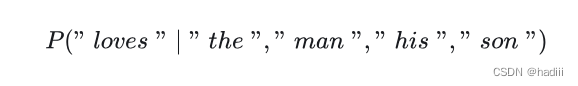Word2Vec是一种用于将词汇映射到高维向量空间的自然语言处理技术。由Google在2013年提出,它利用浅层神经网络模型来学习词汇的分布式表示。Word2Vec有两种主要模型:CBOW(Continuous Bag of Words)和Skip-gram。
1. 模型介绍
Continuous Bag of Words (CBOW)
CBOW模型的目标是通过上下文预测中心词。给定一个上下文窗口中的多个词,CBOW模型尝试预测中心词。这种方法适用于大数据集,因为它更容易并行化。
例如,给定一个句子 “The quick brown fox jumps over the lazy dog”,假设我们选取 “jumps” 作为中心词,那么上下文词可以是 [“The”, “quick”, “brown”, “fox”, “over”, “the”, “lazy”, “dog”]。CBOW模型尝试通过这些上下文词来预测 “jumps”。
Skip-gram
Skip-gram模型的目标是通过中心词预测上下文词。与CBOW相反,Skip-gram模型给定一个中心词,尝试预测它的上下文词。Skip-gram模型在小数据集上表现更好,尤其适用于罕见词汇的表示学习。
例如,给定中心词 “jumps”,Skip-gram模型尝试预测上下文词 [“The”, “quick”, “brown”, “fox”, “over”, “the”, “lazy”, “dog”]。
2. CBOW模型详解
为了详细演示Continuous Bag of Words (CBOW)模型的整个过程,下面将分步骤介绍模型训练的主要流程,并包含每一步的公式和向量的计算过程。我们将用一个简化的示例来说明。
示例
假设我们有一个小语料库:
"The quick brown fox jumps over the lazy dog"
我们将使用一个窗口大小为2的CBOW模型来预测中心词。假设我们选择中心词 “jumps”,它的上下文词是 [“quick”, “brown”, “fox”, “over”]。
步骤1:预处理数据
将句子分词:
["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"]
构建词汇表并为每个词汇分配唯一的ID:
{"the": 0, "quick": 1, "brown": 2, "fox": 3, "jumps": 4, "over": 5, "lazy": 6, "dog": 7}
步骤2:构建训练样本
对于中心词 “jumps”,上下文词是 [“quick”, “brown”, “fox”, “over”]。我们用这些上下文词来预测中心词 “jumps”。
步骤3:定义模型
CBOW模型使用一个浅层神经网络,包含输入层、隐藏层和输出层。
- 输入层:每个上下文词用one-hot向量表示。例如,“quick” 的 one-hot 表示是 [0, 1, 0, 0, 0, 0, 0, 0]。
- 隐藏层:将输入层的向量通过权重矩阵 ( W ) 转换到隐藏层,得到词向量。
- 输出层:将隐藏层的向量通过另一个权重矩阵 ( W’ ) 转换到输出层,计算预测概率。
输入向量
上下文词的one-hot表示如下:
- “quick”:[0, 1, 0, 0, 0, 0, 0, 0]
- “brown”:[0, 0, 1, 0, 0, 0, 0, 0]
- “fox”:[0, 0, 0, 1, 0, 0, 0, 0]
- “over”:[0, 0, 0, 0, 0, 1, 0, 0]
权重矩阵
假设隐藏层维度为3,初始化权重矩阵 ( W ) 和 ( W’ ):
- ( W ) 是 ( 8 \times 3 ) 的矩阵(8是词汇表的大小,3是隐藏层的维度)
- ( W’ ) 是 ( 3 \times 8 ) 的矩阵
初始化权重矩阵(随机初始化):
W = [[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6],
[0.7, 0.8, 0.9],
[1.0, 1.1, 1.2],
[1.3, 1.4, 1.5],
[1.6, 1.7, 1.8],
[1.9, 2.0, 2.1],
[2.2, 2.3, 2.4]]
