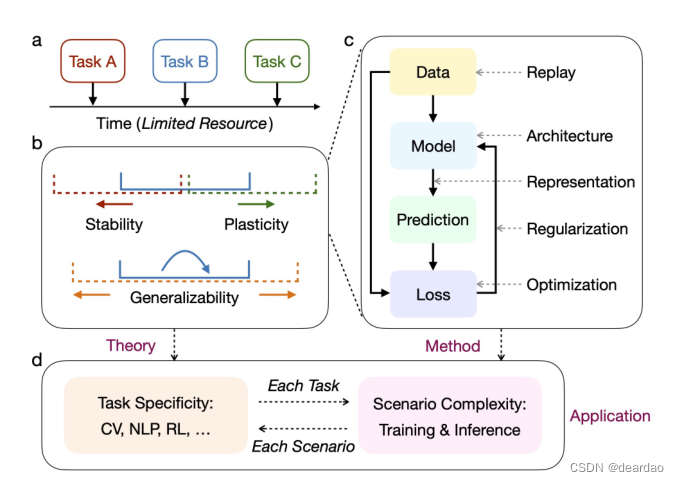
机器学习:理论、方法与应用实践
目录
一、引言
在当代信息技术飞速发展的背景下,机器学习作为人工智能领域的一个重要分支,已经引起了广泛的关注。它涉及从数据中自动学习和改进的算法,并在此基础上进行预测和决策。本文将深入探讨机器学习的概念、步骤、分类以及如何在实践中应用这些技术。我们将通过学术性语言确保内容的专业性和准确性,并通过代码示例来增强理论的实践意义。
二、机器学习的基本概念
2.1 机器学习的定义
机器学习是一种使计算机系统利用经验改进性能的技术。它基于数据集构建模型,并使用这些模型对新输入的数据做出决策或预测。机器学习的核心在于“学习”,即模型能够从错误中自我修正和优化。
2.2 机器学习的重要性
在处理大数据时,传统的编程方法变得不再适用。机器学习提供了一种有效途径,可以发现数据中的模式和结构,为复杂问题提供解决方案。它在金融、医疗、交通等多个领域均有广泛应用。
三、机器学习的主要步骤
3.1 数据收集与预处理
在机器学习流程中,首先需要收集相关数据,并对数据进行清洗及预处理。这一步骤包括去除噪音、填补缺失值、数据标准化等操作。
3.2 特征选择与工程
特征选择是识别并选取最有助于模型训练的数据特征的过程。特征工程则是创建新的特征,以更好地表示数据中的信息。
3.3 模型选择与训练
根据问题的性质选择合适的机器学习模型,然后使用训练数据来训练这个模型。这个过程可能涉及参数调优以提高模型的性能。
3.4 模型评估与测试
通过交叉验证等方法评估模型的性能,并在独立的测试集上测试模型效果,以确保模型的泛化能力。
3.5 模型部署与监控
最后一步是将训练好的模型部署到生产环境中,并持续监控其性能,以便及时调整和优化。
四、机器学习的分类
4.1 监督学习(Supervised Learning)
监督学习是最常用的机器学习类型,它要求每个训练样本都有标签。主要任务包括分类和回归。
4.2 无监督学习(Unsupervised Learning)
无监督学习不要求训练数据有标签。它的目标是发现数据中的隐藏结构,如聚类和降维。
4.3 强化学习(Reinforcement Learning)
强化学习是一种让机器通过试错来学习最优策略的方法,常用于游戏和机器人控制等领域。
五、机器学习算法实践
5.1 线性回归算法实现
线性回归是监督学习中的一个基本算法,用于预测数值型数据。以下是一个Python中使用scikit-learn库实现线性回归的简单例子:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np
假设我们有一组房价(y)和对应的房屋面积(X)
X = np.array([[60], [80], [100], [140], [180]])
y = np.array([250, 300, 350, 400, 450])
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
创建线性回归模型并训练
reg = LinearRegression().fit(X_train, y_train)
预测测试集
predictions = reg.predict(X_test)
print(predictions)
```
5.2 决策树算法实现
决策树是一种可用于分类和回归的监督学习算法。以下是使用Python的scikit-learn库实现决策树分类器的例子:
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
创建决策树模型并训练
clf = DecisionTreeClassifier().fit(X_train, y_train)
预测测试集
predictions = clf.predict(X_test)
print(predictions)
```