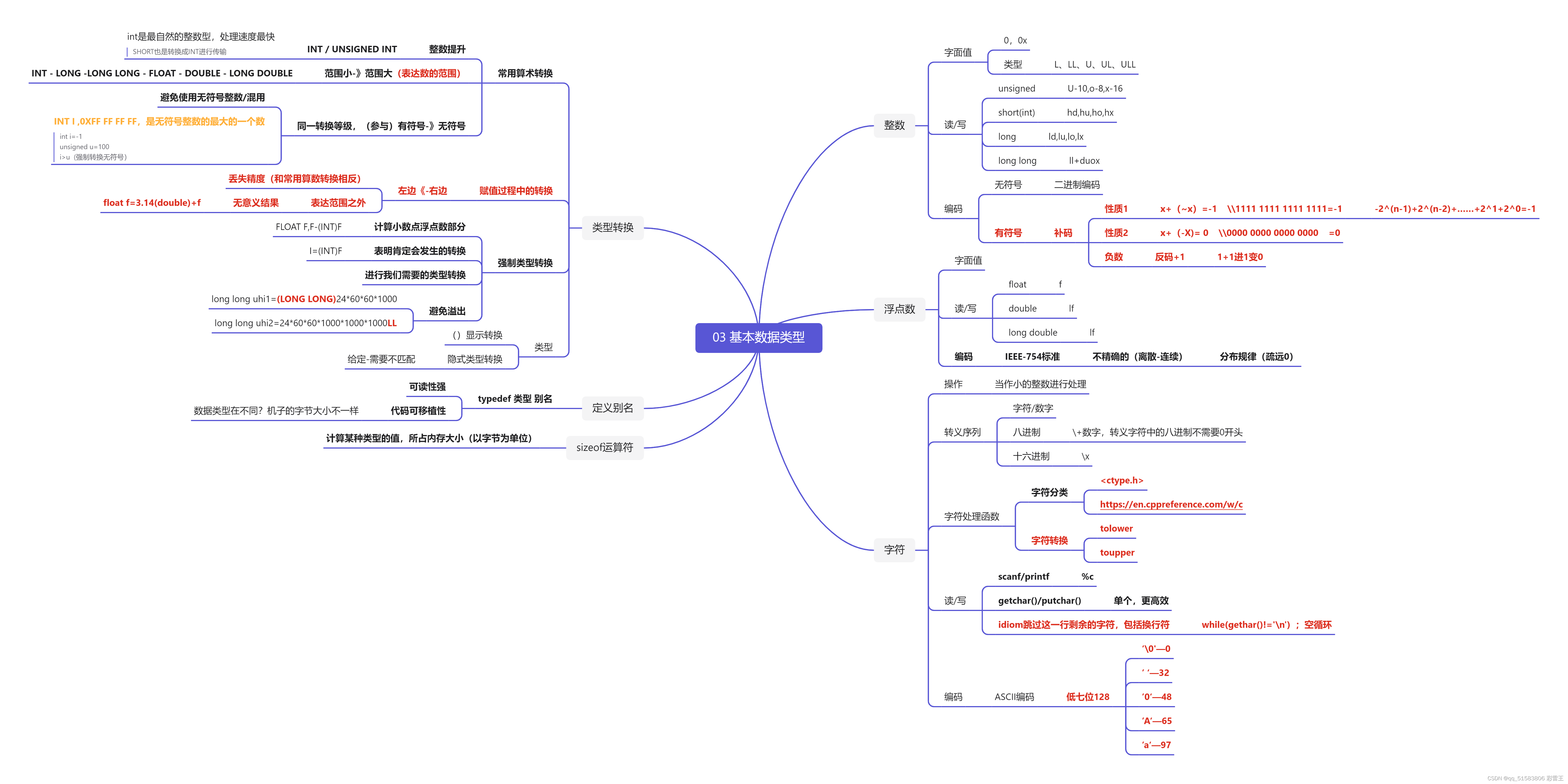
字符编码 ( Character encoding ) : 也称字集码 , 为字符集中的字符指定唯一的二进制编码 .
