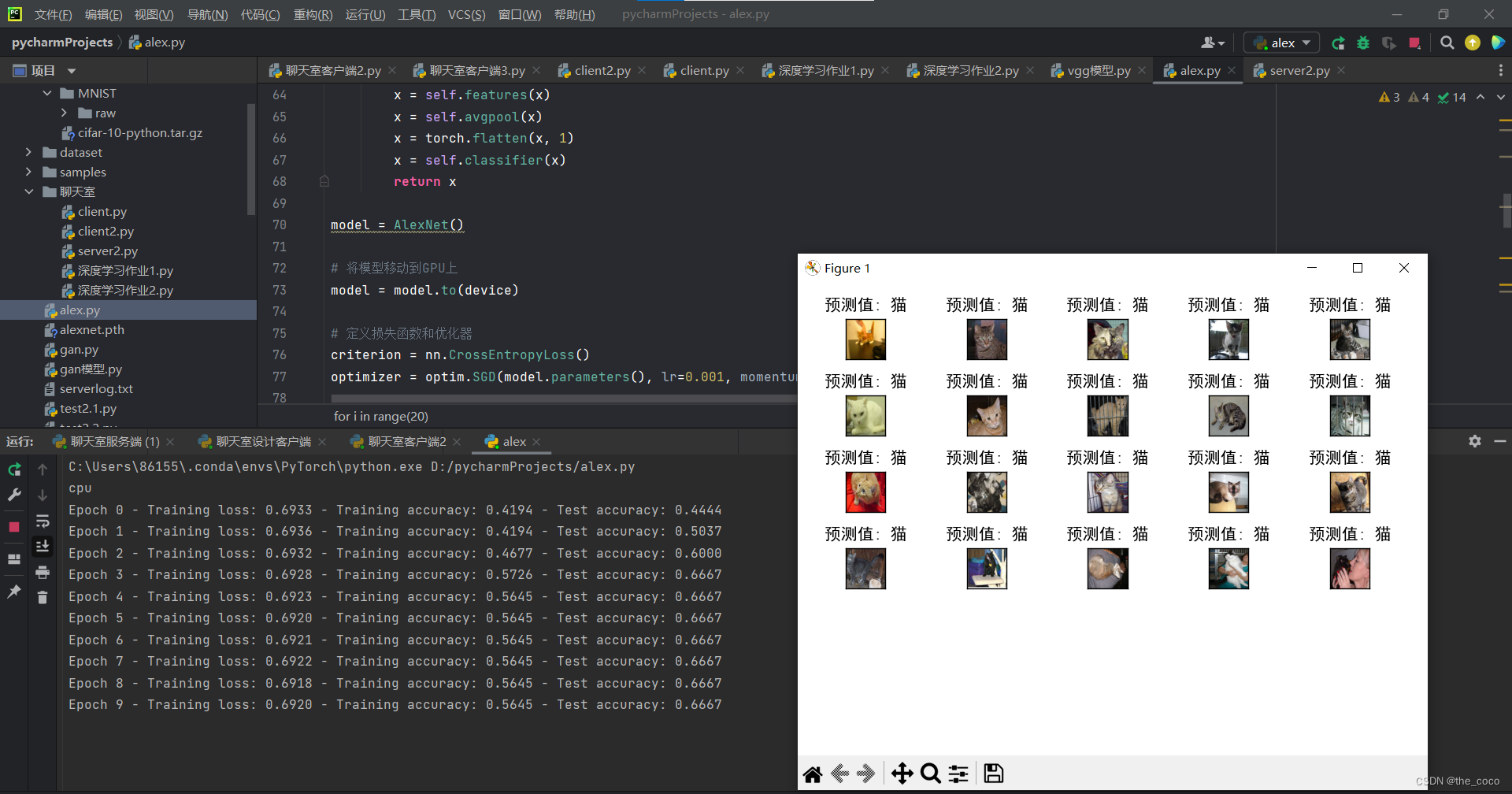
Pytorch 猫狗分类
用Pytorch框架,实现分类问题,好像是学习了一些基础知识后的一个小项目阶段,通过这个分类问题,可以知道整个pytorch的工作流程是什么,会了一个分类,那就可以解决其他的分类问题,当然了,其实最重要的还是,了解她的核心是怎么工作的。
那首先,我们的第一个项目,就做猫狗的分类。
声明:整个数据和代码来自于b站,链接:使用pytorch框架手把手教你利用VGG16网络编写猫狗分类程序_哔哩哔哩_bilibili
我做了复现,并且记录了自己在做这个项目分类时候,一些所思所得。
目前,我需要掌握pytorch针对于分类问题,解决整个分类问题的工作流程是怎么样的,其他的进阶,需要自己去不断的练习和体会。因为,分类问题也是,计算机视觉想要解决的一个重要问题,而且,对于yolo系列,直接解决了分类问题,所以,现在理解好基础的,以后就能更好的理解大佬们的框架,才知道怎么去优化网络。
前面说到,通过softmax函数,把分类问题,转换成了概率问题,把给你一个图片,神经网络回答我是什么的问题,转变成了,给你一个图片,神经网络输出,是什么类别的概率是什么的问题。而神经网络的整个训练过程,也是w在不断被训练的一个动态过程,最后,我们会训练出一个较好的w,输入图片,神经网络就能告诉我们是什么类别了。
那现在,就从数据开始吧。
数据清洗
拿到数据,首先要分析数据集是什么样子的,包括,数据集包含了什么图片,每张图片的命名时怎么样的?
