游戏领域的做法:
1.建模
2.两个模型标准动作对齐retarget
3.骨骼动画迁移
思维:
运动是由骨骼作为主要驱动,骨骼是刚性体,确定好骨骼端点(关节)运动瞬态动作就确定;一个模型的运动对应数学建模就是时间有序的一帧一帧骨骼刚体的集合。只要找到两个模型骨骼对齐关系;那么就可以用一个模型的时间序列骨骼动作集驱动另一个模型运动。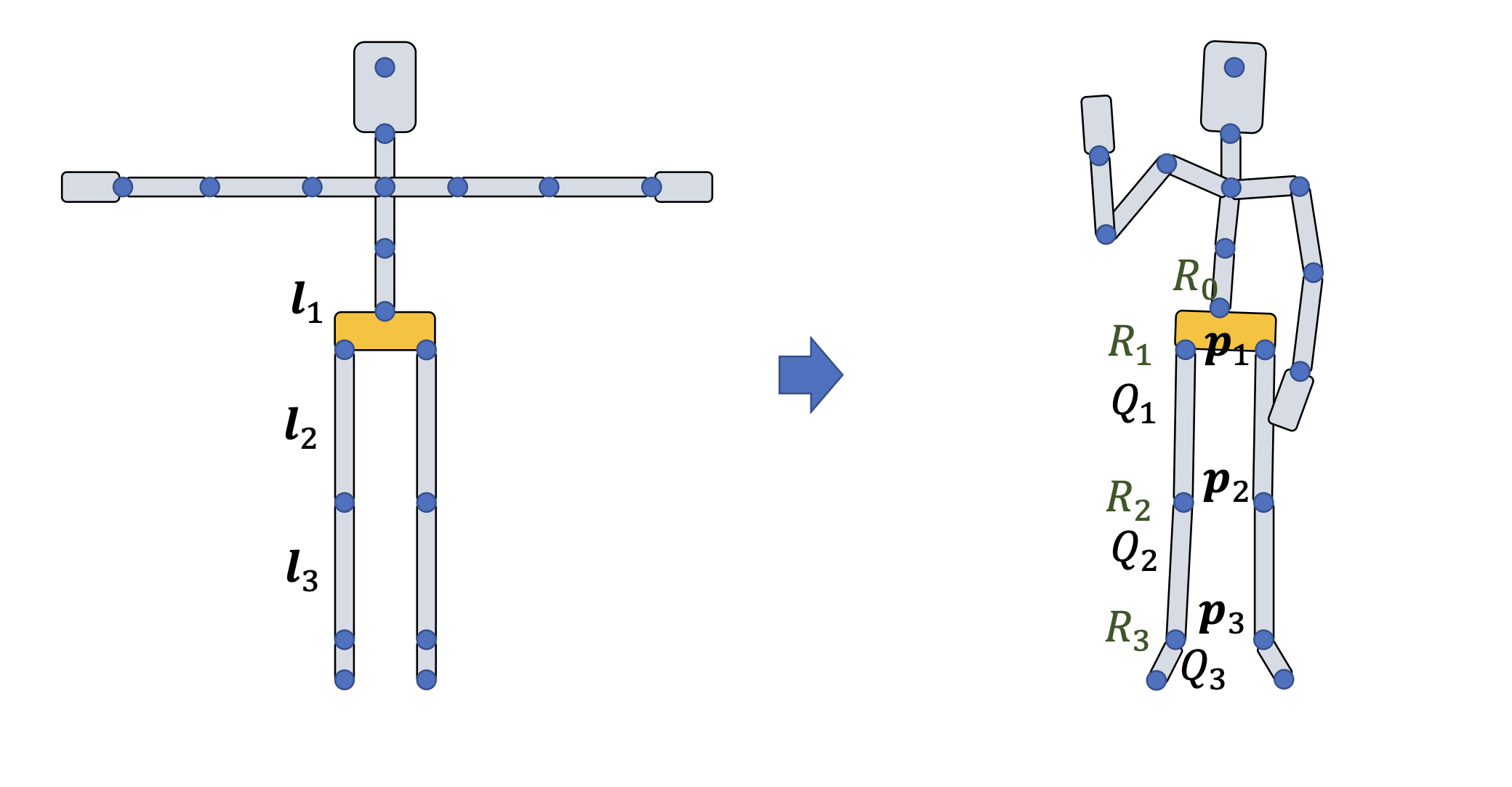
模型的造型是由一些列的三维体集合围绕在骨骼刚性体构成的拓扑结构,或者说是由一系列围绕在骨骼集合的点构造的曲面造型。假设三维体和骨骼之间的映射关系是不变的,也就是说在不同的动作序列骨骼和三位体的相对关系是保持不变的,不会因为不同动作三维体相对骨骼对应关系会发生变化。那么我们只要有了一组三维体集合与骨骼映关系,任何动作序列上骨骼动作对应三维造型就是知道的。
造型确定了,会涉及到不同状态。什么是造型状态呢,举个例子说明:一个人年轻和老年状态、高兴和悲伤、健康和生病。那么该如何表示呈现同一个造型的不同状态呢。这就涉及到“表皮”功夫了;通过在造型上蒙一层皮肤,给皮肤设定不同的属性,比如:光泽度、纹理、颜色、粗糙度…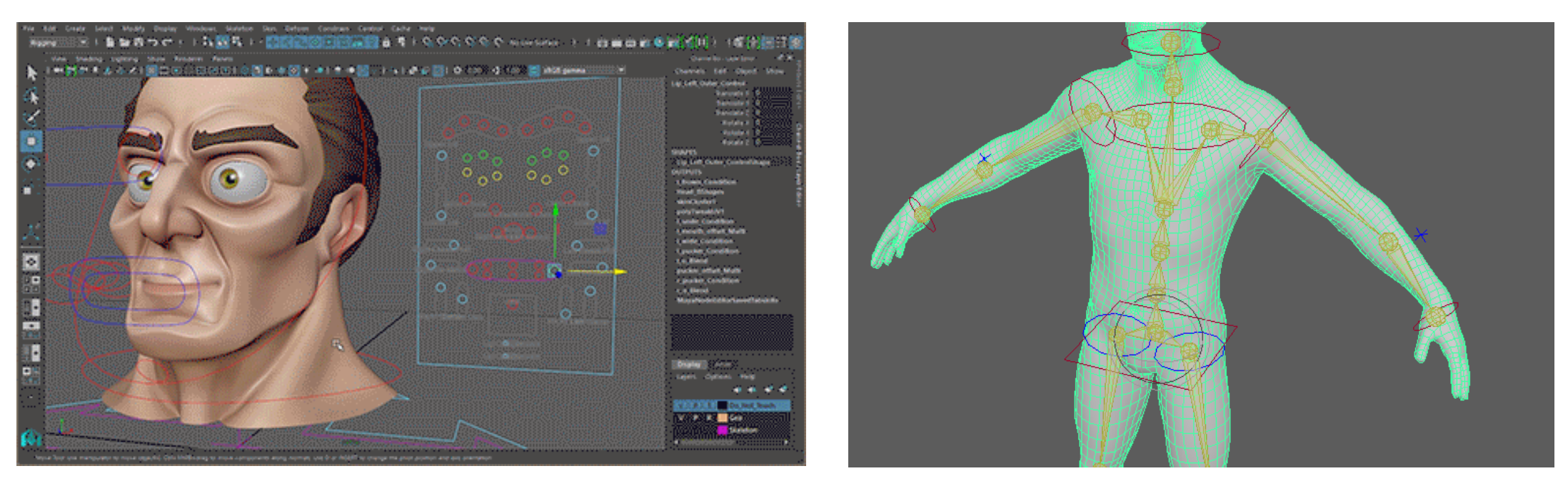
人靠衣裳佛靠金装,不同的装饰物外挂物装饰下模型会表现出完全不一样的效果。比如压在五行山下的猴哥,和穿上齐天大圣那身行头的猴哥和西天取金豹纹装的猴哥差异是很大的。所以装饰物的渲染对模型(角色)塑造也是非常重要的,并且往往这些装饰物是柔性的,在不同的动作下他们和骨骼的相对位置映射关系是变化的。
所以在游戏人眼中一个造型的生成就包括下面三大模块:
驱动动作
造型渲染:三维体、蒙皮
装饰物渲染
生成模型的一些做法
生成模型的做法基本思路都是围绕下面4部分来展开的:
角色渲染:保证角色一致性
动作指导:保证动作合理性
动作和角色对齐渲染:保证合理的角色一致性的动作
动作衔接的一致性:保证前后两帧动作衔接合理流畅