* 涉及字符串和文件必须要将字符编码理解透彻 .
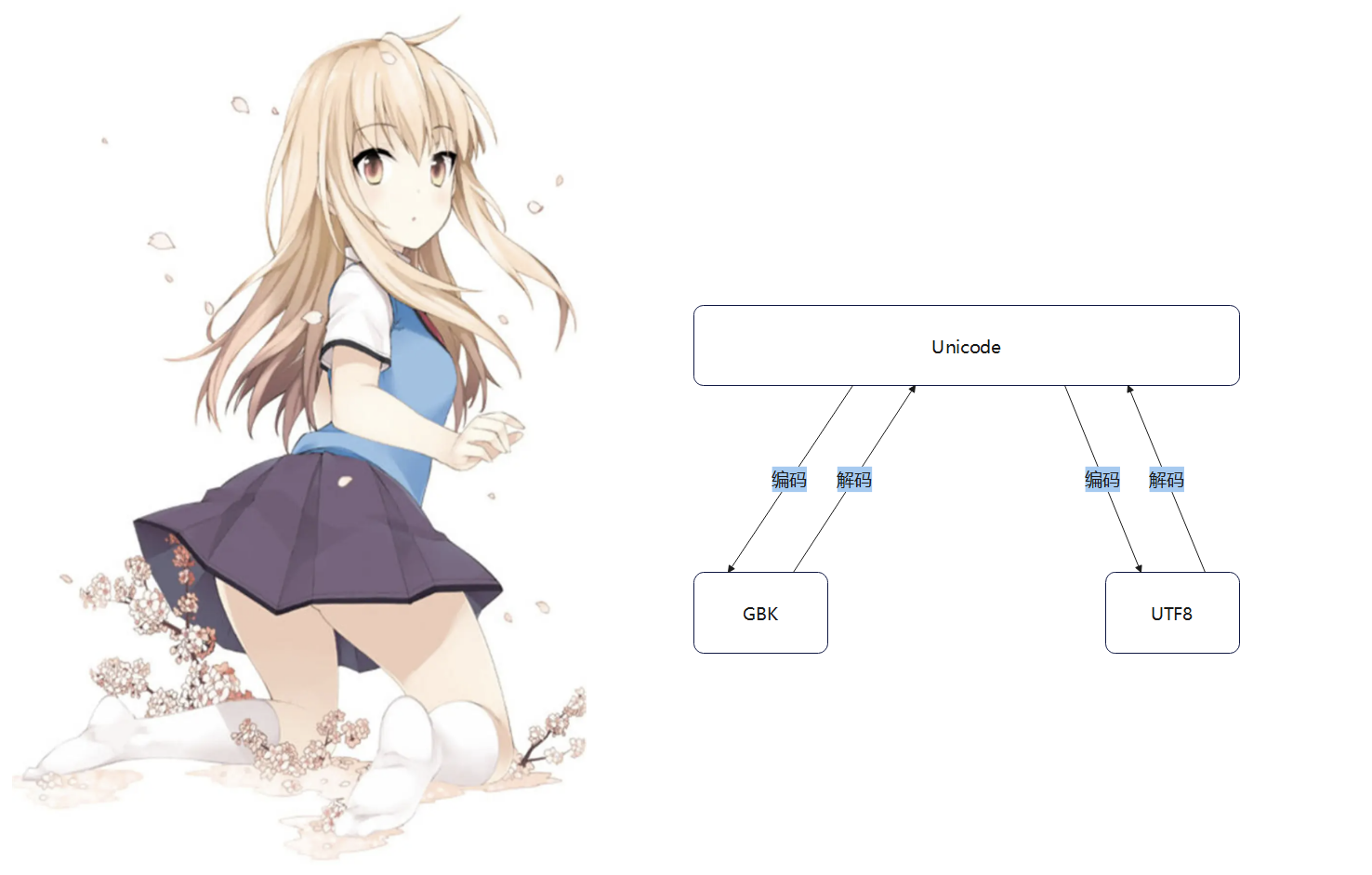
Unicode编码 : 包含世界上所有的符号和二进制的对应关系 .