现在,我们有很多猫和狗的照片,存放在train文件夹下面,猫照片,狗照片,分别存在cat和长这样:
再点开dog文件夹:
首先,要根据这两类照片,去生成一个标签文件,具体步骤是这样:
先遍历这两个数据集,遍历的意思是,相当于你打开照片的文件夹,把照片,一张一张的拿出来,然后把每个照片归好类,比如,第二个dog文件夹里面,你拿出第一张,标记是狗,记录下来类别和这张狗照片的路径位置,记录在一个txt文档里面,这就是,到时候训练的时候,提供给trian的一个label文件,这个label文件,告诉网络,我现在给你一张照片,记住,他是一只狗,你来训练吧。就按照这个逻辑,把很多张狗的照片,猫的照片,都喂给网络,让他训练,说到训练,训练的其实是w,就是权重,把权重w训练好了,我们希望到时候,给他随便一个猫或者狗的照片,网络能告诉我,这是一只狗还是一只猫。
那现在,就开始,准备标签文件。
刚说到,想象一下,我们从某个文件夹拿出来一张一张的照片,那就用getcwd函数,获取当前的工作目录。
1、导入包
Import os
from os import getcwd
【拓展:获取当前工作目录】
import os
current_directory = os.getcwd()
print("当前工作目录是:", current_directory)
2、指定照片的类别
classes=['cat','dog']#所有类别,放进列表,这个好处是可以修改,往里面添加或者删除就好了
3、定义数据集划分的方式
sets = ['train'] #这里是表示只有训练集
表示当前的这个脚本,是我们用来处理训练集的,模型通过学习训练集中的特征和标签,去构建预测模型;这样的写法,是便于添加的列表形式,如果项目还需要val和test集,那就直接在sets里面添加这些划分,比如:sets = ['train','val','test']
4、写标签文件(重点来了)
4.1先做一个空的txt文本文件,用来存放等下制作的标签文件。
- 取出这个训练集,对于sets里面的每一个数据集(这里是只有train):for se in sets
- 打开或创建标签文件list_file:
list_file = open('cls_'+se+'.txt'),创建或清空一个名为cls_train.txt的文件(如果se是'train')用于写入图像信息。'w' 是文件打开模式,表示写入,接下来的操作中,会通过,list_file.write()方法往这个文件里写入数据
4.2 空文件做好了,接下来放标签信息,内容是【某张图片类别+这个图片的储存位置】
4.2.1获取图片数据集储存位置
- 获取数据集路径,用os.join拼接起来:
wd = getcwd() #当前工作路径
datasets_path = os.path.join(wd,se) # 拼接,路径+train,意思数据集在trian文件夹这里面
最后指向的是train文件夹:
- 列出数据集根目录下的子目录(类别)
types_name = os.listdir(datasets_path)# 返回是['cat','dog']

【拓展】os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。这里会返回,cat和dog这两个。
4.2.2 遍历最开始定义的数据集类别clsaaes取出索引作为图片数据集的类别
- 遍历类别:对于每个
type_name,检查它是否属于classes列表,classes是我们最开始定义的类别列表,包括,cat和dog如果不在,就跳过这个类别,否则,就继续,意思是,如果类别是猫或狗,就继续执行下面的代码,如果类别不是猫或者狗,就跳过不管了:
for type_name in types_name:
if type_name not in classes:
continue
记录类别ID:如果
type_name在classes列表中,获取其索引(即类别ID):
cls_id=classes.index(type_name)#输出0-1
【拓展】.index() 函数用于从列表中找出指定元素的第一个出现位置,并返回其索引。如果元素不存在于列表中,该方法会抛出一个 ValueError 异常。
classes.index(type_name)的意思是,从classes这个猫狗类别的列表中,根据,type_name在classes的索引位置,返回索引位置。
classes['cat','dog'],type_name会返回,0,1
4.2.3 遍历不同类别图片文件夹下的每一张图片,检查格式是不是满足jpg等
- 构建图片目录路径:photos_path=os.path.join(datasets_path,type_name),这里直接定位到存猫和狗的照片位置,就是工作路径下的train下的cat和dog文件夹
- 列出类别目录下的图片文件:
photos_name = os.listdir(photos_path)
【拓展】:os.listdir(path) 函数接收一个路径参数 path,这个路径可以是目录的绝对路径或相对路径。它的作用是返回指定目录下的所有文件和目录名(不包括子目录中的文件)组成的列表。列表中的每个元素都是一个字符串,代表了目录下的一个项(文件或子目录)的名称。
在这里,photos_path是两个照片的文件夹,这里是把所有照片的名字都取出来了,返回的形式是一个列表。
- 对每张照片的名字,进行检查,遍历图片文件:对于每个图片文件,检查其扩展名是否为
.jpg,.png, 或.jpeg。就算不是,也继续
for photo_name in photos_name:
_,postfix = os.path.splitext(photo_name) # os.path.splitext是用来分割文件名字和拓展名字的
if postfix not in ['.jpg','.png','.jpeg']:
continue
【拓展】os.path.splitext(path)是一个内置函数,它接受一个文件路径或文件名作为参数,并返回一个包含两个元素的元组:第一个元素是文件的基本名(不包括扩展名),第二个元素是文件的扩展名(包括前面的点);比如 返回('image', '.jpg'),如果 photo_name 是 'image.jpg'。
使用解包赋值(_, postfix = ...)时,下划线 _ 是一个常用的占位符,表示我们不关心元组的第一个元素(基本文件名),只想保留第二个元素(扩展名)。因此,postfix 变量将存储文件的扩展名,如 .jpg、.png 或 .jpeg.
注意!!!这个逻辑有个混淆的地方:
if postfix not in ['.jpg','.png','.jpeg']:
continue
这段条件语句的目的是排除那些非.jpg, .png, .jpeg格式的文件。具体解释如下:
- 当
postfix(即文件扩展名)不是.jpg,.png, 或.jpeg之一时,postfix not in ['.jpg','.png','.jpeg']这个条件为True。 - 当这个条件为真时,执行
continue语句,这意味着当前循环的剩余部分将被跳过,直接开始检查下一个文件。条件为真,意思是,我检查到的这一张照片的拓展名,不在这三个里面,所以,,针对于这一张,照片,我选择,continue,也就是说,我不管了,我继续执行下一张照片。如果下一张照片的拓展名,是属于这三个格式,那我就,进行进一步的图片操作。 - 因此,只有当文件扩展名确实是
.jpg,.png, 或.jpeg时,代码才会继续执行后续对这些图像文件的操作,比如将其路径写入到输出文件中。
所以,正确的理解是,这段代码是用来确保仅处理.jpg, .png, .jpeg这三种图片格式的文件,而忽略所有其他格式的文件。
4.2.4 把要的图片的类别和每张图片的路径写进label文本文件里
- 那么,对于是刚刚说的符合三个格式的照片,我们收集起来,写入到最开始,打开的那个list_file的文件里面去:
list_file.write(str(cls_id)+';'+'%s/%s'%(wd, os.path.join(photos_path,photo_name)))
list_file.write('\n')
构造字符串:
str(cls_id)+';'+'%s/%s'%(wd, os.path.join(photos_path,photo_name))这部分代码构造了一条记录,内容包括:cls_id:这是图像所属类别的ID,转换为字符串形式。假设cls_id为0或1(对应于'cat'或'dog')。';':分隔符,用于在类别ID与文件路径之间提供清晰的分隔。'%s/%s'%(wd, os.path.join(photos_path,photo_name)):这部分构造了图像的完整路径。%s是字符串格式化占位符,第一个%s会被wd(当前工作目录)替换,第二个%s会被os.path.join(photos_path,photo_name)的结果替换。os.path.join(photos_path,photo_name)确保了路径拼接的跨平台兼容性,生成从当前工作目录到目标图片的完整相对路径。
写入文件:
list_file.write(...)将上述构造的字符串写入到list_file所指向的文件中。这样,每张图片的信息(类别ID和相对路径)就会以文本形式存储在文件里,每条记录之间通过分号分隔,每条记录末尾通过list_file.write('\n')添加换行符,以便于之后读取时能清晰地区分每一条记录。
最后,list_file.close()
注意:原来的博主,用的是gbk编码,这样生成的label文件在我这是乱码,其实一般用utf-8会好,所以,需要写一个程序,把编码格式改成utf-8:

