前言
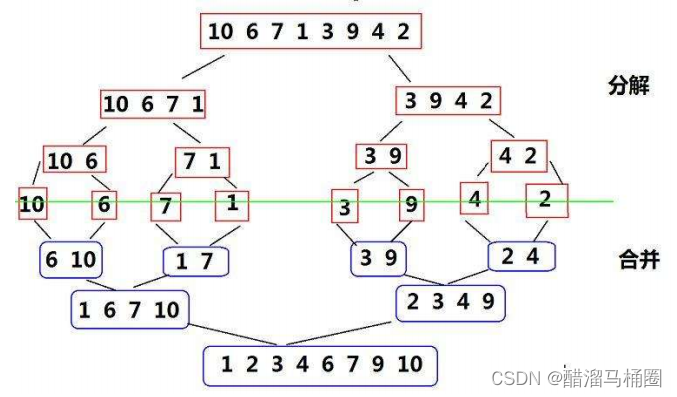
归并排序是一种逻辑很简单,但是实现有点难度的排序,尤其是非递归,对于区间的把握更是需要一点逻辑的推导,但是没有关系,轻松拿捏
归并排序gif

归并排序单趟实现
1,创建tmp数组,
2,递归到最小值进行排序,同时拷贝到题目破数组里面
3,这里的关键逻辑实现是,递归回来的时候进行排序
4,最后我们把数值重新拷贝回去原数组
注意:这里的取值我们直接取中间值进行递归,一分为二
代码实现注意事项
关于创建tmp数组,我们需要创建的数组应该是等大的,要么就进行初始化。
- 因为我们是malloc出来的空间,
- 为什么malloc出来的空间必须是等大的,因为这里我们用的是Visual Studio 2022的编译器,这个编译器里面是不支持可变长数组的。所以我们需要用malloc,或者realloc来实现创建空间,也就是动态内存的分配
- malloc创建空间的时候,空间里面是有随机值的
- realloc创建的空间里面的数值是0
- 所以一旦我们进行排序的时候,如果我们不进行覆盖的话,这里面的数值也会参与排序,从而导致数值出现偏差
这里对于这一点不清楚的可以看看之前写的文章,因为当时写这个文章的时候,刚接触编程,所以讲述的主要是以语法和一些简单的性质特点,希望可以起到帮助
代码实现
//归并排序(递归实现)子函数(实现函数) void _MergeSort01(int* a, int* tmp, int begin, int end) { if (begin >= end) return; int mini = (begin + end) / 2; //注意,这里关键在于,区间的传递, //不应该传递【left,mini-1】【mini,right】 // 应该传递【left,mini】【mini+1,right】 //递归左右区间, 递归到最小个数进行对比 _MergeSort01(a, tmp, begin, mini); _MergeSort01(a, tmp, mini + 1, end); int begin1 = begin, end1 = mini; int begin2 = mini + 1, end2 = end; int i = begin; while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] < a[begin2]) { tmp[i++] = a[begin1++]; } else { tmp[i++] = a[begin2++]; } } while (begin1 <= end1) { tmp[i++] = a[begin1++]; } while (begin2 <= end2) { tmp[i++] = a[begin2++]; } //数据从tmp拷贝回去数组a里面 memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int)); } //归并排序(递归实现)(创建tmp函数) void MergeSort01(int* a, int n) { //这里n传递过来的是个数 int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("MergeSort01:tmp:err:"); exit(1);//正常退出 } _MergeSort01(a, tmp, 0, n - 1); free(tmp); tmp = NULL; }解释:
_MergeSort01 函数:这是归并排序的递归子函数,它接收三个参数:数组
a,临时数组tmp,以及要排序的数组区间[begin, end]。
- 如果
begin大于或等于end,则表示区间内没有元素或只有一个元素,不需要排序,直接返回。- 计算区间的中点
mini,将数组分为两部分:[begin, mini]和[mini + 1, end]。- 对这两部分分别递归调用
_MergeSort01函数进行排序,直到每个子区间只有一个元素。合并过程:
- 初始化两个指针
begin1和end1指向第一个子区间的开始和结束位置,begin2和end2指向第二个子区间的开始和结束位置。- 使用一个索引
i指向tmp数组的当前位置,用于存放合并后的有序元素。- 使用两个
while循环来比较两个子区间的元素,将较小的元素复制到tmp数组中,并移动对应的指针。- 如果第一个子区间的所有元素已经被复制到
tmp中,但第二个子区间还有剩余元素,将这些剩余元素复制到tmp数组的剩余位置。- 同理,如果第二个子区间的所有元素已经被复制,将第一个子区间的剩余元素复制到
tmp。拷贝回原数组:
- 使用
memcpy函数将tmp数组中从索引begin开始的元素复制回原数组a。这里计算了需要复制的元素数量为end - begin + 1,乘以sizeof(int)来确定字节数。MergeSort01 函数:这是归并排序的初始化函数,接收数组
a和数组的长度n。
- 首先,使用
malloc分配一个临时数组tmp,大小为n个int。- 如果内存分配失败,使用
perror打印错误信息,并调用exit(1)退出程序。- 调用
_MergeSort01函数,传入数组a、临时数组tmp和整个数组的区间[0, n - 1]进行排序。- 排序完成后,使用