基于Unicode编码设计的字符集 :
UTF8 : 可变长字符集 , 使用 1 - 4 个字节表示一个字符 , 多用于存储文件与传输文件 . . .
UTF16 : 使用 2 - 4 个字节表示一个字符 , 因为UTF16可以使用 2 个字节代理成四个字节 , 内存中统一使用的编码 .
UTF32 : 使用 4 个字节表示一个字符 .
解决乱码的根本 : 文件以什么编码方式存储到硬件中 , 就必须以什么编码方式将文件读取出来 .
import sys
print ( sys. getdefaultencoding( ) )
源文件 : 以UTF8编码方法存储 , 编辑器则以UTF8解码方法打开并展示文本信息.
Python3默认的编码方式为UTF8 , 意思就是 : 运行时解释器以UTF8编码解释源文件 .
* Python3的字符串单独使用 'Unicode字符串' 存储 , 格式占 2 个字节 ,
引号语法创建的任何字符串都会存储为 'Unicode' 类型的字符串 .
Unicode它本身收录所有的字符 , 占用的字节和内存中占用的字节是一样的 ,
在各国的计算机平台上解释的时候都不会乱码 .
在 Python 3 中 , 默认的字符编码是 UTF- 8.
这意味着 , 在 Python 3 中创建的字符串对象是以 Unicode 编码表示的 .
s = '你好'
print ( s. encode( 'gbk' ) )
print ( s. encode( 'utf-8' ) )
源文件 : 以UTF8编码方法存储 , 编辑器则以UTF8解码方法打开并展示文本信息.
Python2比Unicode早诞生 , 所以在内存中使用的不是Unicode编码 , 而是ASCII编码 .
运行时解释器以ASCII编码解释源文件 .
Python语法使用的关键字 , 变量名 , 几乎都是英文 ( 为什么说几乎 , Python3可以使用中文作为变量名 ) ,
而所有的字符集都兼容英文 , 这部分代码不会出现编码问题 .
在使用编辑器写代码的时候 , 编辑器会将代码以utf8格式保存为文件 , 在以utf8格式打开进行文件 .
这个过程也不会出错 .
在运行时 , 如果注释和字符串中出现中文那么问题就来了 ,
解释程序的编码与源文件使用的编码 , 不一致 , 就会出现乱码或报错 , 基本原因如下 :
* 1. 解释程序的编码表没有这个字符对应的二进制就会报错 .
* 2. 不同的编码表字符和二进制的对应关系不一样 .
例如 : 一种编码使用 '0001' 表示 '你' , 一种编码使用 '0001' 表示 '我' ,
拿到 '0001' 二进使用不同的编码表翻译的意思就不一样 .
* 3. 不同的编码表可表示的范围不一样 .
例如 : 某种编码只能解析 1 位二进制的的字符 , 提供了一个 2 位的二进制的 ,
它可能会截取其中一部分区解析 , 解析出来的意思就完全不一样 .
>> > x = '你打野!'
>> > x
'\xc4\xe3\xb4\xf2\xd2\xb0!'
>> > x = u'你打野!'
>> > x
u'\u4f60\u6253\u91ce!'
使用编辑器写代码是 , 将源文件由UTF8字符集转换为ASCII编码 , 解释源文件 , 运到非ASCII字符报错 .