W' = [[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8],
[0.9, 1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6],
[1.7, 1.8, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4]]
步骤4:前向传播
1. 隐藏层计算
计算每个上下文词的隐藏层表示:
- “quick”:[0, 1, 0, 0, 0, 0, 0, 0]
- “brown”:[0, 0, 1, 0, 0, 0, 0, 0]
- “fox”:[0, 0, 0, 1, 0, 0, 0, 0]
- “over”:[0, 0, 0, 0, 0, 1, 0, 0]
根据之前初始化的权重矩阵 ( W ):
W = [[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6],
[0.7, 0.8, 0.9],
[1.0, 1.1, 1.2],
[1.3, 1.4, 1.5],
[1.6, 1.7, 1.8],
[1.9, 2.0, 2.1],
[2.2, 2.3, 2.4]]
计算:
x_quick = [0, 1, 0, 0, 0, 0, 0, 0]
W^T * x_quick = [0.4, 0.5, 0.6]
x_brown = [0, 0, 1, 0, 0, 0, 0, 0]
W^T * x_brown = [0.7, 0.8, 0.9]
x_fox = [0, 0, 0, 1, 0, 0, 0, 0]
W^T * x_fox = [1.0, 1.1, 1.2]
x_over = [0, 0, 0, 0, 0, 1, 0, 0]
W^T * x_over = [1.6, 1.7, 1.8]
h = ([0.4, 0.5, 0.6] + [0.7, 0.8, 0.9] + [1.0, 1.1, 1.2] + [1.6, 1.7, 1.8]) / 4
h = [3.7, 4.1, 4.5] / 4
h = [0.925, 1.025, 1.125]
2. 输出层计算
根据之前初始化的权重矩阵 ( W’ ):
W' = [[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8],
[0.9, 1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6],
[1.7, 1.8, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4]]
计算:
u = W' * h
u = [[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8],
[0.9, 1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6],
[1.7, 1.8, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4]] * [0.925, 1.025, 1.125]
u_0 = 0.1*0.925 + 0.2*1.025 + 0.3*1.125
= 0.0925 + 0.205 + 0.3375
= 0.635
u_1 = 0.2*0.925 + 0.3*1.025 + 0.4*1.125
= 0.185 + 0.3075 + 0.45
= 0.9425
u_2 = 0.3*0.925 + 0.4*1.025 + 0.5*1.125
= 0.2775 + 0.41 + 0.5625
= 1.25
u_3 = 0.4*0.925 + 0.5*1.025 + 0.6*1.125
= 0.37 + 0.5125 + 0.675
= 1.5575
u_4 = 0.5*0.925 + 0.6*1.025 + 0.7*1.125
= 0.4625 + 0.615 + 0.7875
= 1.865
u_5 = 0.6*0.925 + 0.7*1.025 + 0.8*1.125
= 0.555 + 0.7175 + 0.9
= 2.1725
u_6 = 0.7*0.925 + 0.8*1.025 + 0.9*1.125
= 0.6475 + 0.82 + 1.0125