free释放tmp所占用的内存,并设置tmp为NULL。归并排序的时间复杂度为 O(n log n),在大多数情况下表现良好,尤其是当数据量大且需要稳定排序时。不过,由于它需要额外的内存空间(如这里的
tmp数组),在内存受限的情况下可能不是最佳选择。
递归排序(非递归解决)
前言
这里递归排序的非递归方式还是比较有难度的,所以需要多次观看两遍,我也会多次详细的讲解,促进知识的理解
非递归实现gif

非递归实现单趟实现
这里的关键的在于对于区间的理解
尤其是
//但是此时可能产生越界行为,我们可以打印出来看一下
//产生越界的
//begin1, end1, begin2, end2 -> end2->[,][,15]
//begin1, end1, begin2, end2 -> begin2, end2->[,][12,15]
//begin1, end1, begin2, end2 -> end1, begin2, end2->[,11][12,15]
//解决
//begin2, end2区间越界的,我们直接下一次进行递归就可以
//end2,我们重新设定新的end2的区间所以我们需要对这个区间进行解决

代码的逐步实现
这里代码的实现,因为非递归实现是有难度的,所以这里我不会直接给出答案,而是逐步的写出步骤,促进理解
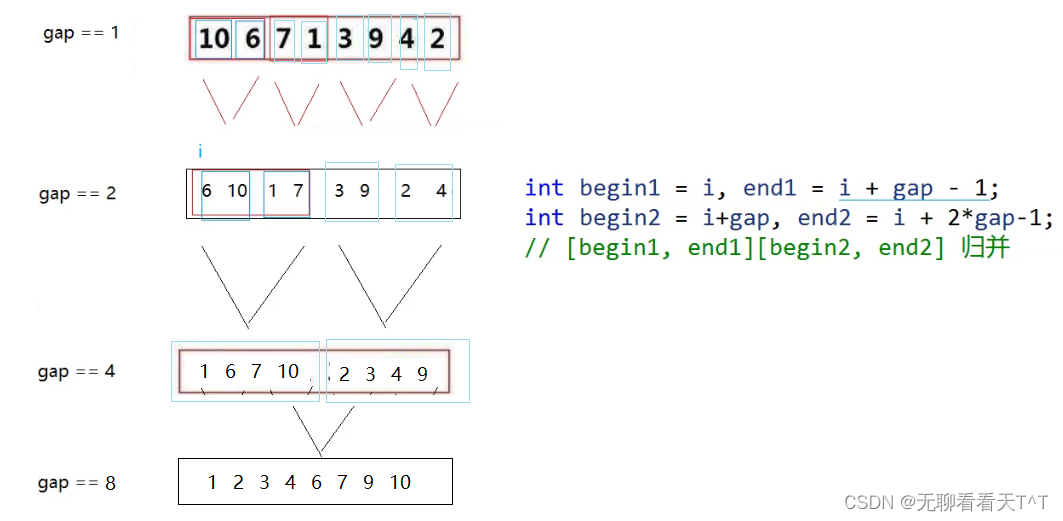
1,创建拷贝空间tmp,设定gap,一组假设初始1个数值,当然初始的时候,实际也是一个数值
//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) { //这里n传递过来的是个数 int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("MergeSort01:tmp:err:"); exit(1);//正常退出 } //假设初始化起始是一组 int gap = 1; }2,区间的设定
这里依旧是两个区间,我们根据这个区间设定的数值
这里是很关键的一点
int begin1 = 0, end1 = 0 + gap - 1;
int begin2 = 0 + gap, end2 = 0 + 2 * gap - 1;//假设此时就两个数值,一组是一个数值,也就是这两个数值进行最小对比
//begin1左区间的初始位置,肯定是0
//end1左区间的结束位置。
- 也就是第一个区间的结束位置,也就是一组,
- -1是因为一组是实际的个数
- +0,这里因为加的是第一个区间起始位置
- 因为我们也可能是2-4区间的,不可能只是这一个区间
//begin2第二个区间的起始位置,这里还是比较好理解的,只要理解了end1
//end2第二个区间的结束位置,这里同理,
- 我们有可能是2-4区间的,不只是0-1或者0-2区间的。而且随着第一次排序的结束,第二次排序就变成两个合并了,继续和另外的对比,所以是变化的
- 0也就是初始位置
- 2*gap,因为这里是需要加上中间两组,
- 最后-1,因为gap是个数,不是下标
//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) { //这里n传递过来的是个数 int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("MergeSort01:tmp:err:"); exit(1);//正常退出 } //假设初始化起始是一组 int gap = 1; int begin1 = 0, end1 = 0 + gap - 1; int begin2 = 0 + gap, end2 = 0 + 2 * gap - 1; }3,排序的实现
//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) { //这里n传递过来的是个数 int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("MergeSort01:tmp:err:"); exit(1);//正常退出 } //假设初始化起始是一组 int gap = 1; while (gap < n) { //递归到最小值,假设一组是一个,也就是此时是最小值进行比较并且入数组,关键是找出区间 //这里一次跳过两组 for (int i = 0; i < n - 1; i = i + gap * 2) { int begin1 = i, end1 = i + gap - 1; int begin2 = i + gap, end2 = i + 2 * gap - 1; int j = i; while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] < a[begin2]) { tmp[j++] = a[begin1++]; } else { tmp[j++] = a[begin2++]; } } while (begin1 <= end1) { tmp[j++] = a[begin1++]; } while (begin2 <= end2) { tmp[j++] = a[begin2++]; } } gap *= 2; } }4,区间的拷贝
这里区间的拷贝我们需要注意的是我们拷贝的是区间,并且我们需要一边拷贝一边拷贝回去,为什么需要一边排序一边拷贝回去,在接下来的越界行为里面我们会进行讲解
最后需要关注的点是,关于拷贝空间的大小,一定是end2-begin1,因为这两个区间是排序成功然后进入到tmp里面