解决非ASCII问题 :
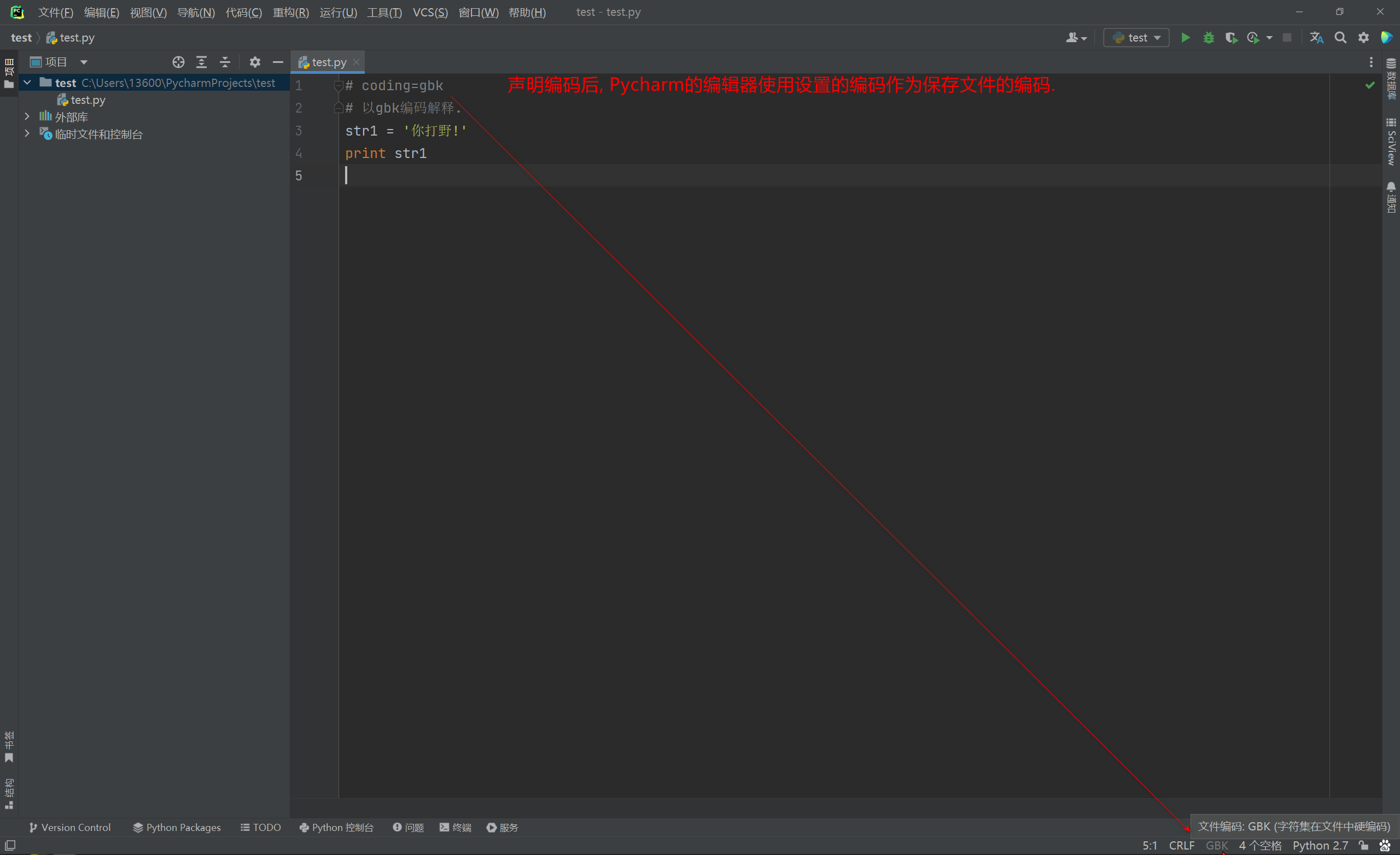
编写源文件时可以通过声明编码的方式 , 常用声明编码为 UTF8 或 GBK .
Python文件头部声明编码格式 : 修改的是文件的默认编码格式 ,
只是会影响Python解释器读取Python源文件时的编码格式 , 并不会改变系统默认编码和本地默认编码 .
声明编码后使用注释使用中文不会在出现问题 , 可字符串中出现中文 , 执行时还是会出现乱码的情况 .
