摘要
假新闻检测在社会取证领域引起了广泛的研究兴趣。许多现有的方法引入了定制的注意机制来融合单峰特征。然而,它们忽略了模式之间的跨模式相似性的影响。同时,预训练的多模式特征学习模型在FND中的潜力还没有得到很好的开发。这篇论文提出了一种FND-CLIP框架,即基于对比语言图像预训练(CLIP)的多模式假新闻检测网络。FND-CLIP使用两个单峰编码器和两个成对的CLIP编码器一起从新闻中提取深层表示。CLIP 生成的多模态特征通过两种模态的 CLIP 相似性进行加权。 我们还引入了模态注意力模块来聚合特征。 进行了大量的实验,结果表明所提出的框架在挖掘假新闻检测的关键特征方面具有更好的能力。 所提出的 FND-CLIP 在三个典型的假新闻数据集上可以取得比之前的作品更好的性能。
索引术语:虚假新闻检测,多模态学习,CLIP,多模态融合
步骤:
- 使用预训练模型提取单模态特征(eg.,ResNet50,ViT,Transformer,BERT(对于长句子使用t2模型提取摘要) etc.)
- 使用CLIP模型测量跨模态的相似性(CLP)
- 使用轻量级网络实现分类(线性层)
Introduction
使用机器学习的假新闻检测(FND)是检测假新闻广泛传播的有效方法,可以帮助读者识别偏见和错误信息并消除负面传播。 假新闻检测的早期工作侧重于分析纯文本或纯图像内容[1],并在单模态假新闻检测上表现出了良好的性能。 然而,现代新闻和帖子包含丰富的信息,例如同时包含文本和图像。 在一些假新闻中,真实图像可能与完全捏造的谣言结合在一起,并且可能使用正确的词语来描述经过篡改的图像。在这些情况下,单峰 FND 方法不足以发现不同模式之间的相关性。
近年来,许多工作通过聚合多模态特征来检测新闻和帖子中的异常[2]-[4]。 研究人员更喜欢使用各种来源的特征,例如文本、图像、评论、点赞率,甚至传播图表,来评估帖子的真实性。 然而,这些附加方式并不总是同时可用。 因此,我们只关注仅具有文本和图像模式的 FND [3]、[5]、[6]。

据悉,多地已出现用残疾骆驼乞讨的情况。 前几天我也在广州见过面。 为了博取同情而伤害动物是可恶的。
预测: Fake
标准化相似度: 0.852
我没事,但是我的心好痛……
预测: Fake
标准化相似度: 0.308
图 1. 在微博数据集上使用 FND-CLIP 进行假新闻检测的示例。 模态之间的相关性与新闻的真实性没有直接关系,但相似性可以指导使用图像和文本模态的决策。
