文章汇总
存在的问题
之前学者的方法主要侧重于适用于所有类别的提示模板,而忽略了每个类别的特征表示。
动机
引入可训练向量来替代多模态提示中的标签词。
流程解读

之前的方法侧重于适用于所有类别的提示模板,而忽略了每个类别的特征表示。作者这里着重考虑了类别的提示 M i M_i MiLAMM的提示模版为: z i = [ a ] [ p h o t o ] [ o f ] < M i > ] [ . ] z_i=[a][photo][of]<M_i>][.] zi=[a][photo][of]<Mi>][.];LAMM+CoOp的提示模版为 z i ∗ = [ V 1 ] [ V 2 ] … [ V 4 ] [ ] z_i^*=[V_1][V_2]\ldots[V_4][] zi∗=[V1][V2]…[V4][],作者为了LAMM无缝地纳入到CLIP,使用了多个损失来达到正则化的手段,即图中右边的多个损失。
L W C L_{WC} LWC:降低模型过度拟合的风险。
θ \theta θ为当前模型的训练参数, θ ˉ \bar \theta θˉ为最初放入clip得到的初始参数。

L C O S L_{COS} LCOS:降低每个类别的文本特征的过拟合。
z i z_i zi为上面提及的类别提示模版, y i y_i yi为原始的提示模版,如 :a photo of < class >

可以看到损失函数的设计是希望 z i , y i z_i,y_i zi,yi对应的相似度越来越高。
L K D L_{KD} LKD:常规的知识蒸馏损失,希望将CLIP的泛化知识转移到LAMM。
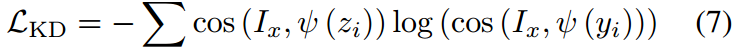
L C E L_{CE} LCE:针对下游任务的交叉熵损失。
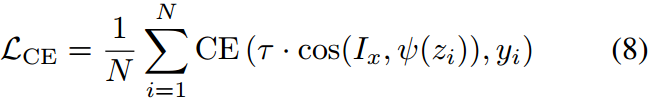
总损失:
L = L C E + λ 1 ∗ L W C + λ 2 ∗ L C O S + λ 3 ∗ L K D , λ 1 = 1 / n , λ 2 = 1 , λ 3 = 0.05 L=L_{CE}+\lambda_1*L_{WC}+\lambda_2*L_{COS}+\lambda_3*L_{KD},\lambda_1=1/n,\lambda_2=1,\lambda_3=0.05 L=LCE+λ1∗LWC+λ2∗LCOS+λ3∗LKD,λ1=1/n,λ2=1,λ3=0.05
摘要
