一直以来,支持LLM的观点之一是模型可以集成海量事实知识,作为通往「世界模拟器」的基础。虽然也有不少反对意见,但缺乏实证依据。
那么,LLM能否作为世界模拟器?
最近,亚利桑那大学、微软、霍普金斯大学等机构联合发布了一篇论文,从实证角度否定了这一观点。
最新研究已被ACL 2024顶会接收。

研究发现,GPT-4在模拟基于常识任务的状态变化时,比如烧开水,准确度仅有60%。
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952
论文认为,尽管GPT-4表现惊艳,但如果没有进一步创新,它不能成为可靠的世界模型。
为了量化LLM的规划能力,作者提出了一个全新的基准测试——bytesized32-state-prediction,并在上面运行了GPT-4模型。
基准测试的代码和数据已在GitHub上开源,帮助未来研究继续探查LLM的能力优缺点。
一向对自回归语言模型无感的LeCun也转发了这篇论文。
尽管如此,只凭一篇论文难以平息LLM界的重大分歧。
模拟世界对于AI学习和理解世界至关重要。
以往,多数情况下,可用模拟的广度和深度受到现实的限制,因为需要人类专家耗费数周甚至数月的时间做大量工作。
而现在,大模型提供了一种替代方法,通过预训练数据集中大量知识,获得对世界的深刻理解。
但是,它们准备好直接用作模拟器了吗?对此,研究团队在「文本游戏」这一领域检验了这一问题。
一般来说,在世界建模和模拟的背景下,应用LLM有两种方式:一是神经符号化方法,二是直接模拟。
论文中,作者们首次对LLM直接模拟虚拟环境的能力进行了量化分析。
他们利用JSON模式的结构化表示作为脚手架,不仅提高了模拟精度,还可以直接探查LLM在不同领域的能力。
结果发现,GPT-4普遍无法捕捉与智能体行为无直接关联的「状态转移」(state transition)。
01 研究方法
在文本环境中,智能体通过自然语言完成特定目标。研究人员将文本的虚拟环境形式化,建模为一种部分可观测马尔可夫决策过程(POMDP),包含7个元组:S, A, T, O, R, C, D。
- S表示状态空间
- A表示行动空间
- T:S×A→S表示状态转移函数
- O表示观测函数
- R:S×A→R表示奖励函数
- C表示用自然语言描述目标和动作语义的「上下文信息」
- D:S×A→{0,1}表示二元指示函数,用0或1标记智能体是否完成任务
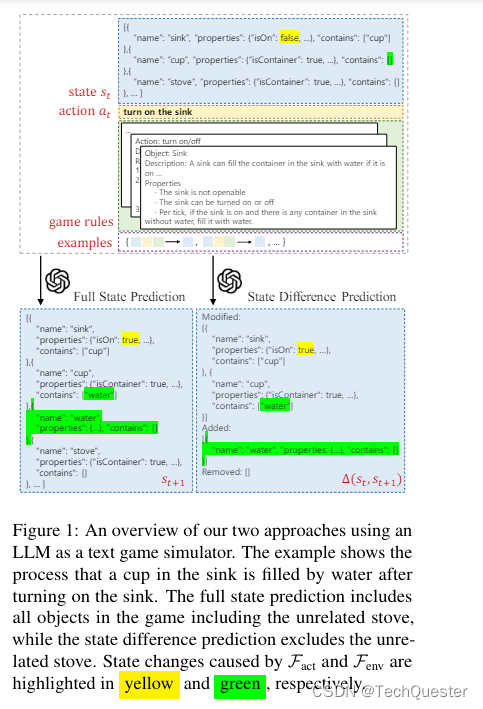
上下文C为模型提供了除环境外的额外信息,比如行动规则、物体属性、打分规则和状态转换规则等。
研究人员提出了一个预测任务,称为LLM-as-a-Simulator(LLM-Sim),作为定量评估大模型作为可靠模拟器的能力的方法。LLM-Sim任务定义为实现一个函数,将给定的上下文、状态和动作映射到后续的状态、奖励和任务完成状态。
每个状态转移用如下的九元组表示:

实际上,整个状态转换模拟器F,应该考虑两种类型的状态转移:行为驱动和环境驱动的转移。
例如,行为驱动的状态转移是在执行「打开水槽」动作后,水槽被打开。而环境驱动的转移是,当水槽打开时,水将填满槽中的杯子。
此外,LLM的预测模式也分为两种:预测下一步的完整状态,或者预测两个时刻之间的状态差。
为了更好地理解LLM对于每种状态转移的建模能力,研究人员进一步将模拟器函数F分解为三种类型:
02 评估结果
建模了LLM的决策过程后,作者用文本构建了一个虚拟人物场景。Bytesized32-SP基准测试的数据来源于公开的Bytesized32语料库,其中有32个人类编写的文字游戏。留出一个游戏作为gold label后,测试集总共涉及31个游戏场景,7.6万多个状态转换。
LLM根据上下文和前一个状态进行单步预测,给出下一步时的物体属性、任务进展等信息。规则方面,研究人员提出了三种设定:由游戏作者撰写、由LLM自动生成,或者根本不提供规则。设定好虚拟环境和任务规则后,作者运行GPT-4进行预测,得到了如下结果。
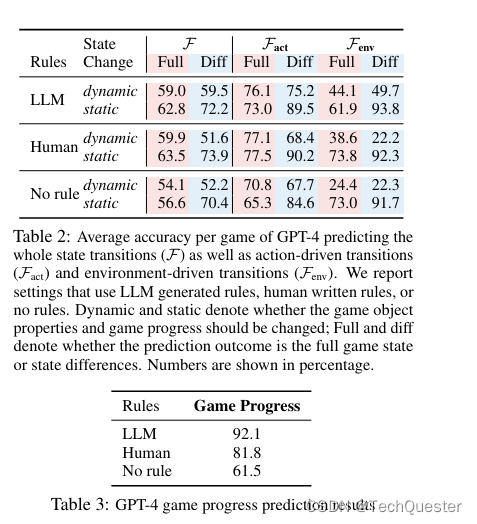
为了严谨起见,作者根据状态转移前后预测结果是否变化,分成static和dynamic两类分开统计。如果前后两个状态中,结果并没有发生变化,LLM也会更容易预测。不出意料,static一栏的准确率基本都高于dynamic。
对于「静态」转移,模型在预测状态差时表现更好。「动态转移」则相反,在完整状态预测中得分更高。作者猜测,这可能是由于预测状态差时需要减少潜在的格式错误,这会为任务输出带来额外的复杂性。
还可以看到,预测动作驱动的状态转移的准确率往往高于环境驱动类。在dynamic栏,前者预测最高分有77.1,而后者最高只有49.7。
此外,游戏规则的制定会很大程度上影响LLM的表现。如果不提供游戏规则,LLM预测的性能会显著下降,但规则由人类制定或LLM自动生成并不会显著影响准确率。相比之下,规则制定对游戏进度预测的影响更加明显。相比人类规则,LLM生成规则时,GPT-4的预测有超过10个百分点的提升。
对于规划任务中的单步预测模型,每一步的模拟误差都会累积并向后传播,单步的低性能会很大程度上影响全局表现。因此,LLM较低的准确率说明了它并不能成为可靠的「文本世界模拟器」。
此外,人类准确率的波动幅度基本不大,说明任务设定比较简单、直接,适合人类的思维模式。GPT-4这种较差的性能表现给我们提供了一个宝贵的机会,可以更具体地剖析LLM究竟在哪方面出现了能力缺陷。
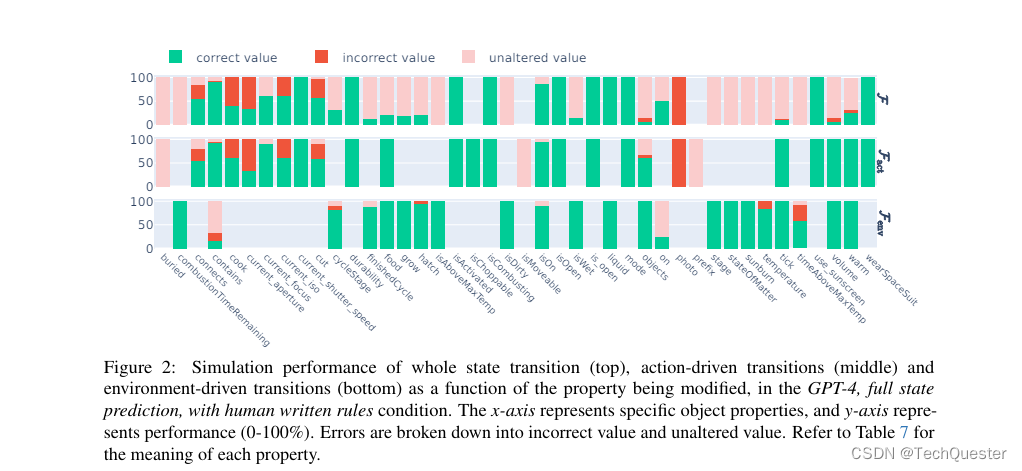
论文作者将LLM的预测结果拆开仔细分析,发现在二元布尔值属性上(is开头的属性),模型通常可以做得很好。
如何使用WildCard正确方式打开GPT-4o,目前 WildCard 支持的服务非常齐全,可以说是应有尽有!
官网有更详细介绍:WildCard

推荐阅读:
更强大Mamba-2正式发布啦!!!