多模式 FND 涉及分析新闻帖子的文本和视觉内容。 然而,这些模态并不总是强相关,并且并非每种模态都包含可用于检测的有效信息。 这对开发有效的 FND 方法提出了重大挑战。 图 1 显示了微博数据集中的两个帖子示例。 第一篇帖子的文本和图像相关,而第二篇帖子的文本包含的事件信息很少,文本和图像之间的相关性较弱。 这种弱相关性会对多模态融合期间网络的性能产生负面影响。 陈等人。 [4]提出了一种通过计算相关性并生成融合特征来解决这个问题的方法。 他们训练了一个变分自动编码器来压缩图像和文本,并对比学习如何最小化具有正确图像文本对的新闻的 Kullback-Leibler 散度。 然后使用跨模态模糊度分数来重新加权多模态特征。 该方法在多模态检测中取得了良好的性能。 然而,仍有几个悬而未决的问题需要解决。 例如,目前尚不清楚如何准确计算不同模态特征的相似性以及它如何影响 FND 中的决策过程。
这项工作的主要贡献可以总结如下:1)我们提出了FND-CLIP,一种多模态假新闻检测模型。 我们采用基于 CLIP 的学习方法来提取语义信息并显式测量文本和图像之间的相关性,并将其用作权重参数。 2)我们提出了一种动态调整单峰和融合特征的使用的方法。 具体来说,我们引入了一个注意力层,它自适应地输出通道分数来测量每种模态的重要性这里重点看一下如何平衡每个模态的重要性的,还有它的做法是否涉及到上面阐述的Point1 和Point2?并相应地调整其使用。 3)在三个著名数据集上的实验表明,FND-CLIP 优于最先进的方法。 实验结果分析说明了我们方法的优点和周到性。
Related Work
虚假新闻检测
人们提出了几种方法来从 FND 新闻文章的图像和文本中提取有价值的特征。 该领域的早期方法侧重于为多模态特征融合设计先进的黑盒注意力机制[8]。 其中一些方法建议在将不同模态提取的特征输入分类器之前更好地对齐它们。 这是通过使用辅助任务来完成的,例如 EANN [3] 中的事件分类、MVAE [2] 中基于变分自动编码器的表示或 CAFE [4] 中的相关计算。 辛格哈尔等人[9]提出了Spotfake,它采用VGG和BERT来提取特征,然后进一步完善了Spotfake+ [5]中的方法来检测长篇文章中的假新闻。 SAFE [10] 计算新闻文章中文本和视觉信息之间的相关性。 LIIMR [11] 抑制来自较弱模态的信息,并在每个样本的基础上从强模态中提取相关信息。 MCAN [12]堆叠多个共同关注层来融合多模态特征。
有些方法不只关注网络设计,而是利用数据集中的更多信息。 例如,齐等人 [13] 认为图像特征提取器无法理解图像中的视觉实体,例如名人、地标和文本。 因此,他们手动提取此类信息作为语言辅助。 阿莱因等人 [14]提出了 DistilBert,它利用新闻文章和用户生成内容的潜在表示来指导模型学习。 舒等人 [15]提出了 dEFEND,它具有一个句子评论共同注意子网络,利用新闻内容和用户评论来联合检测假新闻。 韩等人[16]提出了 GNNCL,它利用 GNN 来区分社交媒体上假新闻和真实新闻的传播模式。
尽管这些方法在多模态 FND 中取得了不错的性能,但在明确测量图像和文本之间的相关性以及有效且高效地利用不同模态做出决策方面仍然存在挑战。
多模态学习