随着预训练的视觉语言模型(如CLIP)在视觉表征任务中的成功,将预训练的模型转移到下游任务已成为一个重要的范式。近年来,受自然语言处理(NLP)启发的提示调优范式在VL领域取得了重大进展。然而,之前的方法主要侧重于构建文本和视觉输入的提示模板,而忽略了VL模型与下游任务之间类标签表示的差距。为了解决这一挑战,我们引入了一种创新的标签对齐方法LAMM,该方法可以通过端到端训练动态调整下游数据集的类别嵌入。此外,为了实现更合适的标签分布,我们提出了一种分层损失,包括参数空间、特征空间和logits空间的对齐。我们在11个下游视觉数据集上进行了实验,并证明我们的方法显著提高了现有多模态提示学习模型在少样本场景下的性能,与最先进的方法相比,在16-shot下的平均准确率提高了2.31%(%)。此外,与其他提示学习方法相比,我们的方法在提示学习方面表现出色。重要的是,我们的方法与现有的提示调优方法是协同的,可以在它们的基础上提高性能。我们的代码和数据集将在https://github.com/gaojingsheng/LAMM上公开提供。
介绍
构建能够在现实环境中理解多模态信息的机器是人工智能的主要目标之一,其中视觉和语言是两个关键模态(Du et al 2022)。一种有效的实现方法是在大规模视觉文本数据集上预训练基础视觉语言(VL)模型,然后将其转移到下游应用场景(Radford et al 2021;Jia et al . 2021)。通常,VL模型使用两个独立的编码器对图像和文本特征进行编码,然后设计适当的损失函数进行训练。然而,在大量训练好的模型上进行微调是昂贵和复杂的,因此产生了问题如何有效地将预训练的VL模型转移到下游任务是一个鼓舞人心和有价值的问题。
提示学习为这一问题提供了有效的解决方案,基于人类先验知识为下游任务提供相应的文本描述,可以有效增强VL模型的zero-shot和few-shot能力。通过具有少量任务特定参数的可训练模板,构建模板的过程通过梯度下降而不是手动构建进一步自动化(Lester, al - rfu和Constant 2021)。具体而言,现有的多模态提示调音方法(Zhou et al . 2022b,a;Khattak et al . 2022)使用冻结的CLIP (Radford et al . 2021)模型,并分别为文本和视觉编码器设计可训练的提示。这些方法确保在不改变VL模型参数的情况下,可以更好地将VL模型转移到下游任务。然而,他们的方法主要侧重于适用于所有类别的提示模板,而忽略了每个类别的特征表示。
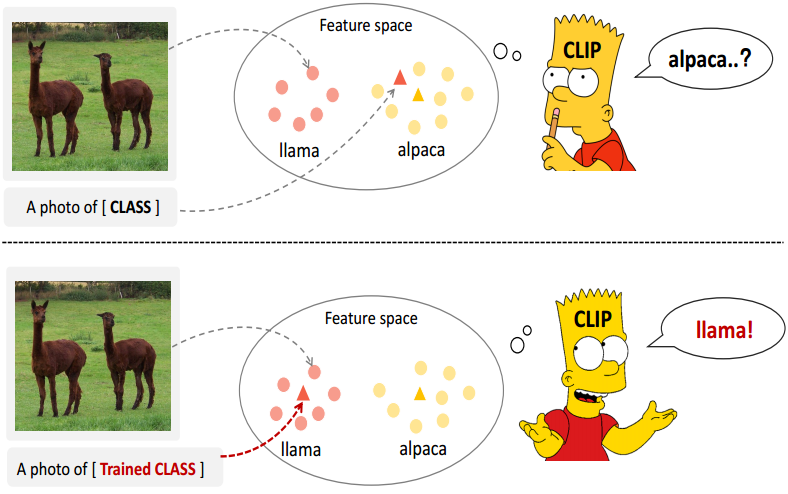
图1:CLIP更倾向于将图像归类为属于类似的类别。改变类别文本功能的位置可以增强CLIP的识别能力。
