作者:来自 Elastic Martijn Van Groningen, Kostas Krikellas
背景
Elasticsearch 最近投资了对存储和查询时间序列数据的更好支持。存储效率一直是关注的主要领域,许多项目取得了巨大的成功,与将数据保存在标准索引中相比,可以节省高达 60-80% 的成本。在某些情况下,我们的系统实现了每个数据点不到一个字节的存储效率,与最先进的专业 TSDB 系统相媲美。
在本文中,我们描述了我们的时间序列产品中包含的最有影响力的存储改进,并深入了解了我们期望我们的系统在存储效率方面表现更好和更差的场景。
存储改进
合成源(synthetic source)
Elasticsearch 默认将原始 JSON 文档主体存储在 _source 字段中。这种重复会降低存储效率,使指标收益递减,因为通常通过不使用此字段的聚合查询来检查指标。为了缓解这种情况,我们引入了合成 _source(synthetic source),它使用存储在文档字段中的数据按需重建原始 _source 的风格。需要注意的是,支持的字段类型数量有限,并且 _source 合成比从存储字段中检索要慢。不过,这些限制对于主要依赖关键字、数字、布尔值和 IP 字段并使用不考虑 _source 内容的聚合查询的指标数据集来说基本上无关紧要。我们正在单独努力消除这些限制,使合成源适用于任何映射。
存储优势立竿见影且显而易见:启用合成源可将 TSDS 索引的大小减少 40-60%(有关性能评估的更多信息,请参见下文)。因此,自从 TSDS 发布(v.8.7)以来,它默认使用合成源。
专用编解码器
TSDB 系统大量使用专用编解码器,利用记录指标的时间顺序来减少每个数据点的字节数。我们的产品扩展了标准 Lucene 编解码器,支持运行长度编码(run-length encoding)、delta-of-deltas(二阶导数)、GCD 和数值的 XOR 编码。编解码器是在 Lucene 段级别指定的,因此较旧的索引可以在索引新数据时利用最新的编解码器。
为了提高这些压缩技术的效率,索引按在所有维度字段(dimension fields)上计算的标识符排序(升序),然后按时间戳排序(降序,以返回每个时间序列的最新数据点)。这样,维度字段(主要是关键字)就可以使用运行长度编码进行有效压缩,而指标的数值则按时间序列进行聚类并按时间排序。由于大多数时间序列随时间变化缓慢,偶尔会出现峰值,并且 Elasticsearch 依赖于 Lucene 的垂直分区存储引擎,因此这种方法可以最大限度地减少连续存储数据之间的差异并提高存储效率。
元数据修剪
_id 字段是用于唯一标识 Elasticsearch 中每个文档的元数据字段。它对于指标应用程序的价值有限,因为时间序列分析依赖于随时间聚合值的查询,而不是检查单个指标值。为此,TSDS 修剪了存储的值,但保留了此字段的倒排索引,以仍然支持文档检索查询。这可以减少 10-20% 的存储量,而不会损失功能。
生命周期集成
TSDS 可以与数据生命周期管理机制(即 ILM 和数据流生命周期)集成。这些工具会自动删除较旧的索引,而 ILM 还支持随着索引老化将索引移动到存储成本更低的层(例如使用旋转磁盘或存档云存储)。生命周期管理可降低存储成本,而不会影响频繁访问指标的查询性能,并且只需极少的用户参与。
降采样 - Downsampling
在许多指标应用中,最好只在短期内保留细粒度数据(例如,过去一周的每分钟数据),并且可以接受增加旧数据的粒度以节省存储空间(例如,过去一个月的每小时数据,过去两年的每日数据)。降采样将原始指标数据替换为可配置时间段内(例如,每小时或每天)预聚合指标的统计表示。这既提高了存储效率,因为降采样索引的大小只是原始指标索引的一小部分,也提高了查询性能,因为聚合查询会扫描预聚合结果,而不是在原始数据上即时计算它们。
降采样与 ILM 和 DSL 集成,可自动执行其应用,并允许降采样数据随着时间推移具有不同的分辨率。
测试结果
TSDS 存储增益
