大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
4M-21证明了在21种不同的模态和任务上成功训练任意模型。这一成就是通过采用特定于模态的分词器将所有模态映射到离散的Token集,以及多模态Mask训练目标来实现。
与更专业的模型相比,该模型可在多个数据集中扩展到30亿个参数,而不会影响性能。由此产生的统一模型表现出强大的开箱即用功能,并为多模态交互、生成和检索开辟了新的途径。未来4M-21还需要进一步的探索迁移和涌现能力。

从4M看起
最近解决视觉中多任务学习挑战的尝试已经从组合密集的视觉任务发展到将众多任务集成到统一的多模态模型中。Gato、OFA、Pix2Seq、UnifiedIO和4M等方法将各种模态转换为离散Token,并使用序列或掩码建模目标训练Transformer。一些方法通过对不相交数据集的共同训练来实现更加广泛的任务,而其他方法(如 4M)则使用伪Token对的对齐数据集进行任意到任意模态的预测。
掩码(Mask)建模已被证明在学习跨模态表示方面是有效的,这对于多模态学习至关重要,并且在与Token相结合时可以实现生成式应用程序。
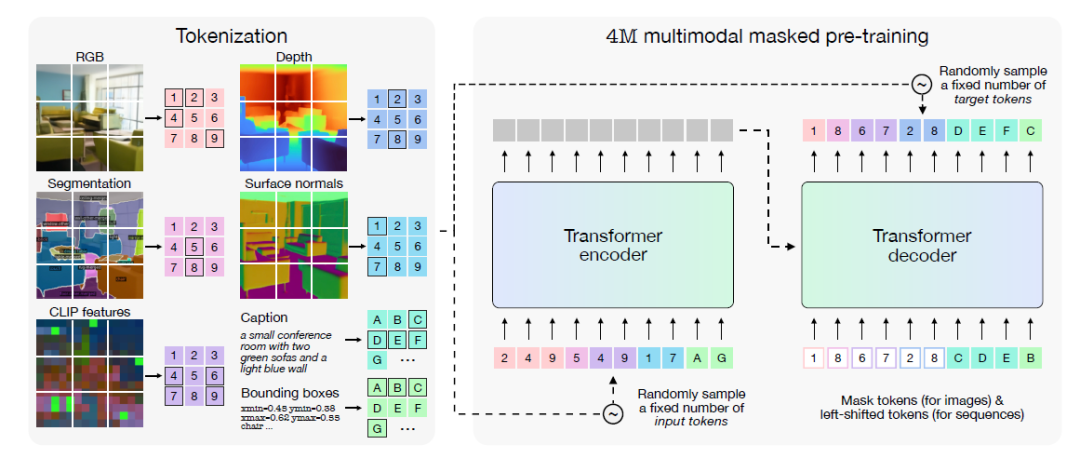
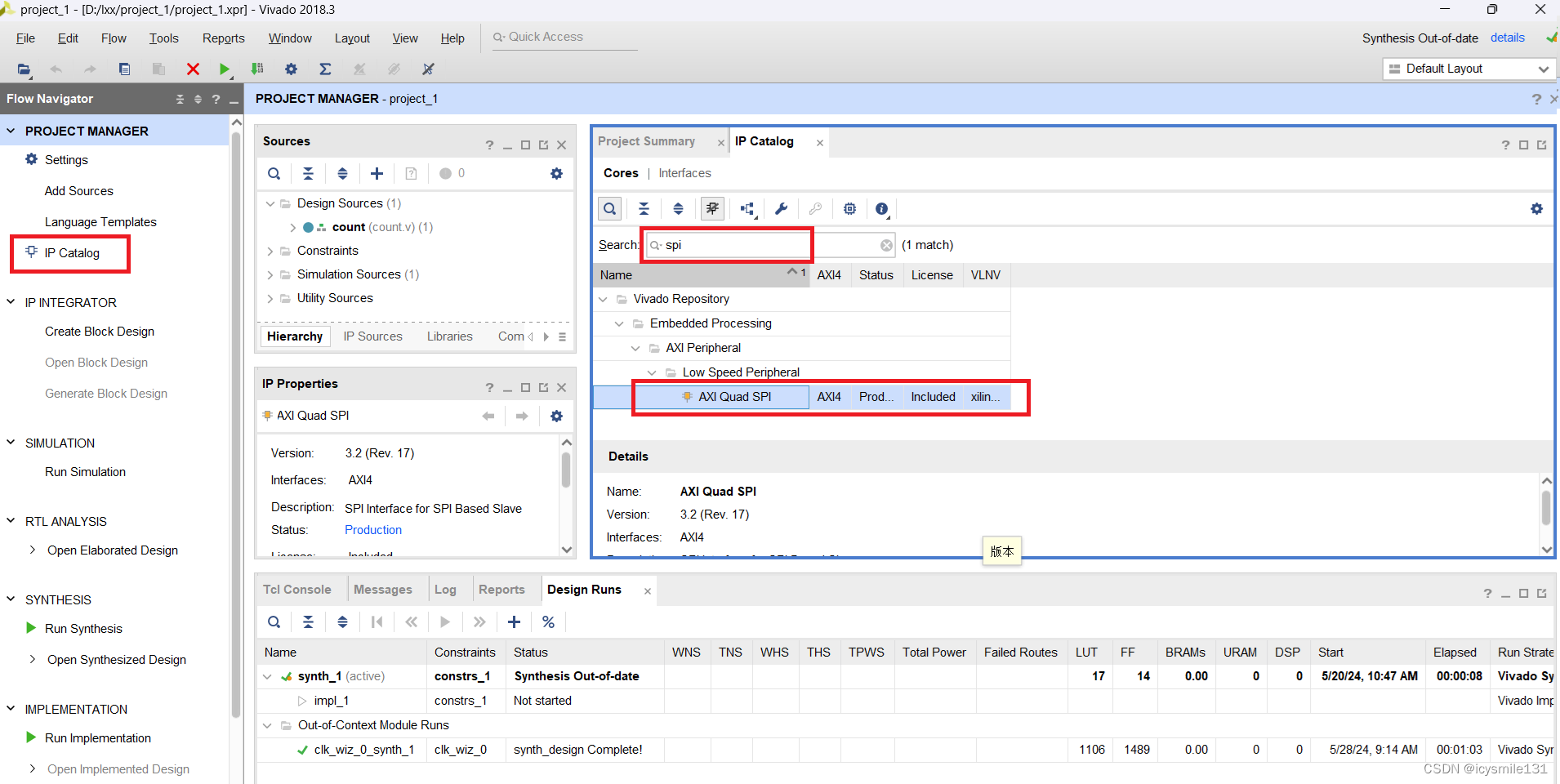
上图是4M例子,注意不是今天的4M-21!!小编来解释下:左边是一幅图的不同维度数据,例如RGB、标题、深度、表面法线、语义分割图、边界框和标记化CLIP特征图。选择这些模态是为了涵盖几个关键方面:语义信息(标题、语义分割、边界框、CLIP)、几何信息(深度、表面法线)和RGB的混合。当用作输入模态时,这些模态可用作有关场景几何及其语义内容的先验信息。当用作目标任务时,它们使模型能够控制学习何种表示。
这些模态在用于编码信息的格式方面是多种多样的。它们由密集的视觉模态(RGB、深度、表面法线、语义分割)、稀疏和/或基于序列的模态(标题、边界框)以及神经网络特征图(CLIP)组成。最后,这些模态允许与模型进行多样化和丰富的交互。
上图右边是一个典型的编码和解码的框架,4M预训练目标包括训练 Transformer编码器-解码器,训练是以一个随机Token子集预测从所有模态中随机采样的另一个子集。大白话输入和输出都是随机抽样,按照“填空游戏”进行训练模型。其实某种意义上就是另一种“BERT”。