Dreambooth+controlnet
1.用Dreamboooth的方式来让Diffusion模型学会角色渲染,保持角色一致性。
2.把驱动视频每帧图片抽取骨骼关键点用cotrolnet范式来实现把驱动模型骨骼绑定、对齐到目标角色。
3.然后用Dreambooth模型把角色渲染出来。
这样生成的驱动视频效果很差,原因有以下几点:
1.Dreambooth学习到的角色渲染是静态的
2.从骨骼到角色渲染,按游戏建模视角看还需要经历:三维体关系对应、mesh对齐、装饰物对齐,然而这些任务Dreambooth都没学过,这其实是一个给定约束方程少于参数的方程组求解问题,所以模型很容易随便给一个合适解,这个解往往和期望值不一致
渲染、驱动两个模型
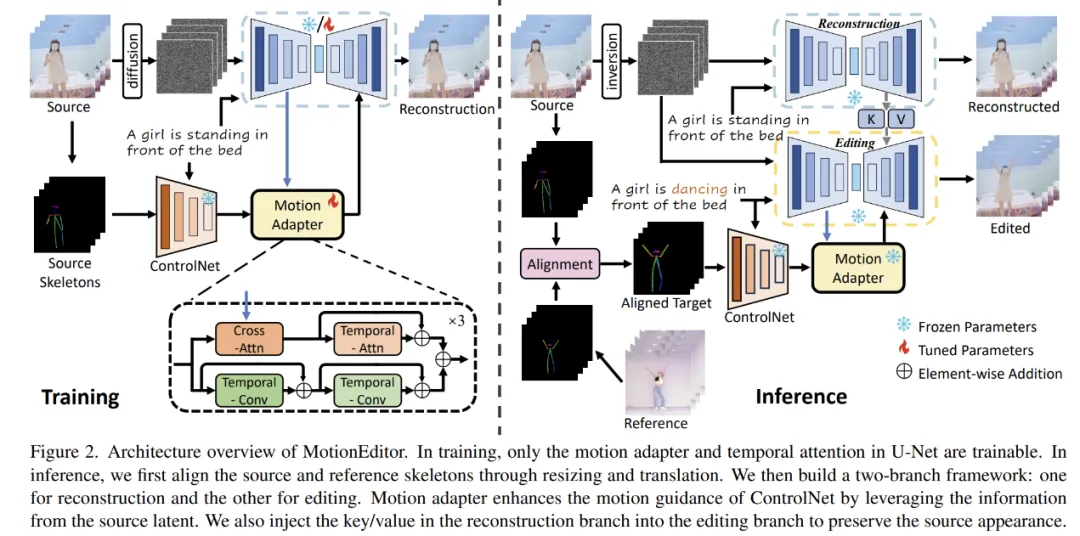
1.通过驱动视频+抽取的骨骼驱动做视频重构,让diffusion模型学会角色渲染
2.motion adapter部分抽取驱动特征作为渲染的指导动作控制因素
这样生成的驱动视频效果比上一种好很多,原因如下:
1.角色渲染模型通过数据重构的方式学到了给定一张图如何把图帮到骨骼的映射关系
2.motion Adapter学习到了动作对渲染的关键控制因素
3.diffusion模型经历过pretrain数据训练有较强泛化能力,在经历角色动作视频自重构sft,可以把角色到骨骼映射关系能力迁移到没经过训练图片
然而这样做对于大动作的视频生成效果还是不太好的。这个原因就是骨骼到最后角色造型还有至少3层:三维体关系对应、mesh对齐、装饰物对齐。虽然经过角色动作自重构学习学习到一些角色到骨骼映射,但是这里给的数据信息显然不太够。
模型Loss设计

上面一个模型的问题是角色驱动视频自重构学习角色到骨映射很多细节信息不够,导致模型学的不够精细到一些大动作,小细节生成效果不好。那么有没办法还是自重构学习,但是我在学习loss上做设计:
1.让模型学习到角色、骨的位置映射loss
