聚类分析(Cluster Analysis)是一种无监督机器学习方法,主要用于数据挖掘和数据分析中,它的目标是将一组对象或观测值根据它们之间的相似性或相关性自动分组,形成不同的簇或类别。聚类分析并不预先知道每个观测值的具体标签,而是基于数据本身的内在结构进行分组。
聚类过程主要包括以下几个步骤:
- 选择算法:常见的聚类算法有K-means、层次聚类(如凝聚层次聚类和分裂层次聚类)、DBSCAN、谱聚类等。
- 初始化:确定初始聚类中心或簇的数量。
- 迭代:根据所选算法,计算每个观测值与当前簇中心的距离,将其分配到最接近的簇;然后更新簇的中心点。
- 评估:根据簇内的相似性和簇间的差异性(如轮廓系数、Calinski-Harabasz指数等)评估聚类效果。
- 停止条件:当满足预定的停止标准(如达到预设的迭代次数或聚类不再变化)时,结束聚类过程。
在Python中,有许多库支持聚类分析,其中最常用的是scikit-learn。
scikit-learn中的主要模块cluster提供了多种聚类算法,如:
- K-Means:这是一种基于距离的聚类算法,通过迭代将数据点分配到最近的质心形成的簇中。
- 层次聚类(Hierarchical Clustering):包括凝聚式(自下而上合并)和分裂式(自上而下分裂)两种方法,如单链接、全连接、平均链接和 ward 方法。
- DBSCAN:密度聚类算法,能识别任意形状的簇,并对噪声有很好的处理能力。
- 谱聚类(Spectral Clustering):利用数据的特征图(如拉普拉斯矩阵)进行聚类,适用于非凸形状的簇和高维数据。
- GMM(高斯混合模型):一种概率模型,常用于生成模型和混合分布的聚类。
这里我们主要运用K-Means:
K均值聚类是一种常用的无监督机器学习算法,用于数据分群。它的目标是将一组对象(通常称为数据点)划分为K个互不重叠的类别,每个类别由一个中心点(聚类中心)代表,目的是最小化所有数据点与其所属聚类中心的距离之和,通常采用欧几里得距离作为度量。
下面是K均值聚类的主要步骤:
- 选择K值:确定要创建的聚类数量K。
- 初始化聚类中心:随机从数据集中选择K个点作为初始聚类中心。
- 分配数据点:每个数据点被分配到最近的聚类中心。
- 更新聚类中心:根据当前分配的数据点计算每个聚类的新中心。
- 迭代过程:重复步骤3和4,直到聚类中心不再改变,或达到预设的最大迭代次数。
1、读取NBA球员数据:players.csv。
# 读取球员数据
import pandas as pd
players = pd.read_csv('players.csv')
players.head()查看数据形式:

2、提取得分、命中率、三分命中率和罚球命中率4个指标作为球员聚类的依据,并对指标数据进行标准化。
# 数据标准化处理
from sklearn import preprocessing
X = preprocessing.minmax_scale(players[['得分','罚球命中率','命中率','三分命中率']])
# 将数组转换为数据框
X = pd.DataFrame(X, columns=['得分','罚球命中率','命中率','三分命中率'])
# 绘制得分与命中率的散点图
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #指定默认字体
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
sns.lmplot(x = '得分', y = '命中率', data = players,
fit_reg = False, scatter_kws = {'alpha':0.8, 'color': 'steelblue'})
plt.show()

3、绘制簇内离差平方和与K的关系图,使用拐点法确定合适的K值(参考:K可以取3、4、5之一)。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
#构造自定义函数————用于绘制不同k值和对应总的簇类离差平方和的折线图
def k_SSE(X,clusters):
K = range(1,clusters+1) #选择连续的k种不同的值
TSSE = [] #构建空列表用于存储总的簇内离差平方和
for k in K:
SSE = [] #用于存储各个簇内离差平方和
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
labels = kmeans.labels_ #返回簇标签
centers = kmeans.cluster_centers_ #返回簇中心
#计算各簇样本的离差平方和,并保存到列表中
for label in set(labels):
SSE.append(np.sum((X.loc[labels == label,]-centers[label,:])**2))
TSSE.append(np.sum(SSE)) #计算总的簇内离差平方和
#中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
#设置绘图风格
plt.style.use('ggplot')
# 绘制 K 的个数与 GSSE 的关系
plt.plot(K, TSSE, 'b*-')
plt.xlabel('簇的个数')
plt.ylabel('簇内离差平方和之和')
# 显示图形
plt.show()
# 使用拐点法选择最佳的 K 值
k_SSE(X, 15)
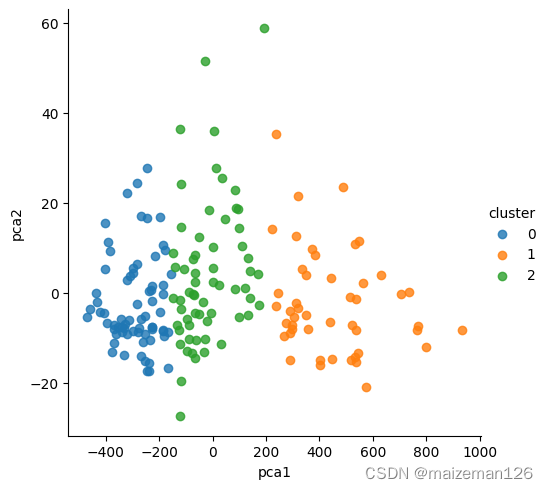
4、取合适的K值,使用得分与命中率两个指标绘制聚类效果图。
# 将球员数据集聚为 3 类
kmeans = KMeans(n_clusters = 3)
kmeans.fit(X)
# 将聚类结果标签插入到数据集 players 中
players['cluster'] = kmeans.labels_
# 构建空列表,用于存储三个簇的簇中心
centers = []
for i in players.cluster.unique():
centers.append(players.loc[players.cluster == i,
['得分','罚球命中率','命中率','三分命中率']].mean())
# 将列表转换为数组,便于后面的索引取数
centers = np.array(centers)
# 绘制散点图
sns.lmplot(x = '得分', y = '命中率', hue = 'cluster',data = players,
markers = ['^','s','o'],fit_reg = False,
scatter_kws = {'alpha':0.8},legend = False)
# 添加簇中心
plt.scatter(centers[:,0], centers[:,2], c='k', marker = '*', s = 180)
plt.xlabel('得分')
plt.ylabel('命中率')
# 图形显示
plt.show()

5、绘制雷达图。
(提示:雷达图要在操作系统下打开)
# 雷达图
import pygal
# 调用模型计算出来的簇中心
centers_std = kmeans.cluster_centers_
# 设置填充型雷达图
radar_chart = pygal.Radar(fill = True)
# 添加雷达图各顶点的名称
radar_chart.x_labels = ['得分','罚球命中率','命中率','三分命中率']
# 绘制雷达图代表三个簇中心的指标值
radar_chart.add('C1', centers_std[0])
radar_chart.add('C2', centers_std[1])
radar_chart.add('C3', centers_std[2])
# 保存图像
radar_chart.render_to_file('radar_chart.svg')




















![[算法刷题积累] 两数之和以及进阶引用](https://img-blog.csdnimg.cn/direct/bcc43681d44649e79c40c2666aab76a7.png)