注意 : 声明编码后 , Pycharm的编辑器使用设置的编码作为保存文件的编码 .
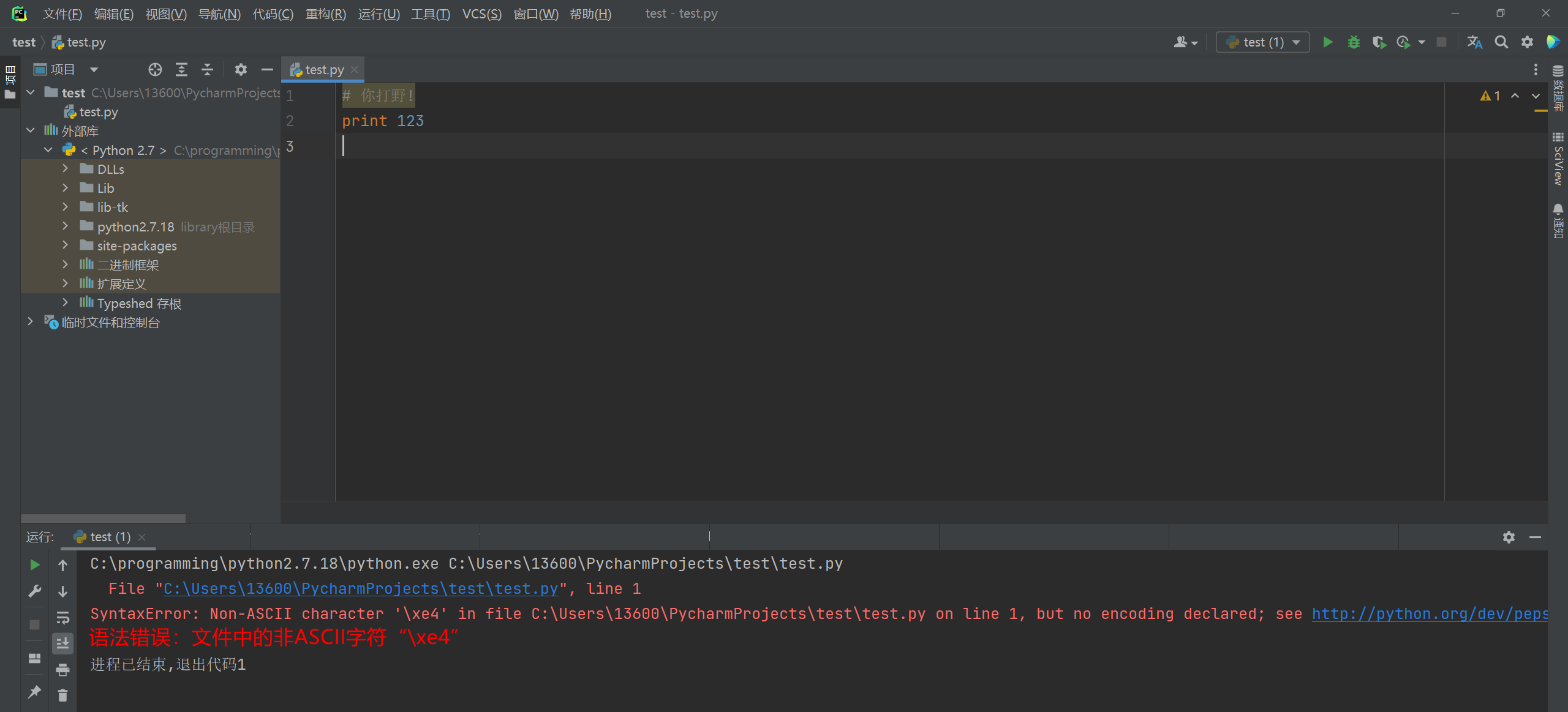
print 123
运行程序时 , 源文件由UTF8字符集转换为ASCII编码 , 字符 '你' 的在UTF8编码的十六进制为 '\xe4\xbd\xa0' ,
ASCII编码无法解析 \ xe4 , 就报异常了 .