我们通过每晚的基准测试来跟踪 TSDS 的性能,包括存储使用情况和效率。TSDB track(参见磁盘使用情况可视化)可视化了我们的存储改进的影响。接下来,我们将介绍 TSDS 发布之前的存储使用情况、TSDS 正式发布后存储使用情况的改进情况以及当前状态。
TSDB 轨道的数据集(k8s 指标)有九个维度字段,每个文档平均包含 33 个字段(指标和维度)。索引包含 116,633,696 个文档的一天指标。
在 ES 8.7 版之前对 TSDB 轨道的数据集进行索引需要 56.9GB 的存储空间。有趣的是,将其按元数据字段、时间戳字段、维度字段和指标字段进行细分,以深入了解存储使用情况:
| Field name | Percentage |
|---|---|
_id |
5.1% |
_seq_no |
1.4% |
_source |
78.0% |
@timestamp |
1.31% |
| Dimension fields | 2.4% |
| Metric fields | 5.1% |
| Other fields | 9.8% |
_source 元数据字段是迄今为止存储空间最大的贡献者。如前所述,合成源是我们为提高存储效率而进行的度量工作所推动的改进之一。这在 ES 8.7 中很明显,它默认使用合成源作为 TSDS。在这种情况下,存储空间下降到 6.5GB - 存储效率提高了 8.75 倍。按字段类型细分:
| Field name | Percentage |
|---|---|
_id |
18.7% |
_seq_no |
14.1% |
@timestamp |
12.6% |
| Dimension fields | 3.6% |
| Metric fields | 12.0% |
| Other fields | 50.4% |
改进的原因是不再存储 _source,以及应用索引排序按顺序存储来自同一时间序列的指标,从而提高标准 Lucene 编解码器的效率。
使用 ES 8.13.4 索引 TSDB 轨道的数据集占用 4.5GB 存储空间 - 进一步提高了 44%。按字段类型细分如下:
| Field name | Percentage |
|---|---|
_id |
12.2% |
_seq_no |
20.6% |
@timestamp |
14.0% |
| Dimension fields | 1.6% |
| Metric fields | 6.7% |
| Other fields | 58.6% |
与 8.7.0 版本相比,这是一个重大改进。最新迭代的主要贡献因素是 _id 字段占用的存储空间更少(其存储的值被修剪),而维度字段和其他数字字段使用最新的时间序列编解码器得到更高效的压缩。
现在,大部分存储归因于 “Other fields”,即提供与维度类似的上下文但不用于计算用于索引排序的标识符的字段,因此它们的压缩效率不如维度字段。
降采样存储增益
降采样以查询分辨率换取存储增益,具体取决于下采样间隔。使用 1 分钟间隔对 TSDB 轨道数据集中的指标(每 10 秒收集一次指标)进行下采样可产生 748MB 的索引 - 提高了 6 倍。缺点是指标以每分钟的粒度进行预聚合,因此不再可能检查单个指标记录或以亚分钟间隔(例如每 5 秒)进行聚合。最重要的是,预先计算的统计数据(最小值、最大值、总和、计数、平均值)的聚合结果与对原始数据计算的结果相同,因此下采样不会产生任何准确性成本。
如果可以容忍较低的分辨率并使用每小时间隔对指标进行下采样,则生成的下采样索引将仅使用 56MB 的存储空间。请注意,改进幅度是 13.3 倍,即低于从每分钟降采样间隔切换到每小时降采样间隔所预期的 60 倍。这是因为所有索引都需要为每个段存储额外的元数据,这是一个恒定的开销,随着索引大小的减小,开销会变得更加明显。
综合起来
下图显示了存储效率在各个版本中的变化情况,以及降采样可以带来哪些额外的节省。请注意,纵轴是对数刻度。
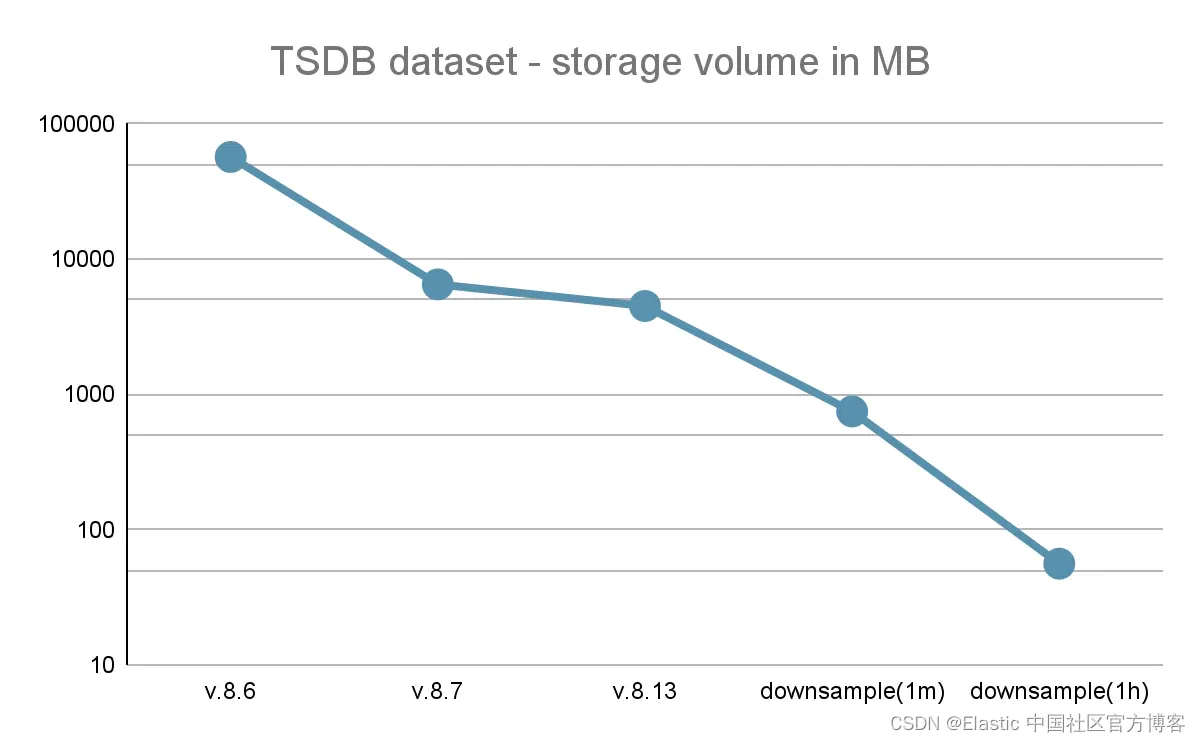