所以我们需要从tmp拷贝回去,不能弄错了
//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) { //这里n传递过来的是个数 int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("MergeSort01:tmp:err:"); exit(1);//正常退出 } //假设初始化起始是一组 int gap = 1; while (gap < n) { //递归到最小值,假设一组是一个,也就是此时是最小值进行比较并且入数组,关键是找出区间 //这里一次跳过两组 for (int i = 0; i < n - 1; i = i + gap * 2) { int begin1 = i, end1 = i + gap - 1; int begin2 = i + gap, end2 = i + 2 * gap - 1; int j = i; while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] < a[begin2]) { tmp[j++] = a[begin1++]; } else { tmp[j++] = a[begin2++]; } } while (begin1 <= end1) { tmp[j++] = a[begin1++]; } while (begin2 <= end2) { tmp[j++] = a[begin2++]; } //拷贝回a数组里面,这里的区间是end2-begin1之间的区间 memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1)); } gap *= 2; } }5,解决越界行为
这里我们可以很清楚的看到哪些位置会产生越界行为
这里我们处理一下之后,我们发现就解决了
//产生越界的区间有
//begin1, end1, begin2, end2 -> end2->[,][,15]
//begin1, end1, begin2, end2 -> begin2, end2->[,][12,15]
//begin1, end1, begin2, end2 -> end1, begin2, end2->[,11][12,15]
//解决
//begin2, end2区间越界的,我们直接下一次进行递归就可以
//end2,我们重新设定新的end2的区间//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) { //这里n传递过来的是个数 int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("MergeSort01:tmp:err:"); exit(1);//正常退出 } //假设初始化起始是一组 int gap = 1; while (gap < n) { //递归到最小值,假设一组是一个,也就是此时是最小值进行比较并且入数组,关键是找出区间 //这里一次跳过两组 for (int i = 0; i < n - 1; i = i + gap * 2) { int begin1 = i, end1 = i + gap - 1; int begin2 = i + gap, end2 = i + 2 * gap - 1; //但是此时可能产生越界行为,我们可以打印出来看一下 //产生越界的 //begin1, end1, begin2, end2 -> end2->[,][,15] //begin1, end1, begin2, end2 -> begin2, end2->[,][12,15] //begin1, end1, begin2, end2 -> end1, begin2, end2->[,11][12,15] //解决 //begin2, end2区间越界的,我们直接下一次进行递归就可以 //end2,我们重新设定新的end2的区间 printf("[begin1=%d,end1=%d][begin2=%d,end2=%d]\n", begin1, end1, begin2, end2); if (begin2 > n) { break; } if (end2 > n) { //记得这里需要是n-1不能是n,因为end2是下标 end2 = n-1; } int j = i; while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] < a[begin2]) { tmp[j++] = a[begin1++]; } else { tmp[j++] = a[begin2++]; } } while (begin1 <= end1) { tmp[j++] = a[begin1++]; } while (begin2 <= end2) { tmp[j++] = a[begin2++]; } //拷贝回a数组里面,这里的区间是end2-begin1之间的区间 memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1)); } gap *= 2; } }


时间复杂度
时间复杂度分析如下:
分解阶段:归并排序首先将原始数组分解成多个子数组,每个子数组的大小为1。这个过程是线性的,时间复杂度为 O(n),其中 n 是原始数组的大小。
