摘要
为了应对现实世界的动态,智能系统需要在其整个生命周期中增量地获取、更新、积累和利用知识。这种能力被称为持续学习,为人工智能系统自适应发展提供了基础。从一般意义上讲,持续学习明显受到灾难性遗忘的限制,在这种情况下,学习一项新任务通常会导致旧任务的表现急剧下降。除此之外,近年来出现了越来越多的进步,这些进步在很大程度上扩展了对持续学习的理解和应用。对这一方向日益增长和广泛的兴趣表明了它的现实意义和复杂性。在这项工作中,我们提出了一个全面的持续学习调查,寻求桥梁的基本设置,理论基础,代表性的方法,和实际应用。基于现有的理论和实证结果,我们总结了持续学习的一般目标,即在资源效率的背景下确保适当的稳定性-可塑性权衡和足够的任务内/任务间概泛性。然后,我们提供了一个最先进的和详细的分类,广泛分析了代表性方法如何解决持续学习问题,以及它们如何适应现实应用中的特定挑战。通过对有前途的方向的深入讨论,我们相信这种整体的视角可以极大地促进该领域乃至其他领域的后续探索。
Liyuan Wang, Xingxing Zhang, Hang Su, Jun Zhu, Fellow, IEEE
Tsinghua University
简介
学习是智能系统适应动态环境的基础。为了应对外部变化,进化赋予了人类和其他具有强适应性的生物不断获取、更新、积累和利用知识的能力[150],[229],[328]。自然,我们期望人工智能(AI)系统以类似的方式适应。这激发了对持续学习的研究,其中一个典型的设置是一个接一个地学习一系列内容,并表现得好像它们同时被观察到一样(见图1,a)。这些内容可以是新技能,旧技能的新例子,不同的环境,不同的背景等,并结合了特定的现实挑战[328],[423]。由于内容是在一生中不断增加的,因此在许多文献中,持续学习也被称为增量学习或终身学习,没有严格的区分[71],[229]。
与建立在捕获静态数据分布的前提下的传统机器学习模型不同,持续学习的特点是从动态数据分布中学习。一个主要的挑战被称为灾难性遗忘[296],[297],在这种情况下,对新分布的适应通常会导致捕捉旧分布的能力大大降低。这种困境是学习可塑性和记忆稳定性之间权衡的一个方面:前者过多会干扰后者,反之亦然。除了简单地平衡这两个方面的“比例”之外,持续学习的理想解决方案应该具有很强的泛化性,以适应任务内部和任务之间的分布差异(见图1,b)。重用所有旧的训练样本(如果允许的话)可以很容易地解决上述挑战,但会产生巨大的计算和存储开销,以及潜在的隐私问题。事实上,持续学习主要是为了保证模型更新的资源效率,最好接近于只学习新的训练样本。
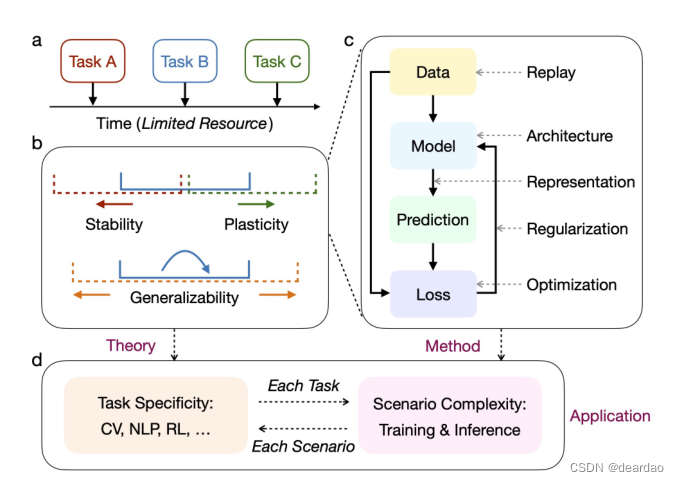
图1所示。持续学习的概念框架。a,持续学习需要适应具有动态数据分布的增量任务(第2节)。b,理想的解决方案应确保在稳定性(红色箭头)和可塑性(绿色箭头)之间进行适当的权衡,以及对任务内(蓝色箭头)和任务间(橙色箭头)分布差异(第3节)具有足够的通用性。代表性的方法针对机器学习的各个方面(第4节)。d,持续学习适应实际应用,以解决特定的挑战,如场景复杂性和任务特异性(第5节)。
近年来,针对机器学习的各个方面提出了许多持续学习方法,从概念上可以分为五组(见图1,c):参考旧模型添加正则化项(基于正则化的方法); 近似和恢复旧的数据分布(基于重播的方法);显式操纵优化程序(基于优化的方法);学习鲁棒和分布良好的表示(基于表示的方法);用合理设计的体系结构(基于体系结构的方法)构造任务自适应参数。这种分类法扩展了常用的分类法和当前的进展,并为每个类别提供了细化的子方向。我们总结了这些方法如何实现持续学习的目标,并对它们的理论基础和具体实现进行了广泛的分析。具体来说,这些方法是紧密相连的,例如:、正则化和重放最终在优化中起到矫正梯度方向的作用,并且具有高度的协同性,例如;,重播的有效性可以通过从旧模型中提取知识来促进。