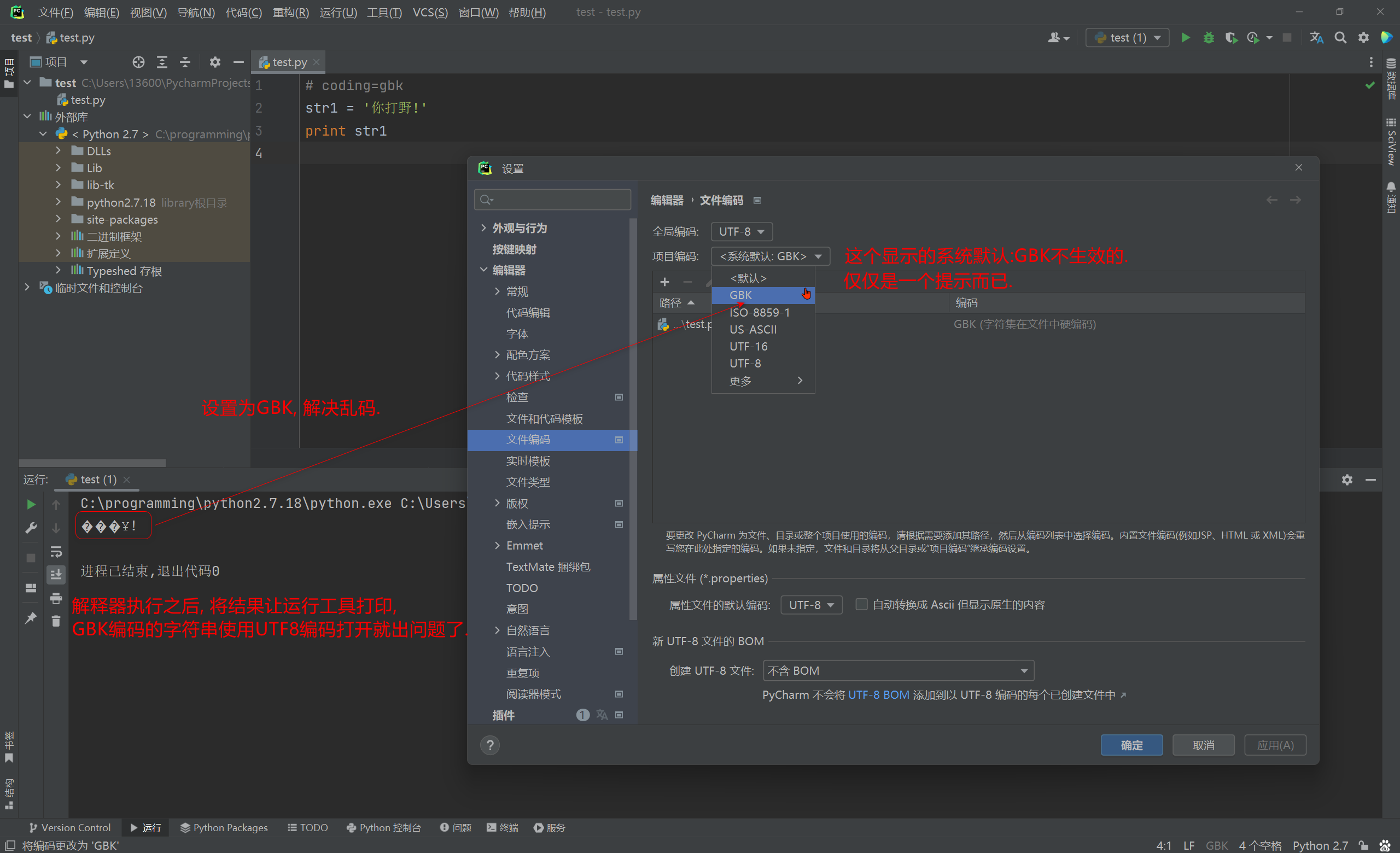
以GBK格式解释源码在Pycharm中运行出现乱码问题 , 解决乱码的方法 :
* 1. 修改Pycharm的项目编码改为GBK .