文本模板中的标记对于将图像分类到适当的类别至关重要。例如,如图1所示,美洲驼和羊驼是两种非常相似的动物。在CLIP中,由于预训练数据集中羊驼数据的过度表示,存在将美洲驼错误分类为羊驼的倾向。CLIP通过细化文本嵌入位置,利用训练好的特征空间来区分这两个物种。因此,确定VL模型中下游任务中每个类别的最佳表示是至关重要的。在自然语言处理领域,存在着“软语化者”(Cui等)2022),这使得模型能够预测文本模板中 的表示,从而自己表示原始句子的类别。与自然语言处理不同的是,将直接预测图像类别的任务交给VL模型的文本编码器是不可行的。然而,我们可以优化下游数据集中各种类别的类别嵌入,以增加每个图像与其对应类别描述之间的相似性。
因此,我们引入了一种名为LAMM的标签对齐技术,该技术通过梯度优化自动搜索最优嵌入。据我们所知,可训练类别令牌的概念是在预训练的VL模型中首次提出的。同时,为了防止整个提示模板的语义特征偏离太远,我们在训练阶段引入了分层损失。层次损失有助于在参数、特征和逻辑空间之间对类别表示进行对齐。通过这些操作,可以在LAMM中保留CLIP模型的泛化能力,使LAMM在保留原始类别描述语义的同时更好地区分下游任务中的不同类别。此外,由于LAMM仅对下游数据集中的标签嵌入进行微调,因此它不会遇到传统方法在持续学习过程中通常遇到的灾难性遗忘问题。
我们在11个数据集上进行了实验,涵盖了一系列下游识别场景。在模型方面,我们测试了目前在多模态提示学习中表现最好的vanilla CLIP、CoOp (Zhou et al . 2022b)和MaPLe (Khattak et al . 2022)。大量的实验证明了该方法在少量学习中的有效性,说明了它在领域泛化和持续学习方面的优点。此外,我们的方法与流行的多模态提示技术兼容,可以放大其在下游数据集的功效,确保一致性增强。
相关工作
视觉语言模型
近年来,视觉语言预训练模型(Vision-Language Pre-Trained Models, VL-PTMs)的发展取得了巨大的进步,如CLIP (Radford et al . 2021)、ALIGN (Jia et al . 2021)、LiT (Zhai et al . 2022)和FILIP (Yao et al . 2022)等模型。这些VL- PTM在大规模的图像-文本语料库上进行预训练,并学习通用的跨模态表示,这有利于在下游的VL任务中获得较强的性能。例如,CLIP是在来自互联网的大量图像标题对集合上进行预训练的,利用对比损失,使匹配的图像文本对的表示更接近,而将不匹配的图像文本对的表示进一步分开。在预训练阶段之后,CLIP在图像识别(Gao et al 2021)、目标检测(Zang et al 2022)、图像分割(Li et al 2022)和视觉问题回答(Sung, Cho, and Bansal 2022)中学习通用跨模态表示方面表现出色。