4M-21
来自苹果公司和瑞士洛桑联邦理工学院(EPFL)的研究人员在多模态掩蔽预训练方案的基础上构建了他们的方法,通过对各种模态的训练显着扩展了其能力。该方法包含20多种模态,包括SAM片段、3D人体姿势、调色板以及各种元数据。通过使用特定于模态的离散分词器,该方法将不同的输入编码为统一的格式,从而能够在多个模态上训练单个模型,而不会降低性能。
下面的例子何其壮观。

4M-21 可以从任何给定的输入模态生成所有模态,并且可以从链式生成中获益。请注意,对于一个输入,所有模态的预测之间具有高度一致性。例子中的每一行都是同一场景的不同模态输入。
绿色突出显示的是 4M无法预测或接受作为输入的新输入/输出对。虽然此图显示了来自单个输入的预测,但 4M-21 可以从所有模态的任何子集生成任何模态。
4M-21采用4M预训练方案,将其扩展为处理多种模式。它使用特定于模态的分词器将所有模态转换为离散标记序列。训练目标包括使用从所有模态中随机选择的随机选择作为输入和目标,从另一个标记子集预测一个标记子集。它利用伪标签来创建一个具有多种对齐模式的大型预训练数据集。该方法包含多种模态,包括 RGB、几何、语义、边缘、特征图、元数据和文本。
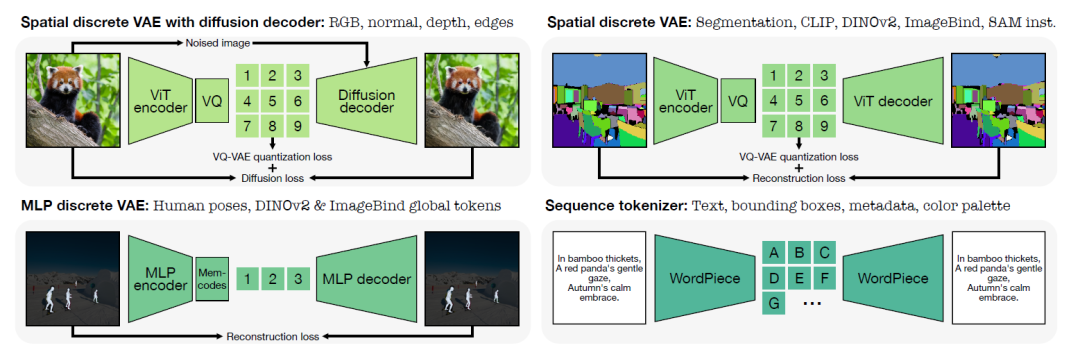
项目主要采用三种主要类型的分词器:用于类图像模态的基于 ViT 的分词器,用于人体姿势和全局嵌入的 MLP 分词器,以及用于文本和其他结构化数据的 WordPiece 分词器。这种全面的标记化方法使模型能够有效地处理各种模态,从而降低计算复杂性并实现跨多个领域的生成任务。<是不是觉得很眼熟啊,这不就是自编码器先走一波么!>