多模态机器学习在过去十年中引起了广泛关注[17]。 在多模态任务中,使用不同模态的先验和特征至关重要,仅具有单模态的算法或深度网络是无效的。 已经开发了几种通用技术来学习图像内容和自然语言的联合表示。 例如,CLIP 模型 [7] 充当计算机视觉和自然语言处理之间的桥梁。 它接受了一组不同的图像-文本对的训练,以预测给定图像的最相关的文本片段,而不直接针对任务进行优化。 CLIP 可以识别最相似的配对图像和文本以匹配图像文本对。 尽管基于 CLIP 的多模态学习已应用于各种下游任务 [18]、[19],但其在 FND 中的应用尚未被探索。
PROPOSED METHOD
方法概述
对于多模态 FND,我们重点关注同时包含文本和图像的样本。 设每个样本为 X = ( X T x t , X I m a g ) X = (X_{Txt},X_{Imag}) X=(XTxt,XImag)。将真实标签表示为 y y y。当 y = 0 y=0 y=0时, x x x为真新闻,否则为假新闻。首先从$ x_{Txt}$ 和 x I m g x_{Img} xImg 中提取丰富的特征集。然后将这些特征融合并投影为 y ^ \hat{y} y^的单个值,即real或者fake。

该过程如(1)所示,其中 F T x t F_{Txt} FTxt 和 F I m g F_{Img} FImg是单峰特征提取器, F M i x F_{Mix} FMix 是特征融合模型, F c l s F_{cls} Fcls 是分类头。
我们提出了一种简单而有效的方法,而不是应用复杂的黑盒特征融合网络。 我们使用预训练网络提取单模态特征,然后使用 CLIP 模型来测量跨模态相似性。在特征提取和对齐之后,我们使用轻量级网络来实现预测 y ^ \hat{y} y^的 L c l s L_{cls} Lcls。
网络规格

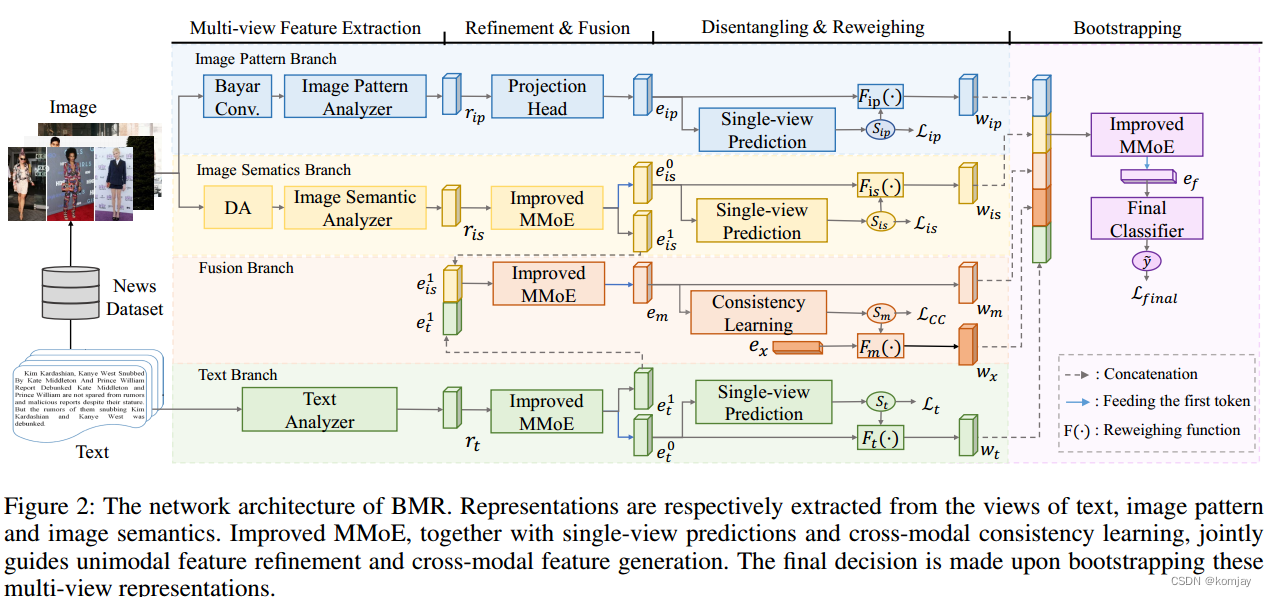
图2:所提出的 FND-CLIP 方法的架构。 CLIP、BERT和ResNet用于提取多模态新闻不同模态的特征。 通过投影头获得不同级别的编码特征。 计算 CLIP 相似度分数以确定融合特征的重要性。 进一步 ,使用模态注意机制来自适应地重新加权不同模态特征,以便分类器对假新闻进行分类。(红色标注的是需要注意的部分)
图 2 说明了所提出的 FND-CLIP 的网络架构。 整个流程由三个阶段组成,即特征提取、CLIP引导的特征生成和聚合以及分类。
单模态特征生成
我们使用预训练的 BERT 模型来提取来自于 X T x t X_{Txt} XTxt的特征 f B E R T \mathcal{f}_{BERT} fBERT。我们也是使用 ResNet [20] 从图像$ x_{Img }$中获取深度表示 f R e s N e t f_{ResNet} fResNet。 同时,我们使用CLIP对文本和图像进行编码并获取特征 f C L I P − T f_{CLIP-T} fCLIP−T和 f C L I P − I f_{CLIP-I} fCLIP−I。对于每个分支,我们将从不同编码器提取的特征连接起来以增强单峰表示。

