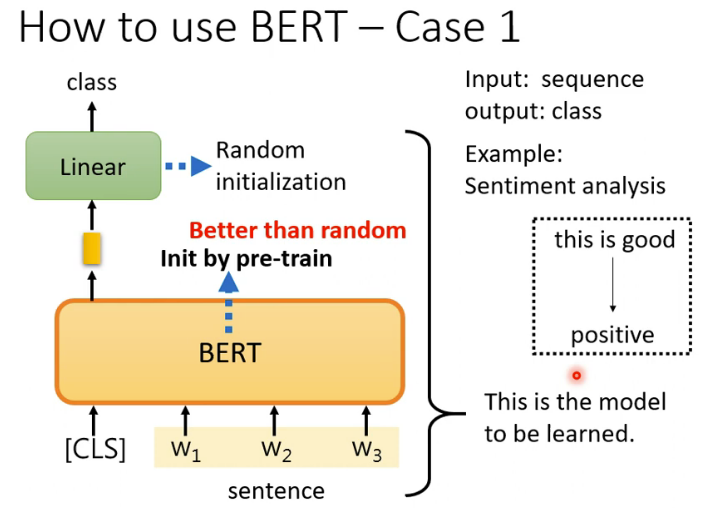
3.3 情感分析
情感分析用于判断文本的情感倾向(正面、负面、中性等)。BERT通过微调,可以精确地分析用户评论、社交媒体帖子等文本的情感。以下是一个使用BERT进行情感分析的示例:
from transformers import pipeline
# 加载预训练模型
sentiment_analysis = pipeline('sentiment-analysis')
# 分析文本情感
result = sentiment_analysis("I love using BERT for sentiment analysis!")
print(result)
3.4 问答系统
BERT在问答系统中的应用也非常广泛,通过微调SQuAD数据集,BERT可以实现高效的问答功能。以下是一个使用BERT进行问答的示例:
from transformers import pipeline
# 加载预训练问答模型
qa_pipeline = pipeline('question-answering')
# 提出问题并给出答案
context = "BERT is a powerful model for NLP tasks."
question = "What is BERT used for?"
result = qa_pipeline(question=question, context=context)
print(result)
3.5 文本生成
尽管BERT主要用于理解任务,但也可以通过变体如GPT-2、GPT-3进行文本生成任务。文本生成在写作辅助、对话生成等方面具有广泛应用。
4. 实战案例:主题模型
使用BERT进行主题模型(Topic Modeling),可以通过BERT生成的文档嵌入向量,使用聚类算法发现文本中的潜在主题。
from bertopic import BERTopic
# 加载文本数据
documents = ["BERT is amazing.", "I love machine learning.", "Natural language processing is fascinating."]
# 创建主题模型
topic_model = BERTopic()
topics, _ = topic_model.fit_transform(documents)
# 打印主题
print(topic_model.get_topic_info())
5. BERT的挑战与未来
尽管BERT在NLP任务中表现出色,但也存在一些挑战,如模型体积大、计算资源需求高等。未来,轻量级模型(如DistilBERT)和改进的预训练方法(如RoBERTa、ALBERT)将继续推动NLP的发展。
6. 结论
BERT作为一种强大的预训练语言模型,已在多项NLP任务中展示了其卓越的性能。通过结合具体案例,我们可以看到BERT在大规模文本处理中的广泛应用前景。随着技术的不断进步,BERT及其变体将在更多的实际场景中发挥更大的作用。