= 2.48
u_7 = 0.8*0.925 + 0.9*1.025 + 1.0*1.125
= 0.74 + 0.9225 + 1.125
= 2.7875
u = [0.635, 0.9425, 1.25, 1.5575, 1.865, 2.1725, 2.48, 2.7875]
计算softmax概率:
y_hat = softmax(u)
softmax函数定义为:
softmax(z_i) = exp(z_i) / sum(exp(z_j))
计算每个值的指数:
exp(0.635) ≈ 1.887
exp(0.9425) ≈ 2.566
exp(1.25) ≈ 3.490
exp(1.5575) ≈ 4.745
exp(1.865) ≈ 6.457
exp(2.1725) ≈ 8.788
exp(2.48) ≈ 11.932
exp(2.7875) ≈ 16.235
计算softmax概率:
sum_exp = 1.887 + 2.566 + 3.490 + 4.745 + 6.457 + 8.788 + 11.932 + 16.235 = 56.1
y_hat = [1.887/56.1, 2.566/56.1, 3.490/56.1, 4.745/56.1, 6.457/56.1, 8.788/56.1, 11.932/56.1, 16.235/56.1]
≈ [0.0336, 0.0458, 0.0622, 0.0846, 0.1152, 0.1566, 0.2127, 0.2893]
步骤5:计算损失
使用交叉熵损失计算真实标签和预测标签之间的误差:
假设 “jumps” 的 one-hot 表示是 [0, 0, 0, 0, 1, 0, 0, 0],则损失函数计算为:
L = -log(y_hat[4])
= -log(0.1152)
≈ 2.160
步骤6:反向传播和更新权重
1. 计算梯度
对权重矩阵 ( W’ ) 计算梯度:
dL/du_i = y_hat[i] - y_i
其中 ( y_i ) 是真实的one-hot标签。例如,对于中心词 “jumps”,( y_i = 0 ) 对于 ( i ≠ 4 ),而 ( y_4 = 1 )。
dL/du = [0.0336, 0.0458, 0.0622, 0.0846, -0.8848, 0.1566, 0.2127, 0.2893]
计算 ( W’ ) 的梯度:
dL/dW' = h * (dL/du)
对
( W ) 计算梯度:
dL/dh = W'^T * (dL/du)
2. 更新权重
使用梯度下降法更新权重:
W' = W' - learning_rate * (dL/dW')
W = W - learning_rate * (dL/dh)
假设学习率 ( learning_rate = 0.01 ):
更新 ( W’ ):
dL/dW' = h * (dL/du)
= [0.925, 1.025, 1.125] * [0.0336, 0.0458, 0.0622, 0.0846, -0.8848, 0.1566, 0.2127, 0.2893]
dL/dW'_0 = [0.925, 1.025, 1.125] * 0.0336 = [0.0311, 0.0345, 0.0378]
...
dL/dW'_4 = [0.925, 1.025, 1.125] * -0.8848 = [-0.8185, -0.9074, -0.9960]
W'_0 = W'_0 - learning_rate * dL/dW'_0
= [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] - 0.01 * [0.0311, 0.0345, 0.0378, ...]
W' 更新后的值将逐个元素计算。
更新 ( W ):
dL/dh = W'^T * (dL/du)
= [[0.1, 0.9, 1.7], [0.2, 1.0, 1.8], ...] * [0.0336, 0.0458, 0.0622, 0.0846, -0.8848, 0.1566, 0.2127, 0.2893]
dh = [0.1*0.0336 + 0.9*0.0458 + 1.7*0.0622 + 0.2*0.0846 + ... , 1.0*0.0336 + 1.8*0.0458 + ...]
