在Bert基础(十五)-- Bert中文文本分类任务中实现了文本分了任务,其中的数据处理、训练过程以及预测都需要自己写代码来实现,其实在hugging face中已经使用transformers库封装好了很多相关的函数可以更加方便的让我们来实现。
1、简介
Hugging Face 的 Transformers 库是一个开源库,它提供了大量预训练的模型,用于自然语言处理(NLP)任务,如文本分类、命名实体识别、机器翻译、问答系统等。这个库的特点是易于使用,支持多种模型架构,包括但不限于 BERT、GPT、RoBERTa、XLNet 等,并且可以轻松地在不同的任务上微调这些模型。
以下是使用 Hugging Face Transformers 库进行情感分类的基本步骤:
2、实战
2.1 加载数据集
首先我们先把数据读取,以本地数据为例:
# 加载数据
file_path = './news.csv'
data = pd.read_csv(file_path)
# 显示数据的前几行
data.head()

数据集还是我们之前使用的数据集
# 使用LabelEncoder将标签转换为数值形式
label_encoder = LabelEncoder()
data["label"] = label_encoder.fit_transform(data["label"])
!pip install datasets
from datasets import Dataset
dataset = Dataset.from_pandas(data)
dataset
Dataset({
features: ['label', 'text'],
num_rows: 1000
})
2.2 数据预处理
首先我们先去除空的行,当然这一步也可以在上一步读取数据时用pandas处理
dataset = dataset.filter(lambda x: x["text"] is not None)
dataset
划分训练集和测试集,主要看读取的数据格式,我们后面会讲到直接远程下载,和使用Dataset里面的包直接读取。
datasets = dataset.train_test_split(test_size=0.2)
datasets
DatasetDict({
train: Dataset({
features: ['label', 'text'],
num_rows: 800
})
test: Dataset({
features: ['label', 'text'],
num_rows: 200
})
})
创建tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
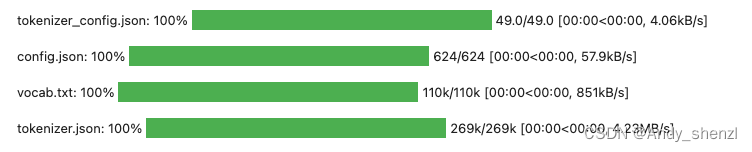
可以直接远程下载,也可以先下载到本地
Bert模型的输入包含四个部分,分别是’input_ids’, ‘token_type_ids’, ‘attention_mask’, ‘labels’,所以我们需要按照这个格式对数据进行返回
# 定义一个处理函数 process_function,它接受一个名为 dicks 的字典
def process_function(dicks):
tokenized_dicks = tokenizer(dicks["text"], max_length=128, truncation=True)
tokenized_dicks["labels"] = dicks["label"]
# 返回 tokenized_examples 字典
return tokenized_dicks
# 使用 datasets 库的 map 函数,将数据集 "train" 的数据应用到 process_function 函数上
# batched=True 表示数据会被批量处理
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
# 打印 tokenized_datasets,即处理后的数据集
tokenized_datasets
首先,process_function 函数的作用是将一个字典(dicks)中的文本数据进行分词和截断,然后添加一个标签字段,并将结果转换为一个字典。在这个字典中,“text” 字段包含分词后的文本,“labels” 字段包含对应的标签。
接着,datasets.map 函数应用 process_function 函数到数据集 “train” 的每一条数据上。batched=True 表示数据会被分成多个批次来处理,这样能够更高效地利用GPU等硬件资源。remove_columns 参数指定在处理数据后需要移除的原始数据集的列名。
最后,tokenized_datasets 变量存储了处理后的数据集,可以进一步用于模型训练等任务。