合并阶段:在合并阶段,算法将这些有序的子数组逐步合并成更大的有序数组。每次合并操作都需要将两个有序数组合并成一个更大的有序数组,这个过程的时间复杂度是 O(n)。
重复合并:归并排序的合并阶段会重复进行,直到所有的元素都被合并成一个有序数组。合并的次数可以看作是对数级的,具体来说,是 log2(n) 次。
综合以上两点,归并排序的总时间复杂度主要由合并阶段决定,因为分解阶段是线性的,而合并阶段虽然每次都是线性的,但由于重复了对数级次数,所以总的时间复杂度是:
𝑂(𝑛)+𝑂(𝑛log𝑛)
由于在大 O 符号中,我们只关注最高次项和系数,所以归并排序的时间复杂度通常被简化为:𝑂(𝑛log𝑛)
这意味着归并排序的时间效率与数组的大小成对数关系,是相当高效的排序算法。此外,归并排序是一种稳定的排序算法,它保持了相等元素的原始顺序。然而,它需要与原始数组同样大小的额外空间来存储临时数组,这可能会在空间受限的情况下成为一个问题。
代码实现
//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) { //这里n传递过来的是个数 int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("MergeSort01:tmp:err:"); exit(1);//正常退出 } //假设初始化起始是一组 int gap = 1; while (gap < n) { //递归到最小值,假设一组是一个,也就是此时是最小值进行比较并且入数组,关键是找出区间 //这里一次跳过两组 for (int i = 0; i < n - 1; i = i + gap * 2) { int begin1 = i, end1 = i + gap - 1; int begin2 = i + gap, end2 = i + 2 * gap - 1; //但是此时可能产生越界行为,我们可以打印出来看一下 //产生越界的 //begin1, end1, begin2, end2 -> end2->[,][,15] //begin1, end1, begin2, end2 -> begin2, end2->[,][12,15] //begin1, end1, begin2, end2 -> end1, begin2, end2->[,11][12,15] //解决 //begin2, end2区间越界的,我们直接下一次进行递归就可以 //end2,我们重新设定新的end2的区间 printf("[begin1=%d,end1=%d][begin2=%d,end2=%d]\n", begin1, end1, begin2, end2); if (begin2 > n) { break; } if (end2 > n) { //记得这里需要是n-1不能是n,因为end2是下标 end2 = n-1; } int j = i; while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] < a[begin2]) { tmp[j++] = a[begin1++]; } else { tmp[j++] = a[begin2++]; } } while (begin1 <= end1) { tmp[j++] = a[begin1++]; } while (begin2 <= end2) { tmp[j++] = a[begin2++]; } //拷贝回a数组里面,这里的区间是end2-begin1之间的区间 memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1)); } gap *= 2; } }解释:
内存分配:首先,函数使用
malloc分配一个与原数组a同样大小的临时数组tmp。如果内存分配失败,使用perror打印错误信息,并调用exit退出程序。初始化间隔:
gap变量初始化为 1,表示每个元素自身作为一个有序的子数组。外层循环:使用
while循环来逐步增加gap的值,每次迭代将gap乘以 2。这个循环继续进行,直到gap大于或等于数组的长度n。内层循环:对于每个
gap值,使用for循环遍历数组,计算每次合并操作的起始索引i。每次迭代,i增加gap * 2,以确保每次处理的子数组间隔是gap。计算子数组边界:在每次迭代中,计算两个子数组的起始和结束索引:
begin1、end1和begin2、end2。这两个子数组的间隔是gap。处理数组越界:如果
begin2大于数组长度n,循环将终止。如果end2超出了数组的界限,将其调整为n-1。合并子数组:使用
while循环来合并两个子数组。比较a[begin1]和a[begin2],将较小的元素复制到tmp数组中,并相应地移动索引。当一个子数组的所有元素都被复制后,使用另外两个while循环复制剩余子数组中的元素。拷贝回原数组:使用
memcpy将tmp中的有序子数组复制回原数组a。这里,拷贝的区间是从索引i到end2,拷贝的元素数量是end2 - i + 1。更新间隔:外层循环的
gap每次迭代后翻倍,这样在每次迭代中,处理的子数组的大小逐渐增加,直到整个数组被排序。非递归的归并排序在某些情况下可能比递归版本更有效,因为它避免了递归调用的开销,尤其是在深度很大的递归树中。然而,它需要更多的迭代来逐步构建有序数组,因此在实际应用中,选择哪种实现取决于具体的需求和场景。