现实应用对持续学习提出了特殊的挑战,分为场景复杂性和任务特异性(见图1,d)。对于前者,例如在训练和测试中可能缺少任务识别,训练样本可能是小批量甚至一次引入。由于数据标记的成本和稀缺性,持续学习需要对少量、半监督甚至无监督的场景有效。对于后者,虽然目前的进展主要集中在视觉分类方面,但其他视觉领域,如物体检测和语义分割,以及其他相关领域,如条件生成、强化学习(RL)、自然语言处理(NLP)和伦理考虑,正以其各自的特点受到越来越多的关注。我们总结了他们所面临的特殊挑战,并分析了持续学习方法如何适应他们。
考虑到对持续学习的兴趣显著增长,我们相信这样一个最新和全面的调查可以为后续工作提供一个整体的视角。尽管有一些早期的关于持续学习的调查,覆盖范围相对较广[71],[328],但近年来的重要进展并没有被纳入其中。相比之下,最新的调查通常只捕获了持续学习的部分方面,包括其生物学基础[150],[157],[187],[229],视觉分类的专门设置[86],[215],[288],[294],[354],以及NLP[38],[209]或RL[214]的特定扩展。据我们所知,这是第一次系统地总结持续学习的最新进展的调查。在这些优势的基础上,我们提供了关于持续学习的深入讨论,包括当前的趋势、交叉方向的前景以及与神经科学的跨学科联系。
设置
持续学习的特点是从动态数据分布中学习。在实践中,不同分布的训练样本按顺序到达。用θ参数化的持续学习模型需要在没有或有限访问旧训练样本的情况下学习相应的任务,并在其测试集上表现良好。形式上,属于任务t的一批输入训练样本可以表示为Dt,b = {Xt,b, Yt,b},其中,Xt,b为输入数据,Yt,b为数据标签,t∈t ={1,···,k}为任务标识,b∈Bt为批索引(t和Bt分别表示它们的空间)。这里我们通过其训练样本Dt定义一个“任务”,其分布Dt:= p(Xt, Yt) (Dt表示省略批指标的整个训练集,对于Xt和Yt也是如此),并假设训练和测试之间的分布没有差异。在实际的约束条件下,数据标签Yt和任务标识t可能并不总是可用。在持续学习中,每个任务的训练样本可以分批增量到达(即{{Dt,b}b∈Bt}t∈t)或同时到达(即{Dt}t∈t)。
典型场景
根据增量批次的划分和任务身份的可用性,我们将典型的持续学习场景描述如下(形式比较见表1):
•实例增量学习(IIL):所有的训练样本都属于同一个任务,并且分批到达。
•Domain-Incremental Learning (DIL):任务具有相同的数据标签空间,但输入分布不同。任务标识不是必需的。
•任务增量学习(TIL):任务具有不相交的数据标签空间。在培训和测试中都提供了任务标识。
•类增量学习(CIL):任务具有不相交的数据标签空间。任务标识只在培训中提供。
•无任务持续学习(TFCL):任务具有不相交的数据标签空间。在培训或测试中都不提供任务标识。在线持续学习(OCL):任务具有不相交的数据标签空间。每个任务的训练样本作为一次通过的数据流到达。
•模糊边界持续学习(BBCL):任务边界是模糊的,其特征是不同但重叠的数据标签空间。
•连续预训练(CPT):预训练数据按顺序传递。目标是改善向下游任务的知识转移。