CLIP引导的特征生成
由于提取的文本特征 f C L I P − T f_{CLIP-T} fCLIP−T和图像特征 f C L I P − I f_{CLIP-I} fCLIP−I具有显着的跨模态语义差距,网络很难学习它们内在的语义相关性。因此,然后将这两个特征连接起来:
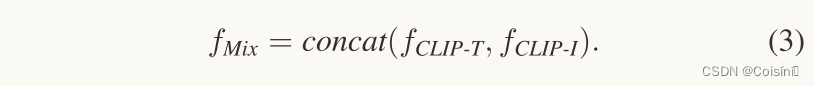
这句话可以用到论文中:多模态特征是单模态特征的补充,用于增强单模态特征的语义表示。
多模态特征是单模态特征的补充,用于增强单模态特征的语义表示。以前的工作经常使用单个网络来挖掘一种模态的粗略特征和精细特征。相对地,我们使用 CLIP、BERT 和 ResNet 三种预训练模型来完成单模态任务。CLIP 使用大规模图像文本对来学习语义提取,从而消除了情感、噪声和其他与图像和文本匹配无关的特征。当它与单模态特征相结合时,我们可以更好地从不同方面对新闻进行审查。
接下来,我们使用单独的投影头分别调整尺寸并去除冗余信息。 图2中有3个投影头,分别是 P T x t P_{Txt} PTxt、 P I m g P_{Img} PImg和 P M i x P_{Mix} PMix。 每个投影头包含两组全连接层,其中包括 BatchNorm 层、ReLU 激活函数和 dropout 层。 投影头具有相同的架构,但权重不同。
[下面作者讨论的是为什么不只是用CLIP的特征融合]
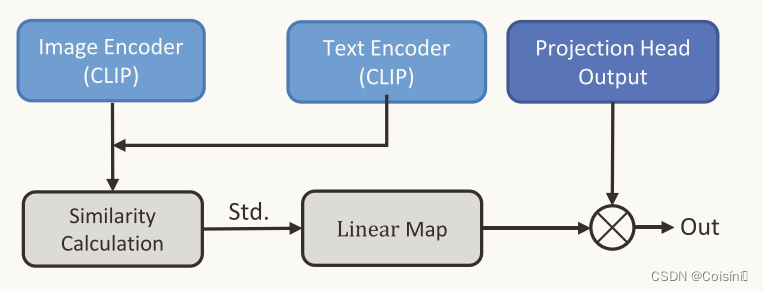
图3:融合调节模块
如果我们仅仅将基于CLIP的特征组合为多模态特征,则由于特征中存在更多的模糊信息而无法提供可靠的信息。 为了消除歧义,我们进一步设计了一个融合调整模块,如图3所示。该模块通过测量文本特征与CLIP提供的图像特征之间的余弦相似度来调整融合特征的强度。 计算余弦相似度并进一步标准化为(4)中的[0, 1]。
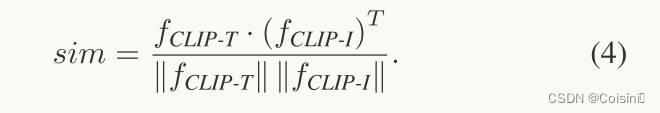
通过投影头和融合调整模块,可以分别生成图像特征 m T x t m_{Txt} mTxt、文本特征 m I m g m_{Img} mImg和融合特征 m M i x m_{Mix} mMix这三个通道。 生成过程如(5)所示,其中M(·)是线性映射函数。

特征聚合
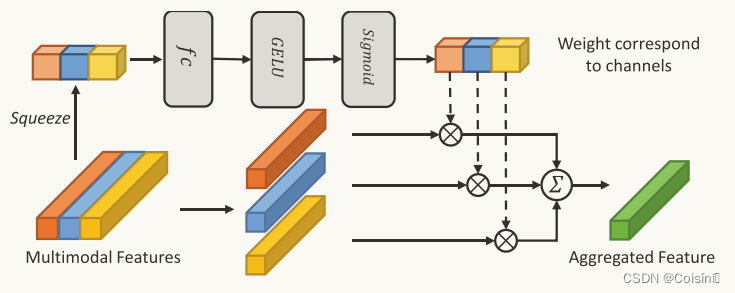
图4:通过模态注意力进行特征聚合