dL/dW = 输入层的平均值 * dL/dh
权重矩阵 ( W ) 和 ( W’ ) 会逐步更新,直到损失函数收敛。
步骤七:迭代
通过对整个语料库的多次迭代,模型会逐步优化权重矩阵,获得高质量的词向量表示。
3. 模型训练
训练Word2Vec模型涉及以下几个步骤:
- 预处理数据:对文本进行分词、去停用词、词干提取等预处理操作。
- 构建词汇表:将所有唯一词汇构建成一个词汇表,每个词汇分配一个唯一的ID。
- 建立训练样本:根据选择的模型(CBOW或Skip-gram),创建训练样本。对于CBOW模型,训练样本是上下文词和中心词的对;对于Skip-gram模型,训练样本是中心词和上下文词的对。
- 定义和训练模型:使用浅层神经网络模型(通常是一个隐藏层的前馈神经网络)来学习词汇的向量表示。通过最小化预测误差(如交叉熵损失),模型调整权重以提高预测准确性。
- 生成词向量:一旦模型训练完成,词汇的向量表示可以从模型的权重中提取出来。这些向量表示可以用于各种NLP任务,如词汇相似度计算、文本分类、聚类等。
3. 应用和优势
Word2Vec模型学习到的词向量具有以下几个优点:
- 捕捉词汇语义:词向量可以捕捉到词汇的语义相似性。例如,“king” - “man” + “woman” ≈ “queen”。
- 高效训练:相比于传统的统计模型(如共现矩阵、LSA),Word2Vec模型训练效率更高,可以处理大规模语料。
- 易于扩展:词向量可以作为其他NLP模型(如RNN、LSTM、Transformer等)的输入,提升模型性能。
4. 实践示例
以下是使用Gensim库训练Word2Vec模型的Python示例代码:
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# 示例文本数据
sentences = [
"The quick brown fox jumps over the lazy dog",
"I love natural language processing",
"Word2Vec is a great tool for NLP"
]
# 分词
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
# 训练Word2Vec模型
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, workers=4)
# 获取词向量
word_vector = model.wv['word2vec']
# 查看相似词
similar_words = model.wv.most_similar('word2vec', topn=5)
print(similar_words)
5. 总结
Word2Vec的优点
| 优点 | 描述 |
|---|---|
| 高效性 | 使用浅层神经网络进行训练,计算效率高,能够在大规模语料库上快速训练 |
| 捕捉语义信息 | 有效捕捉词汇的语义相似性,例如“king - man + woman ≈ queen” |
| 低维表示 | 相比词袋模型和TF-IDF,词向量维度较低,减少计算复杂度和存储需求 |
| 广泛适用 | 生成的词向量可用于多种NLP任务,如文本分类、聚类、信息检索和机器翻译 |
Word2Vec的缺点
| 缺点 | 描述 |
|---|---|
| 对词序敏感 | 不考虑词的顺序,可能导致在某些任务中丢失重要的顺序信息 |
| 静态词向量 | 同一个词在不同的上下文中具有相同的向量表示,无法捕捉词汇的多义性 |
| 数据依赖 | 模型性能高度依赖于训练语料的质量和规模,若训练数据不足或质量不高,词向量质量可能会受到影响 |
Word2Vec的特点
| 特点 | 描述 |
|---|---|
| 分布式表示 | 每个词汇用一个固定长度的向量表示,向量的每个维度表示某种语义特征 |
| 浅层神经网络 | 使用一个隐藏层的前馈神经网络训练模型,包含CBOW和Skip-gram两种方法 |
| 基于上下文 | 通过上下文词预测中心词(CBOW)或通过中心词预测上下文词(Skip-gram) |
Word2Vec的应用场景
| 应用场景 | 描述 |
|---|---|
| 文本分类 | 使用词向量作为特征,提高文本分类模型的性能 |
| 信息检索 | 通过词向量计算词汇相似度,改进信息检索系统效果 |
| 聚类分析 | 使用词向量作为特征,更好地发现文本的主题和结构 |
| 机器翻译 | 词向量帮助捕捉源语言和目标语言之间的语义关系 |
| 情感分析 | 改进情感分析模型的效果,准确识别文本中的情感倾向 |
Word2Vec的发展趋势
| 发展趋势 | 描述 |
|---|---|
| 动态词向量 | ELMo和BERT等模型能够根据上下文动态生成词向量,解决词汇多义性问题 |
| 预训练模型 | 基于Transformer的预训练模型(如GPT和BERT)在各种NLP任务中取得显著成果 |
| 多模态表示 | 词向量在多模态任务(如图像、文本、音频的联合表示)中发挥重要作用 |
| 更高效的训练算法 | 新的训练算法和优化技术提高词向量训练的效率和效果,如负采样和分层Softmax |
| 应用扩展 | 词向量技术在推荐系统、知识图谱、对话系统等领域展现出潜力 |