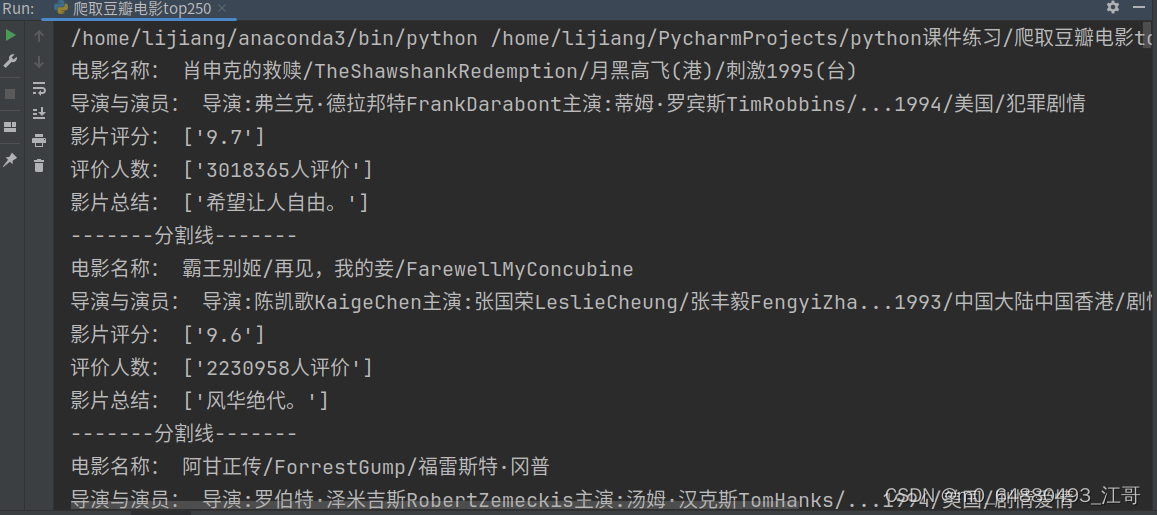
在上一篇文章的基础上,改进了代码质量,增加了多个正则表达式匹配,但同事也增加了程序执行的耗时。
from bs4 import BeautifulSoup
import requests
import time
import re
from random import randint
import pandas as pd
url_list = ['https://movie.douban.com/top250']
base_url = 'https://movie.douban.com/top250?start={start}'
for start in range(25, 251, 25):
url_list.append(base_url.format(start=start))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'}
movie_info = []
def parse_info(info):
# 尝试第一个正则表达式
pattern1 = re.compile(r"导演: (.*?)\s*/?\s*主演: (.*?)\s*(\d{4})\s*/\s*(.*?)\s*/\s*(.*)")
match1 = re.search(pattern1, info)
if match1:
director = match1.group(1).strip()
actors = match1.group(2).strip()
year = match1.group(3).strip()
countries = match1.group(4).strip().split(' ')
genres = match1.group(5).strip().split(' ')
return director, actors, year, countries, genres
# 尝试第二个正则表达式
pattern2 = re.compile(r"导演: (.*?)\s*/?\s*(\d{4})\s*/\s*(.*?)\s*/\s*(.*)")
match2 = re.search(pattern2, info)
if match2:
director = match2.group(1).strip()
actors = ""
year = match2.group(2).strip()
countries = match2.group(3).strip().split(' ')
genres = match2.group(4).strip().split(' ')