2.3 创建模型
model = AutoModelForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=10)
需要注意num_labels默认是2 ,需要根据自己的任务进行修改
2.4 创建评估函数
!pip install evaluate
import evaluate
acc_metric = evaluate.load("accuracy")
EvaluationModule(name: “accuracy”, module_type: “metric”, features: {‘predictions’: Value(dtype=‘int32’, id=None), ‘references’: Value(dtype=‘int32’, id=None)}, usage: “”"
Args:
predictions (listofint): Predicted labels.
references (listofint): Ground truth labels.
normalize (boolean): If set to False, returns the number of correctly classified samples. Otherwise, returns the fraction of correctly classified samples. Defaults to True.
sample_weight (listoffloat): Sample weights Defaults to None.
Returns:
accuracy (floatorint): Accuracy score. Minimum possible value is 0. Maximum possible value is 1.0, or the number of examples input, ifnormalizeis set toTrue… A higher score means higher accuracy.
Examples:
Example 1-A simple example
accuracy_metric = evaluate.load(“accuracy”)
results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])
print(results)
{‘accuracy’: 0.5}
Example 2-The same as Example 1, except with
normalizeset toFalse.accuracy_metric = evaluate.load(“accuracy”)
results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], normalize=False)
print(results)
{‘accuracy’: 3.0}
Example 3-The same as Example 1, except with
sample_weightset.accuracy_metric = evaluate.load(“accuracy”)
results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], sample_weight=[0.5, 2, 0.7, 0.5, 9, 0.4])
print(results)
{‘accuracy’: 0.8778625954198473}
“”", stored examples: 0)
我们也可以根据任务需要下载其他的评估函数
def eval_metric(eval_predict):
predictions, labels = eval_predict
predictions = predictions.argmax(axis=-1)
acc = acc_metric.compute(predictions=predictions, references=labels)
return acc
2.5 创建训练器
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=64, # 训练时的batch_size
per_device_eval_batch_size=128, # 验证时的batch_size
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="accuracy", # 设定评估指标
load_best_model_at_end=True, # 训练完成后加载最优模型
report_to=['tensorboard']
)
train_args
TrainingArguments(
_n_gpu=1,
accelerator_config={‘split_batches’: False, ‘dispatch_batches’: None, ‘even_batches’: True, ‘use_seedable_sampler’: True},
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_persistent_workers=False,
dataloader_pin_memory=True,
dataloader_prefetch_factor=None,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=True,
do_predict=False,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=epoch,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={‘min_num_params’: 0, ‘xla’: False, ‘xla_fsdp_v2’: False, ‘xla_fsdp_grad_ckpt’: False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
gradient_checkpointing_kwargs=None,
greater_is_better=True,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
include_num_input_tokens_seen=False,
include_tokens_per_second=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=2e-05,
length_column_name=length,
load_best_model_at_end=True,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=./checkpoints/runs/Apr17_07-22-23_12c3df134e25,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=10,
logging_strategy=steps,
lr_scheduler_kwargs={},
lr_scheduler_type=linear,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=accuracy,
mp_parameters=,
neftune_noise_alpha=None,
no_cuda=False,
num_train_epochs=3.0,
optim=adamw_torch,
optim_args=None,
optim_target_modules=None,
output_dir=./checkpoints,
overwrite_output_dir=False,
past_index=-1,
per_device_eval_batch_size=128,
per_device_train_batch_size=64,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=[‘tensorboard’],
resume_from_checkpoint=None,
run_name=./checkpoints,
save_on_each_node=False,
save_only_model=False,
save_safetensors=True,
save_steps=500,
save_strategy=epoch,
save_total_limit=3,
seed=42,
skip_memory_metrics=True,
split_batches=None,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.01,
)
- output_dir: 指定模型和日志文件输出目录。
- per_device_train_batch_size:
指定每个设备(如每个GPU)上的训练批次大小。 - per_device_eval_batch_size:
指定每个设备(如每个GPU)上的验证批次大小。 - logging_steps: 指定打印日志的频率(以步数为单位)。
- evaluation_strategy: 指定评估的策略,可以选择 ‘steps’ 或 ‘epoch’。
- save_strategy:指定保存检查点的策略,可以选择 ‘steps’ 或 ‘epoch’。
- save_total_limit:指定最多保存的检查点数量,旧的检查点会被覆盖。
- learning_rate: 指定学习率。 weight_decay: 指定权重衰减系数。
- metric_for_best_model: 指定用于选择最佳模型的评估指标。
- load_best_model_at_end:
指定在训练结束后是否加载最佳模型。 report_to: 指定用于报告训练进度和评估结果的监控工具,例如 ‘tensorboard’。
2.6 训练模型
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model,
args=train_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=eval_metric)
- model: 指定用于训练和评估的模型。
- args: 指定训练参数,这些参数通过 train_args 对象传递。
- train_dataset: 指定用于训练的数据集。
- eval_dataset: 指定用于评估的数据集。
- data_collator: 指定用于处理数据集的 DataCollator 对象。在这个例子中,使用了 DataCollatorWithPadding,它会在填充后的每个批次中对齐序列长度。
- compute_metrics: 指定一个函数或列表,用于在评估时计算指标。eval_metric 应该是一个函数,它接受预测结果和实际结果作为输入,并返回一个字典,字典中的键是指标的名称,值是指标的分数。
trainer.train()

2.7 评估
trainer.evaluate(tokenized_datasets["test"])
{'eval_loss': 0.08754459023475647,
'eval_accuracy': 0.98,
'eval_runtime': 0.8151,
'eval_samples_per_second': 245.368,
'eval_steps_per_second': 2.454,
'epoch': 3.0}
2.8 预测
from transformers import pipeline
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
model.config.id2label = id2label_dic
sen = "快船vs火箭首发:休城旨在练兵 小德帕特森进先发新浪体育讯北京时间4月10日消息,在常规赛还剩下三场的时候,火箭已经彻底的失去了进军季后赛的希望。所以今天战快船旨在练兵,再加上洛瑞一直有伤,帕特森和德拉季奇则接替小钢炮和斯科拉首发出场。以下为双方本场比赛的首发阵容:快船:威廉姆斯、戈登、穆恩、格里芬、乔丹火箭:德拉季奇、马丁、巴丁格、帕特森、海耶斯(新体)!"
pipe(sen)
[{'label': '体育', 'score': 0.9791619777679443}]
完整代码:https://github.com/Andyszl/NLP_transformer