Pycharm的全局编码为UTF8 , 项目编码也为UTF8 ( 显示 < 系统默认 : GBK > , 是不生效的 . ) .
File -- > Setting -- > Editor -- > File Encodings .
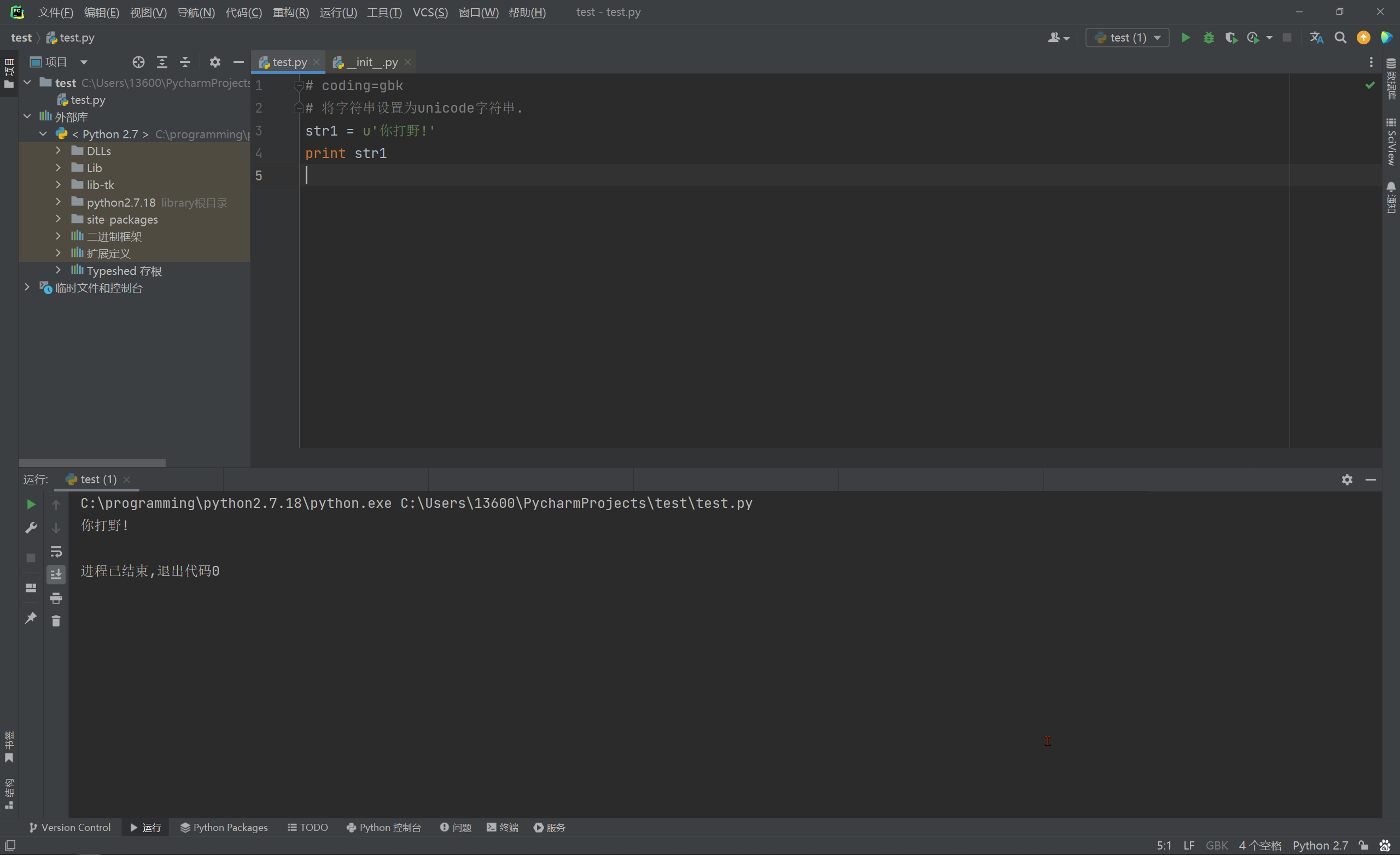
* 2. Python2中增加了Unicode字符串 , 将字符串设置为Unicodee字符串 .