霸气侧漏的功能
4M-21模型展示了广泛的功能,包括可操纵的多模态生成、多模态检索以及在各种视觉任务中的强大开箱即用性能。

该模型根据来至任何模态输入的全局嵌入(Embeddings)来进行多模态的检索操作(上图)。下图代表更多的例子,从一个标题可以检索出各种图片。

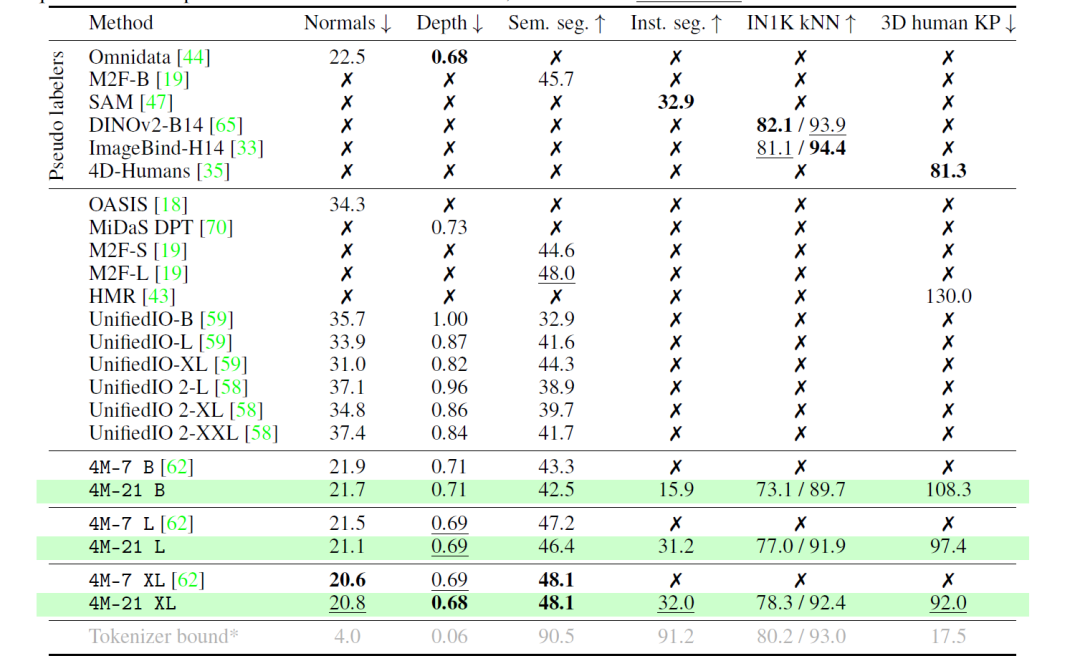
在开箱即用的评估中,4M-21在表面法线估计、深度估计、语义分割、实例分割、3D 人体姿态估计和图像检索等任务上取得了具有竞争力的表现。特别是4M-21 XL变体,在多种模式中表现出强大的性能,而不会牺牲任何单个领域的能力。

给出一副RGB的图片,4M-21能够预测所有的任务,而且保持高度的一致性。
研究人员检查了在大量模态上预训练任意到任意模型的缩放特征,比较了三种模型大小:B、L和XL。评估单模态(RGB)和多模态(RGB+深度)迁移学习场景。在单模态传输中,4M-21在任务上保持了与原始七种模式相似的性能,同时在3D对象检测等复杂任务上显示出改进的结果。随着尺寸的增加,该模型表现出更好的性能,该研究表明,在更广泛的模态下进行训练不会影响原有成熟任务,反而增强了新任务能力,尤其是在模型规模扩大的前提下。