提示学习
提示学习通过设计提示模板来适应预训练的语言模型(plm),以利用plm的功能达到前所未有的高度,特别是在少y样本学习设置中(Liu et al 2021)。随着大规模VL模型的出现,许多研究者试图将提示学习整合到VL情境中,从而开发出更适合这些情境的提示范式。CoOp (Zhou et al . 2022b)首先通过可学习的提示模板词引入了VL模型的提示调优方法。Co-CoOp (Zhou等 2022a)通过合并实例级图像信息来提高新类的性能。与文本模板中的提示工程不同,VPT (Jia et al 2022)将可学习的参数插入视觉编码器中。MaPLe (Khattak et al 2022)在文本和图像编码器的每一层的隐藏表示中附加了一个软提示,从而在少量图像识别中获得了新的可靠性能。
以前的多模态提示主要集中在文本和视觉输入的提示模板的工程上,而忽略了这些模板中标签表示的重要性。然而,标签语化器已经被证明在少量文本分类中是有效的(Schick和Schutze 2021),其中语化器旨在减少模型输出和标签词之间的差距。为了减轻构建手动语言分析器所需的专业知识和工作量,Gao等人(Gao, Fisch, and Chen 2021)设计了基于搜索的方法,以便在训练优化过程中更好地选择语言分析器。其他一些研究(Hambardzumyan, Khachatrian, May 2021;Cui等人(2022)提出了可训练向量作为软语言器来取代标签词,从而消除了搜索整个字典的困难。
因此,我们引入可训练向量来替代多模态提示中的标签词。我们的方法旨在将下游数据集中的标签表示与预训练的VL模型对齐,减少下游数据集和VL- ptms之间类别描述的差异。
方法
在本节中,我们将介绍如何将我们提出的LAMM无缝地纳入CLIP,同时伴随着我们的分层损失。LAMM的整个体系结构和层次排列如图2所示。
图2:LAMM的整体架构。我们用可训练的向量替换下游数据集中的类别令牌,并结合分层损失来保持CLIP对每个类别的泛化能力。灰框表示提示模板和冻结模型,蓝框表示原始标签嵌入/特征/logits,黄色框表示训练过程中的标签嵌入/特征/logits。
CLIP的简要介绍
CLIP是一个VL-PTM,包括一个视觉编码器 ϕ \phi ϕ和一个文本编码器 ψ \psi ψ。这两个编码器分别提取图像和文本信息,并将它们映射到公共特征空间 R d R^d Rd,两个特征空间对齐良好。