我们进一步设计了一种模态注意机制,在特征聚合之前重新加权 m T x t m_{Txt} mTxt、 m I m g m_{Img} mImg 和 m M i x m_{Mix} mMix 的通道。受挤压和激励网络(SE-Net)[21]的启发,我们设计了一个模态注意力模块,如图 4 所示。首先,我们将三个特征连接到$ L×3 的维度,其中 的维度,其中 的维度,其中 L 是特征长度。按特征应用平均池化和最大池化,获得 1 × 3 向量。然后,将上一步获得的初始权值送入两个 3 × 3 的全连接层。通过基于 G E L U 和 S i g m o i d 的归一化,我们获得了注意力权重 是特征长度。按特征应用平均池化和最大池化,获得 1 × 3 向量。然后,将上一步获得的初始权值送入两个3×3的全连接层。通过基于 GELU 和 Sigmoid 的归一化,我们获得了注意力权重 是特征长度。按特征应用平均池化和最大池化,获得1×3向量。然后,将上一步获得的初始权值送入两个3×3的全连接层。通过基于GELU和Sigmoid的归一化,我们获得了注意力权重att = {att_{Txt},att_{Imag},att_{Mix}} ,将权重与 ,将权重与 ,将权重与 m_t 、 、 、m_i $和 m m i x m_{mix} mmix 相乘,并执行求和过程,获得 L × 1 的聚合特征 m A g g m_Agg mAgg。
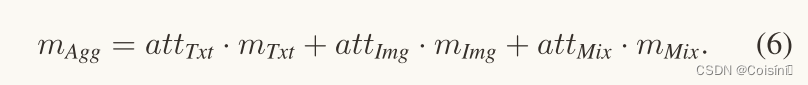
分类
最后,我们将聚合表示 m A g g m_Agg mAgg 输入分类器 F c l s F_{cls} Fcls 来预测标签 y ^ \hat{y} y^。分类器是一个两层的全连接网络。 在提出的 FND-CLIP 方案中,我们使用交叉熵作为目标函数。
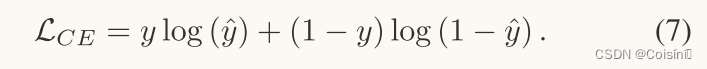
训练细节
在选择BERT预训练模型时,我们对中文数据使用“bert-base-chinese”模型,对英文数据使用“bert-base-uncased”模型。我们将输入文本的长度设置为 300 个单词。 视觉特征由预训练的ResNet-101提取,其中输入图像的大小为224×224,与CLIP相同。由于 CLIP 是针对英文文本进行预训练的,因此我们使用 Google Translation API1 将中文文本翻译成英文。预训练的 CLIP 模型是“ViTB/32”。 为了满足 CLIP 中输入大小的上限,我们使用摘要生成模型2为长度超过 50 的文本生成摘要语句。我们在训练阶段对 ResNet 进行微调,并冻结 BERT 和 CLIP,因为它们在小数据集上训练困难。我们使用带有默认参数的 Adam 优化器。学习率为$ 1 \times 10^{−3}$,权重衰减为 12 12 12。批量大小设置为$ 64$。我们训练模型 50 50 50 个 epoch,并选择具有最佳测试精度的 epoch 以避免过度拟合。
设置