2.让模型学习到皮肤、骨的关系映射loss
3.让模型学习到装饰物、骨的映射loss
把上面loss整合到一起保证映射的更具体细节,然而这么模型在学习映射前已经经过Attention层抽取特征、并且很多映射关系没法显示提取出来;那么就会导致学不到最后效果也不会好
可能的展望
视频生成+起止关键帧生成
1.先训练好视频生成模型,让模型具备比较强的续生、插帧生成、修改、一段视频缺失部分补齐
2.模型能过保持一致性和指令遵循能力
3.通过sft方式调试出单图、多图插帧序生能力生成合适视频
4.对生成视频不合适部分(比如下半部分肢体运动)全部去除,用模型补全能力+prompt指导生成
视频生成+骨序列指导
1.对学习好的视频生成模型,做骨序列sft
2.对骨序列sft模型做单图生成sft
3.对sft好模型单图、骨序列做推理
上面的思路基本就是绕开显示的设定角色——骨动作映射loss学习。通过更多样的数据任务设计让模型学习到细节映射,也就是把显示的loss映射转成任务设计学习,可以更简单且有效的学习到复杂的(讲不明白的)映射关系。通过sft的方式绕开显示loss设计需要的数据少的问题,通过一个容易找到数据方式通过任务设计方式让模型学到更多能力。
总结:
生成模型是一种任务设计型的学习,这种学习方式区别于判别式学习地方在于:通过任务设计的方式实现显示的loss设计的效果,这样可以把很多用无法显示loss设计的任务变得可能,并且可以把很多因为认知偏差导致无法解耦合的问题可以解。也就是任务设计巧妙的绕开了需要非常明确的把细节拆开设计loss才能解决问题的困局。很多问题看起来是耦合的,你站在这个视角看可以这么区分,在另一个视角看可以那么分;但无论如何都千丝万缕无法完全切分开,如果这样那么我们就永远是近真实,很多问题如果站的视角不对就会被分的非常细,如此细的任务很多问题是确实数据的,那么这个问题就没解了。任务设计的巧妙之处是不需要显示的把这些loss分那么细,只要大致的设计好很多耦合问题反导对于其它能力提升是有帮助的。