return director, actors, year, countries, genres
# 尝试第三个正则表达式
pattern3 = re.compile(r"导演: (.*?)\s*(\d{4})\s*/\s*(.*?)\s*/\s*(.*)")
match3 = re.search(pattern3, info)
if match3:
director = match3.group(1).strip()
actors = ""
year = match3.group(2).strip()
countries = match3.group(3).strip().split(' ')
genres = match3.group(4).strip().split(' ')
return director, actors, year, countries, genres
# 尝试第四个正则表达式 (处理有多个年份的情况)
pattern4 = re.compile(r"导演: (.*?)\s*主演: (.*?)\s*(.*?)\s*/\s*(.*?)\s*/\s*(.*)")
match4 = re.search(pattern4, info)
if match4:
director = match4.group(1).strip()
actors = match4.group(2).strip()
year = match4.group(3).strip()
countries = match4.group(4).strip().split(' ')
genres = match4.group(5).strip().split(' ')
return director, actors, year, countries, genres
# 如果没有匹配,返回空值
return "", "", "", [], []
for url in url_list:
time.sleep(randint(1, 3))
response = requests.get(url, headers=headers)
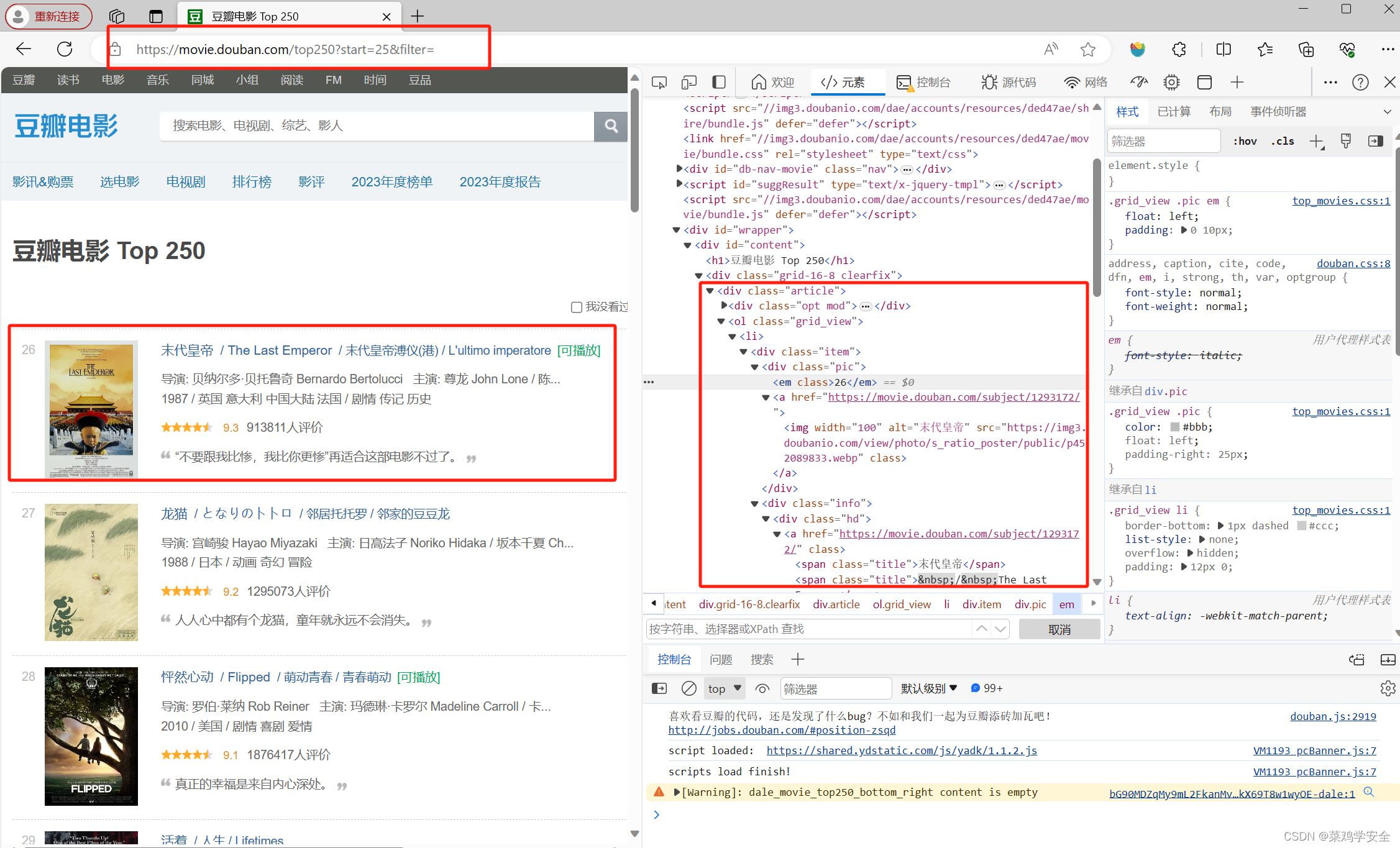
soup = BeautifulSoup(response.text, 'html.parser')
movie_items = soup.find_all('div', class_='item')
for movie in movie_items:
# 获取排名
rank = movie.find('em').text.strip()
# 获取电影标题
title = movie.find('span', class_='title').text.strip()