# 转换脚本
# 转换脚本
def convert_gbk_to_utf8(input_file, output_file):
with open(input_file, 'r', encoding='gbk') as f:
content = f.read()
with open(output_file, 'w', encoding='utf-8') as f:
f.write(content)
# 调用函数进行转换
input_file = 'cls_train.txt' # 这里填写你的GBK编码文件名
output_file = 'cls_train_1.txt' # 输出的UTF-8编码文件名
convert_gbk_to_utf8(input_file, output_file)总结
到这里,就针对于我们的猫狗数据集,完成了,数据的清洗以及标签文件的制作。所以,对于其他的数据集,步骤也是大差不差的。
现在来,总结一下:
1、拿到数据做什么?
- 数据清洗+标签文件制作(两个步骤相辅相成)
首先,拿到数据集,我们要做两件事,数据清洗和制作标签文件,在这个项目里面,照片都是很干净的数据,不存在格式乱七八糟或者其他的情况,所以,清洗就是简单的判断是不是jpg等格式,还是很简单的。
另外就是,标签文件夹的制作。这里学到的一点是,我们可以先分析图片的存放形式,然后,通过索引的方式,遍历,train文件夹下的不同类别的子目录,完成自动生成好几个类别的作用。
2、分类标签文件存什么?
- 标签文件信息:类别+图片路径
映射文件:当图片和标签不是通过文件结构直接关联时,会使用一个映射文件来记录这种对应关系。这个映射文件(如CSV)通常包含至少两列,一列是图片的路径或文件名,另一列是对应的类别标签。例如:
1image_path,label
2data/cats/cat_001.jpg,0
3data/dogs/dog_002.png,1在这个映射文件中,第一列是图片的完整路径或相对于某个根目录的路径,第二列是类别标签,0代表猫,1代表狗。
在使用深度学习框架(如PyTorch)进行训练时,可以通过自定义的数据加载器(DataLoader)读取这种映射文件,根据映射关系动态地加载图像和对应的标签,从而实现图片与其类别信息的正确配对。
3、拓展到其他的数据处理过程
- 图片名字是各有不同的,有的很复杂,各种标点符号什么的,会涉及更复杂的处理。所以要学会观察图片名字,然后做出分割。
- 分类问题的标签还是很简单的,就是把图片文件路径读取,然后拆开,根据循环,一张一张图片的取出来解析,是什么类型,然后配上每张图片的路径。
完整代码
import os
from os import getcwd
classes=['cat','dog']
sets=['train']
if __name__=='__main__':
wd=getcwd()
for se in sets:
list_file=open('cls_'+ se +'.txt','w')
datasets_path=se
types_name=os.listdir(datasets_path)#os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
for type_name in types_name:
if type_name not in classes:
continue
cls_id=classes.index(type_name)#输出0-1
photos_path=os.path.join(datasets_path,type_name)
photos_name=os.listdir(photos_path)
for photo_name in photos_name:
_,postfix=os.path.splitext(photo_name)#该函数用于分离文件名与拓展名
if postfix not in['.jpg','.png','.jpeg']:
continue
list_file.write(str(cls_id)+';'+'%s/%s'%(wd, os.path.join(photos_path,photo_name)))
list_file.write('\n')
list_file.close()【为什么每个图片能精准匹配到他的类别?】实际上是因为用了两个循环,第一个大循环(for type_name in types_name),让你进入到cat文件夹,然后,第二个小循环(for photo_name in types_name),遍历,cat文件夹下面的每一张图片, 直到cat里面每一张图片都遍历完,在跳入dog文件夹的大循环,然后,遍历,dog文件夹下面的每一个狗的图片。
所以,数据集组织结构要清晰,每个类别下的图片需放在对应类别名称的文件夹中。