给定输入图像 x x x,图像编码器将提取相应的图像表示 I x = ϕ ( x ) I_x=\phi(x) Ix=ϕ(x)。对于每个下游数据集,将有 k k k个类,每个类将填充在一个手动提示模板中,例如“a photo of < class >”。然后文本编码器将生成特征,对每个类别的表示进行进一步处理,得到每个类别的特征。在训练过程中,CLIP最大化图像表示与其对应类别表示之间的余弦相似度,同时最小化不匹配对之间的余弦相似度。在zero-shot推理中,第 i i i类的预测概率计算为:

其中 τ \tau τ为CLIP获取的温度参数,函数cos为余弦相似度。
标签对齐
虽然CLIP具有较强的zero-shot性能,但是为下游任务提供相应的文本描述可以有效地增强CLIP的zero-shot和few-shot识别能力。以往对文本模板的提示调优工作主要集中在对“a photo of”的训练上,而忽略了对“”的优化。为了有效地将下游任务中的类标签与预训练模型对齐,我们提出了LAMM,它通过端到端训练自动优化标签嵌入。我们以CLIP为例,CLIP上的LAMM仅对下游任务的类嵌入表示进行微调。这样,LAMM的提示模板转换为:
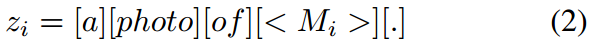
其中 < M i > ( i = 1 , 2 , … , k ) <M_i>(i=1,2,\ldots,k) <Mi>(i=1,2,…,k)表示第 i i i类的可学习标记。与式1类似,LAMM的预测概率计算为:
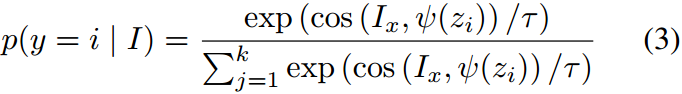
在训练过程中,我们只更新每个下游数据集中的类别向量 { < M i > } i = 1 k \{<M_i>\}^k_{i=1} {<Mi>}i=1k,这将减少图像表示与其对应的类别表示之间的差距。
此外,LAMM可以应用于现有的多模态提示方法。以CoOp为例,CoOp和普通CLIP之间的区别是用M个可学习的token替换提示模板。因此,CoOp+LAMM的提示模板为:

通过用可训练向量替换类表示,我们可以将我们的方法集成到任何现有的多模态提示方法中。
分层的损失
对齐良好的特征空间是增强CLIP的zero-shot能力的关键,也有利于下游任务的学习。由于LAMM不引入对CLIP模型参数的任何修改或添加,对齐特征空间内的图像表示保持固定,而每个类别的可训练嵌入改变了特征空间内的文本表示。然而,单个文本表示对应于下游数据集中给定类别的多个图像,尽管整个训练过程是在few-shot设置下进行的。这种情况可能会导致可训练类嵌入对训练集中有限数量的图像的过度拟合。因此,我们提出了一种分层损失(HL)来保证在参数空间、特征空间和logits空间中的泛化能力。纳入损失函数的基本原理是确保我们的模型与高度适应性的zero-shotCLIP模型保持一致,该模型在不同维度上展示了强大的泛化能力。