总体而言,与之前的版本相比,我们的指标产品的存储效率提高了 12.5 倍。如果我们通过降采样来减少存储空间,以牺牲分桶分辨率,那么存储效率甚至可以达到 1000 倍甚至更高。
配置提示
在本节中,我们将探讨配置 TSDS 并考虑存储效率的最佳实践。
尽量在每个文档中包含多个指标
虽然 Elasticsearch 使用垂直分区来单独存储每个字段,但字段在文档中仍然按逻辑分组。由于指标共享包含在同一文档中的维度,因此当我们在每个索引文档中包含尽可能多的指标时,维度和元数据的存储开销会得到更好的摊销。另一方面,在每个文档中存储单个指标及其相关维度会最大化维度和元数据的开销并导致存储膨胀。
更具体地说,我们使用合成数据集来量化每个文档指标数量的影响。当我们在每个索引文档中包含所有指标(20 个)时,TSDS 每个数据点仅使用 0.9 字节 - 接近最先进的专用指标系统(每个数据点 0.7 字节)的性能,这些系统缺乏 Elasticsearch 对非结构化数据的丰富索引和查询功能。相反,当每个索引文档只有一个指标时,TSDS 每个数据点需要 20 个字节,存储空间大幅增加。因此,将每个索引文档中尽可能多的指标组合在一起并共享相同的维度值是值得的。
削减不必要的维度
Elasticsearch 架构允许我们的指标产品以可控的性能成本,以百万级或更多的量级扩展,从而实现远超竞争系统的可扩展性。尽管如此,维度确实占用了相当大的空间,而高基数会降低 TSDS 压缩技术的效率。因此,重要的是要仔细考虑指标的索引文档中包含哪些字段,并积极地将维度修剪为仪表板和故障排除所需的最小集合。
这里有一个有趣的例子,即可观察性映射,其中包括一个 IP 字段,该字段最终包含托管机器的最多 16 个 IP(v4、v6)地址。它对存储占用空间和索引吞吐量都产生了重大影响,而且几乎没有使用。用机器标签替换它可以大大改善存储,而不会损失可调试性。
使用生命周期管理
ILM 有助于将较旧的、不经常访问的数据移动到更便宜的存储选项,并且 ILM 和 Data Stream Lifecycle 都可以处理指标数据老化后的删除。这种全自动方法可以在不更改索引映射或配置的情况下降低存储成本,因此非常值得鼓励。
更重要的是,随着数据老化,值得考虑通过降采样来交换指标分辨率以换取存储。这种技术可以带来巨大的存储优势和响应更快的仪表板,假设存储桶分辨率的降低对于较旧的数据是可以接受的 - 这是实践中常见的情况,因为以每分钟的粒度检查几个月前的数据是相当罕见的。
下一步
过去几年,我们在指标的存储空间方面取得了显著的改进。我们打算将这些优化应用于指标以外的其他数据类型,特别是日志数据。虽然有些功能是指标特定的,例如降采样,但我们仍希望使用日志特定的索引配置将存储量减少 2-4 倍。
尽管减少了所有 Elasticsearch 索引所需的元数据字段的存储开销,但我们计划更积极地削减它们。_id 和 _seq_no 字段是不错的选择。此外,还有机会将更高级的索引技术(例如稀疏索引)应用于时间戳和支持范围查询的其他字段。
如果可以接受较小的存储损失,降采样机制具有很大的提高查询性能的潜力。一个想法是在重叠的时间段内支持多种降采样分辨率(例如原始值、每小时和每天),查询引擎会自动为每个查询选择最合适的分辨率。这将允许用户指定下采样以匹配其仪表板时间缩放并使其响应更快,以及在索引后几分钟内启动降采样。它还将解锁在降采样的同时保留原始数据,可能使用更慢/更便宜的存储层。
试用
- 如果你还没有账户,请注册 Elastic Cloud
- 配置 TSDS 并使用它来存储和查询指标
- 探索降采样(downsampling)以查看它是否适合你的用例
- 享受存储节省
准备好自己尝试了吗?开始免费试用。
想要获得 Elastic 认证?了解下一次 Elasticsearch 工程师培训何时举行!
原文:Time-series data: Elasticsearch storage efficiency — Elastic Search Labs