# 获取电影导演、演员、年份、上映地区等信息
info = movie.find('div', class_='bd').find('p').text.strip()
# 解析 info 字符串
director, actors, year, countries, genres = parse_info(info)
# 打印未匹配到的 info
if director == "" and actors == "" and year == "":
print(f"未匹配到的info: {info}")
# 获取评分信息
rating_num = movie.find('span', class_='rating_num').text.strip()
# 获取评价人数信息
rate_people_num = movie.find('div', class_='star').find_all('span')[3].text.strip()
# 将信息进行汇总
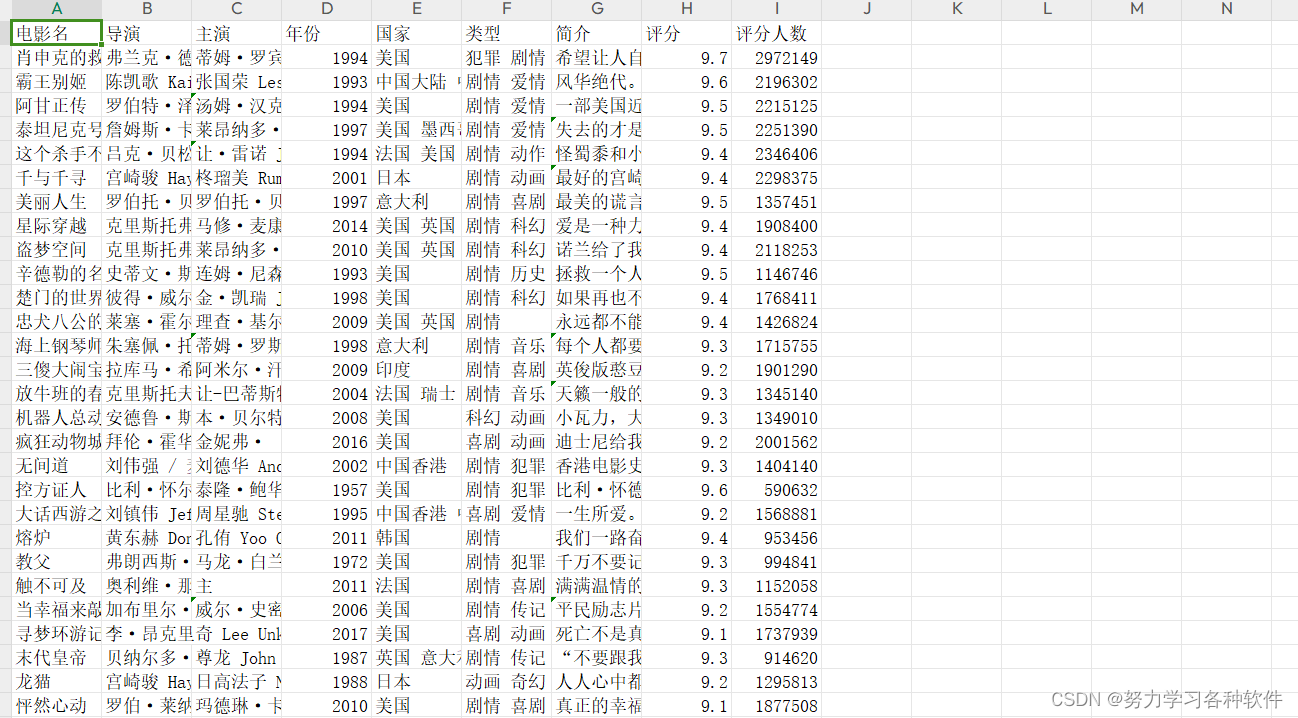
mock_data = {
'排名': rank,
'电影名称': title,
'导演': director,
'演员': actors,
'上映年份': year,
'上映地区': countries,
'电影类型': genres,
'评分': rating_num,
'投票人数': rate_people_num
}
movie_info.append(mock_data)
df = pd.DataFrame(movie_info,columns=['排名', '电影名称', '导演', '演员', '上映年份', '上映地区', '电影类型', '评分', '投票人数'])
excel_path = 'movie_info.xlsx'
df.to_excel(excel_path, index=False)

![[Python练习]<span style='color:red;'>使用</span>Python<span style='color:red;'>爬虫</span><span style='color:red;'>爬</span><span style='color:red;'>取</span><span style='color:red;'>豆瓣</span><span style='color:red;'>top</span><span style='color:red;'>250</span>的<span style='color:red;'>电影</span>的页面源码](https://img-blog.csdnimg.cn/direct/1e7f2a5a6b2f4251b7cde3a5be7970f7.png)