参数空间
为了降低模型过度拟合的风险,许多机器学习技术采用参数正则化来提高在未看过样本上的泛化能力。在这方面,采用权重合并(WC) (Kirkpatrick et al . 2017)损失方法如下:
其中 θ \theta θ为当前模型的可训练参数, θ ˉ \bar \theta θˉ为参考参数。在LAMM中, θ \theta θ表示可训练的标签嵌入,而 θ ˉ \bar \theta θˉ表示原始标签嵌入。虽然参数正则化可以解决过拟合的问题,但过度的正则化可能会阻碍模型充分捕获训练数据中存在的特征和模式的能力。我们设置 L W C L_{WC} LWC的系数(me:这个系数应该是指 λ 1 = 1 / n \lambda_1=1/n λ1=1/n)与训练-shot的数量成反比,这表明在参数空间内,更少的shot将伴随着更严格的正则化过程。
特征空间
除了参数空间之外,我们训练的类别的文本特征与训练图像的特征保持一致也是至关重要的。在训练过程中,我们训练类别的文本特征逐渐向训练图像中呈现的特征收敛。然而,如果特定类别的少数训练图像的表示与整个图像数据集的表示不一致,则可能导致标签语义过度拟合到特定样本。例如,考虑图2中所示的“美洲驼”图像的标签嵌入。标签嵌入可能与背景草信息过拟合,即使在所有情况下羊驼可能并不总是与草相关联。为了减轻每个类别的文本特征的过拟合,我们使用文本特征对齐损失来限制文本特征的优化区域。从先前在语义层面的相似度研究中获得灵感(Gao, Yao, and Chen 2021),我们采用余弦相似度损失进行对齐。在此方法中,对于式2中的类别模板 z i z_i zi,由式1中的原始提示模板 y i y_i yi作为其优化区域的中心。余弦损失公式如下:
Logits Space
CLIP强大的泛化能力对多模态提示方法在few-shot场景下的有效性起着至关重要的作用。虽然前两种损失通过参数和特征空间的正则化增强了LAMM的泛化能力,但与zero-shot CLIP相比,我们希望最小化图像表示和不同文本表示之间logits的分布移位。因此,我们在分类逻辑空间中引入了知识蒸馏损失,允许将泛化知识从CLIP转移到LAMM。蒸馏损失可表示为:
全部损失
为了训练LAMM进行下游任务,将交叉熵(CE)损失应用于相似性得分,与微调CLIP模型相同:
其中 τ \tau τ是预训练过程中学习到的参数。这样,总损失为:
L = L C E + λ 1 ∗ L W C + λ 2 ∗ L C O S + λ 3 ∗ L K D L=L_{CE}+\lambda_1*L_{WC}+\lambda_2*L_{COS}+\lambda_3*L_{KD} L=LCE+λ1∗LWC+λ2∗LCOS+λ3∗LKD