我们使用从社交媒体收集的三个真实世界数据集,即微博[23]、Gossipcop 和 Politifact[24]。 在实验过程中,没有图像或没有文本的单峰新闻帖子被删除。 如果一篇新闻文章包含带有多个关联图像的文本,我们会任意选择一个图像。微博[23]是假新闻检测中广泛使用的中文数据集。 训练集包含 3,749 条真实新闻和 3,783 条假新闻,测试集包含 1,996 条新闻。Politifact 和 Gossipcop 数据集是分别从 FakeNewsNet [24] 存储库的政治和娱乐领域收集的两个英语数据集。Politifact 在训练集中包含 244 条真实新闻和 135 条假新闻,在测试集中包含 75 条真实新闻和 29 条新闻。 Gossipcop 包含 10,010 条训练新闻,其中 7,974 条真实新闻和 2,036 条假新闻。 测试集有 2,285 条真实新闻和 545 条假新闻。
比较
表格1 FND-CLIP 与其他方法在三个数据集上的性能比较。我们的方法达到了最高的准确率,并且精确率、召回率和 FI-Score 也高于大多数对比方法。

我们将FND-CLIP与最先进的方法进行了比较。比较结果见表一。表中的‘-’符号表示原始文件中没有结果。FND-CLIP在三个数据集上的准确率最高分别为90.7%、94.2%和88.0%,比其他方法取得的最佳结果高出0.7%、6.8%和1.3%。FND-CLIP 在所有测试中的精确度、召回率和准确度方面也排名第一或第二。
许多方法,例如 EANN 和 Spotfake,通过连接或使用注意力机制来融合特征。 然而,由于提取的特征不在同一语义空间中,这些方法常常缺乏相关性信息。 相比之下,CAFE 使用跨模态对齐来训练可以将文本和图像映射到同一语义空间的编码器。 然而,由于数据集有限和标签粗糙,编码效果并不理想,导致文本和图像特征之间存在显着的语义差距。 相比之下,FND-CLIP 实现更好的性能有几个原因。 首先,预训练的 CLIP 编码器可以生成语义信息丰富的文本和图像特征,为单峰特征提供补充信息,并生成准确表示文本和图像之间相关性的融合特征。 此外,模态注意力机制自适应地确定文本、图像和融合特征的权重,从而生成更好的聚合特征并提高分类精度。 总体而言,我们的比较研究结果证明了 FND-CLIP 在解决多模态 FND 特征融合挑战方面的有效性。
消融研究
为了评估 FND-CLIP 中关键组件的影响,我们删除了不同的组件,并在三个数据集上从头开始训练模型,如下所示。
(1) FND-CLIP w/o A。我们删除了模态注意模块并直接聚合三个特征以获得聚合特征;(2)FND-CLIP w/o F。我们删除了融合模块并使用两个单峰特征对新闻进行分类;(3) FND-CLIP w/o C。我们删除了所有与CLIP相关的模块,仅使用BERT和ResNet来提取文本和图像特征; (4)FND-CLIP MC-only:我们删除了单峰特征提取器、BERT和ResNet,只使用多峰CLIP融合特征; (5)FND-CLIP Ionly:我们去除所有与文本相关的特征,仅使用ResNet提取的图像特征进行分类; (6) FND-CLIP T-only:我们只使用BERT提取特征来实现检测任务,没有任何视觉信息。