其中 λ 1 , λ 2 , λ 3 \lambda_1,\lambda_2,\lambda_3 λ1,λ2,λ3是超参数。为了防止调整参数的冗余,我们将所有实验的经验值设置为 λ 1 = 1 / n , λ 2 = 1 , λ 3 = 0.05 \lambda_1=1/n,\lambda_2=1,\lambda_3=0.05 λ1=1/n,λ2=1,λ3=0.05,其中 n n n表示训练是shot的个数。
实验
Few-shot Settings
**数据集 **我们使用了之前作品中使用的数据集(Zhou et al . 2022b;Khattak et al . 2022),并在11个图像分类数据集上评估我们的方法,包括Caltech101 (Fei-Fei, Fergus, and Perona 2007), ImageNet (Deng et al . 2009), OxfordPets (Parkhi et al .)2012),斯坦福汽车(Krause等人2013),Flowers102 (Nilsback和Zisserman 2008), Food101 (Bossard, Guillaumin和Gool 2014), FGVCAircraft (Maji等人2013),SUN397 (Xiao等人2010),UCF101 (Soomro, Zamir和Shah 2012), DTD (Cimpoi等人2014)和EuroSAT (Helber等人2019)。此外,我们遵循(Radford et al . 2021;Zhou et al . 2022b)为我们的少镜头学习实验建立了少镜头评估方案。具体来说,我们分别使用1、2、4、8和16个镜头进行训练,并在完整的测试集上对模型进行评估。所有实验结果均为种子1、2、3实验结果的平均值。
Baselines 我们比较LAMM、CoOp和MaPLe的结果。此外,我们还将LAMM引入CoOp和MaPLe中,以证明LAMM的兼容性。为了保持公平的受控实验,我们实验中的所有提示模板都是从“a photo of ”初始化的。此外,由于MaPLe只能用于基于变压器的VL-PTMs,因此本文采用的预训练模型为vitb /16 CLIP。我们将每个模型的训练参数(例如,学习率,epoch和其他提示参数)保持在原始设置中,其中CoOp的epoch为50,MaPLe为5。对于vanilla CLIP + LAMM,我们遵循CoOp的设置。我们所有的实验都是在一台NVIDIA A100上进行的。在我们的工作中,相应的超参数在所有数据集中都是固定的。此外,根据不同的训练镜头和数据集调整参数可以提高性能。
与最先进方法的比较