每个组件的有效性
表 II 中的结果显示了每个组件的影响。 1)FND-CLIP优于FND-CLIP w/o C,表明CLIP可以有效地为假新闻检测提供可辨别的特征,并且可以显着提高检测精度。 由于仅使用模内特征进行分类,最终的特征无法代表图像和文本之间的内在关系。 2)FND-CLIP 优于 FND-CLIP w/o F,表明 CLIP 的融合特征对于检测很重要。 虽然单模态分支也包含 CLIP 编码特征,但它们无法表示间模态特征。 同时,FND-CLIP w/o F 优于 FNDCLIP w/o C,表明使用 CLIP 编码特征对单峰特征的补充是有效的。 3)FND-CLIP 优于 FND-CLIP w/o A,这表明模态注意力对于平衡模态很有用。
来自不同模态的贡献
表格2 FND-CLIP 的架构设计和不同特征在三个数据集上的消融研究。
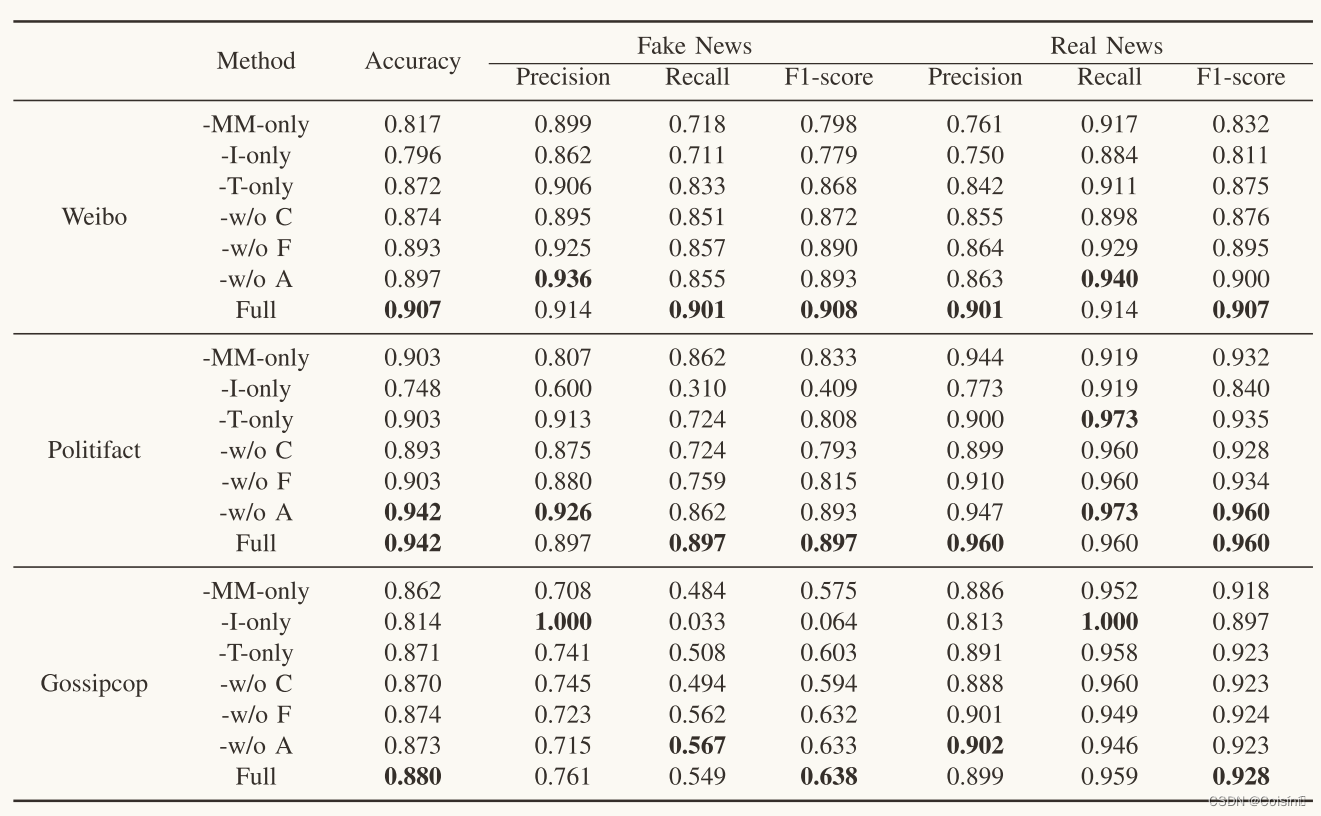
第二组实验是评估假新闻检测中不同模式的分类性能。表二的结果显示了不同方式的贡献。 1)FND-CLIP I-only 表现最差,表明仅使用图像不足以检测假新闻。 2) FND-CLIP MM-only 在微博上的准确率达到 81.7%,甚至比 FND-CLIP T-only 还要差。这表明图像和文本的相关性信息有助于检测,但是仅使用CLIP是无效的,融合特征应该与单峰特征一起使用。 此外,基于CLIP的特征侧重于文本的语义,而基于BERT的特征则包含情感信息。 这种互补的特性也有助于检测任务。 3)FND-CLIP T-only取得了第二好的结果,表明仅使用文本特征就可以基本完成分类任务。 然而,FNDCLIP 的性能优于 FND-CLIP T-only,这表明视觉功能可以提供有用的信息。
Conclusions
在本文中,我们提出了一种多模态假新闻检测的新方法,称为 FND-CLIP。 我们的方法利用 CLIP 模型来提取对齐的多模态特征并指导不同模态的网络学习。 此外,我们提出了一种模态注意力机制,以更好地聚合文本、图像和融合特征。 通过对著名 FND 数据集的大量实验,我们发现基于 CLIP 的多模态特征表示和融合可以与基于 ResNet 和基于 BERT 的单模态特征很好地协作,在大多数情况下取得了最先进的结果 。 结果还表明,所提出的模态注意机制可以通过去除聚合特征中的噪声和冗余来改善分类结果。 除了所提出的 FND-CLIP 所获得的性能之外,输出仍然是二进制形式,这仍然无法解释新闻中的哪些元素对于异常检测至关重要。 在未来的工作中,我们希望开发出更可靠的假新闻检测系统。