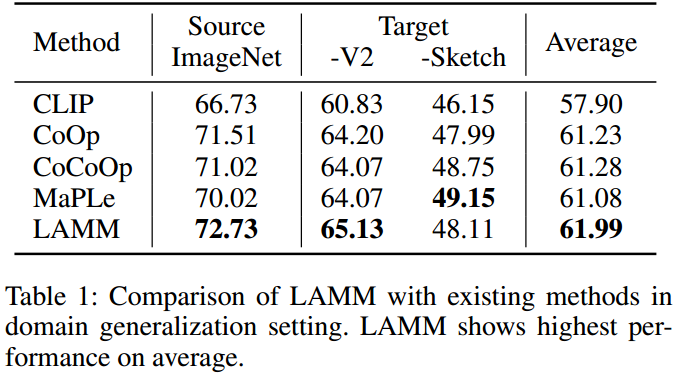
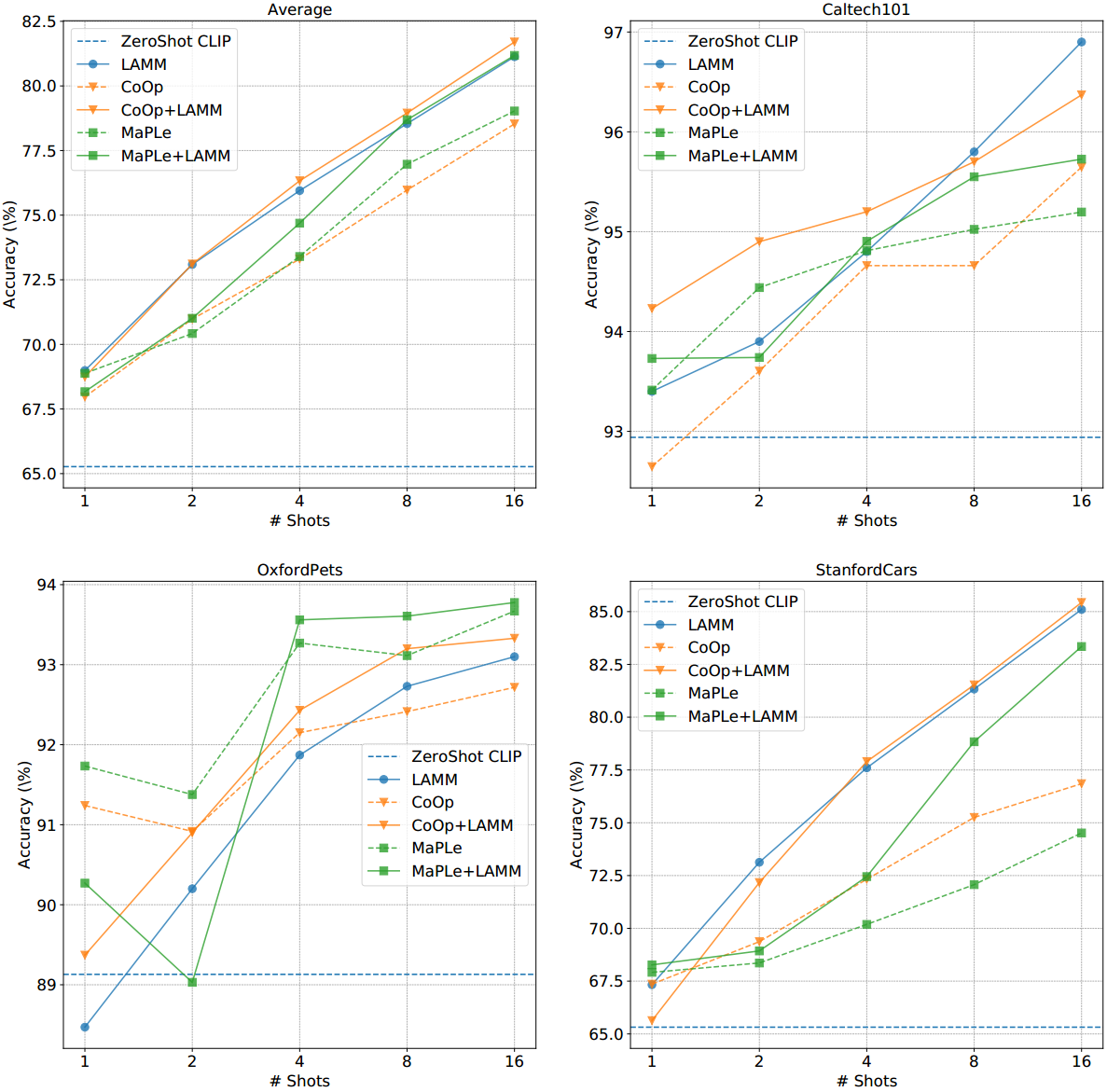
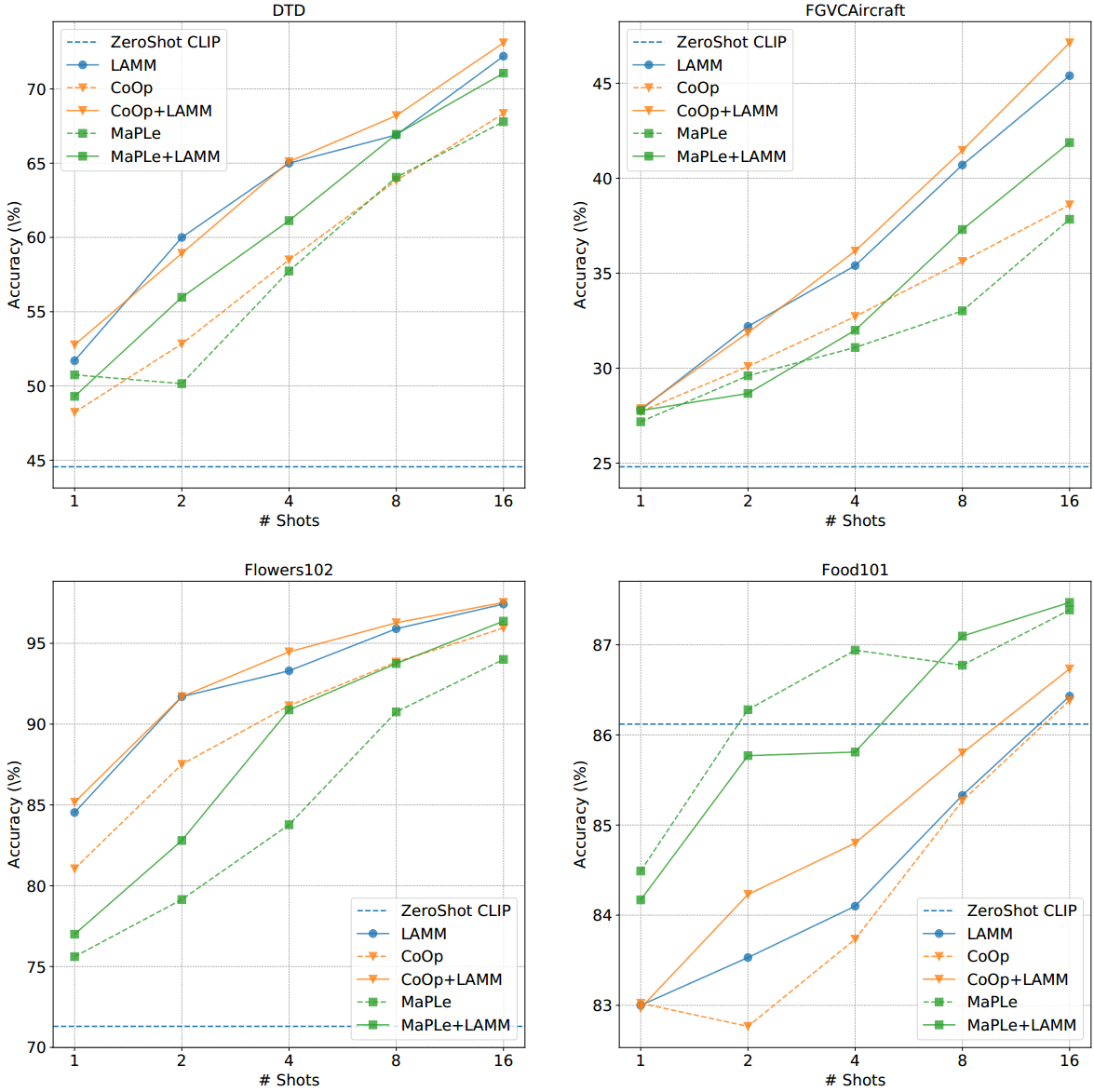
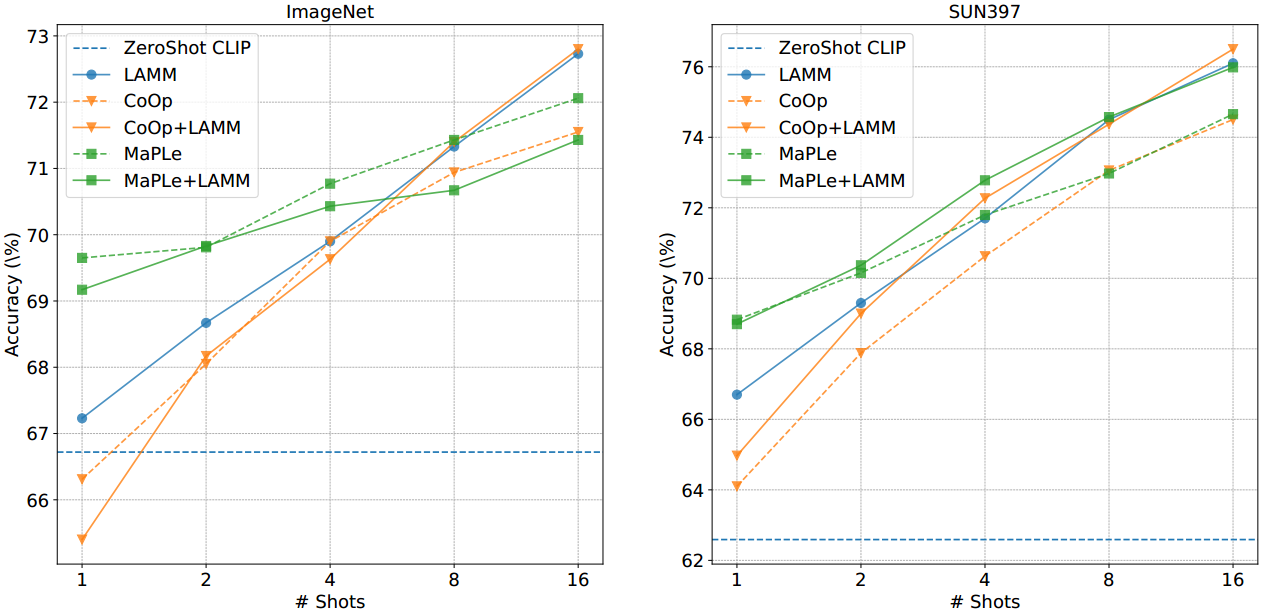

图3:在few-shot学习设置下,11个数据集的主要结果。我们报告在三次跑动中1/2/4/8/16-shot的平均准确率(%)。总体而言,所提出的LAMM增强了CLIP、CoOp和MaPLe的性能。
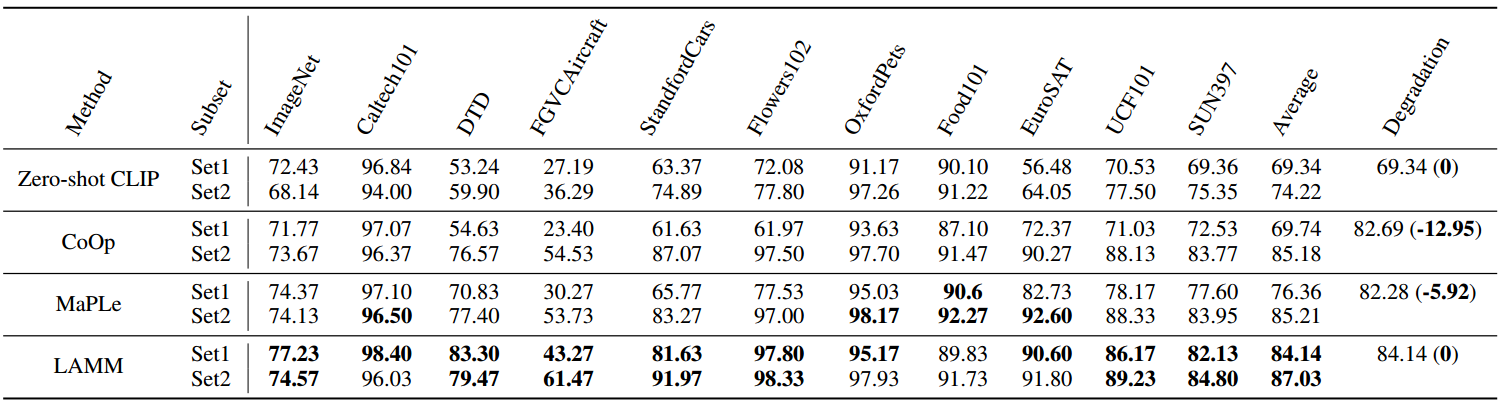
表2:LAMM与其他提示方式对16-shots增量学习效果的比较。首先,在Set 1上训练模型,然后在Set 2上训练模型。括号内的“Degradation”表示在Set 2上进一步训练后,在Set 1上的评价结果下降。
除了从基础到新的测试,增量学习也是一个重要的问题,当目标是扩大模型的知识库。根据MaPLe,我们将数据集划分为基类和新类,将基类指定为Set 1,将新类指定为Set 2。最初,每个模型都在Set 1上进行训练,之后继续在Set 2上进行训练。最后,我们评估了每个模型在Set 1和Set 2上的性能。结果如表2所示。“退化”一词是指在第2组上进行增量训练之前和之后,在第1组上的表现差异。这种下降代表了在增量学习过程中对先前任务的遗忘。
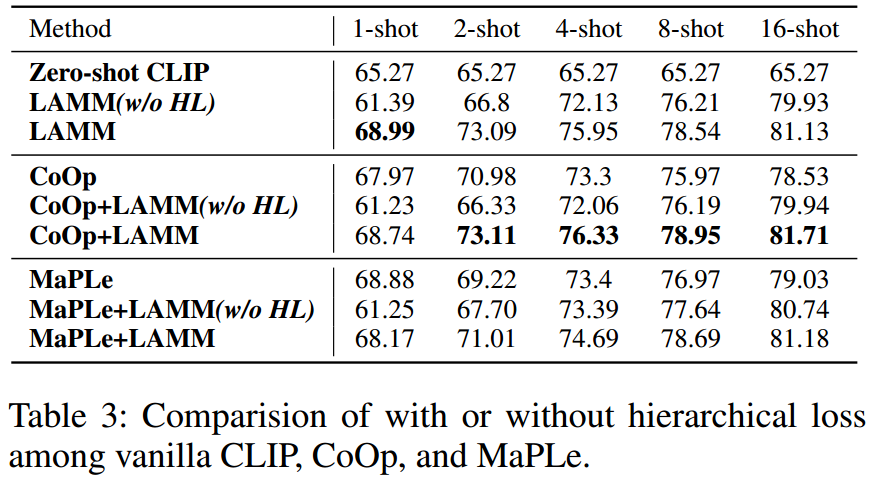
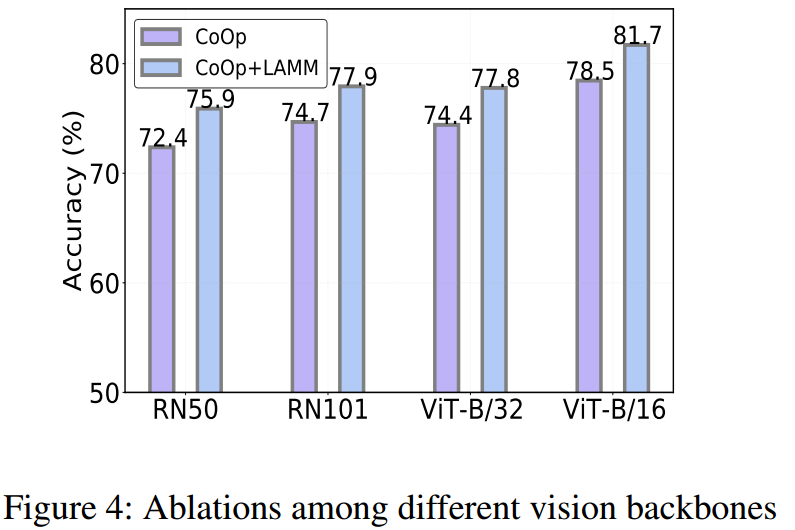
烧融实验
结论
与传统的少样本学习方法相比,基于VL-PTMs的提示学习在下游任务中表现出较强的可转移性。我们的研究表明,除了提示模板学习之外,减少VL-PTMs与下游任务标签表示之间的差距也是一个重要的研究问题。本文对如何以即插即用的方式将下游任务中的标签表示与VL-PTMs对齐进行了全面的研究。我们提出的LAMM已经证明了以前的多模态提示方法在少样本场景下的性能有显着改善。特别是,通过简单地将LAMM合并到vanilla CLIP中,我们可以获得比以前的多模态提示方法更好的结果。
LAMM在非分布情况下也表现出鲁棒性,以及它在增量学习过程中的优越性。这些发现进一步证明了优化VL-PTMs转移到下游任务的巨大潜力,不仅限于图像识别,还包括视觉语义任务,如图像分割、目标检测等。我们希望从标签表示学习中获得的见解将有助于开发更有效的VL-PTMs迁移方法。
参考资料
文章下载(AAAI 2024)
https://arxiv.org/abs/2312.08212