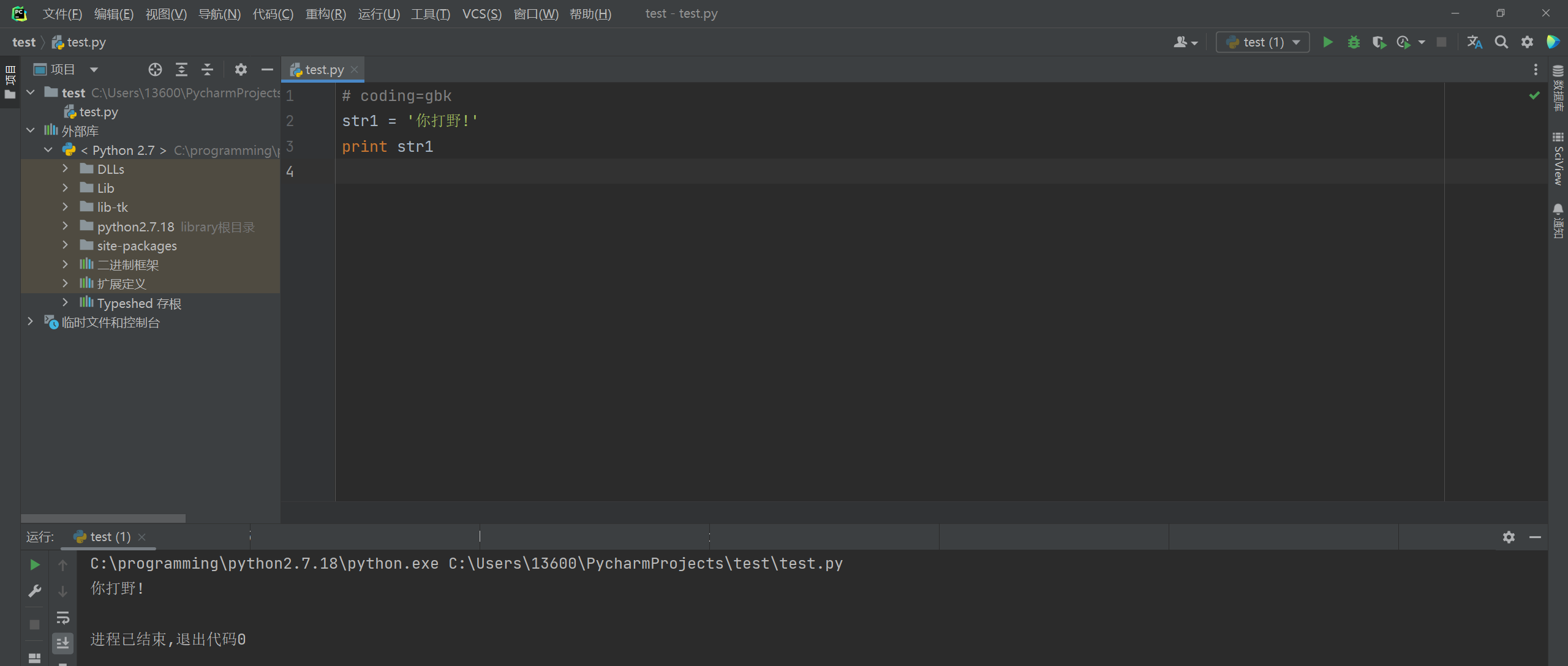
str1 = '你打野!'
print str1
str1 = u'你打野!'
print str1
命令行模式运行程序 , 则正常显示 .
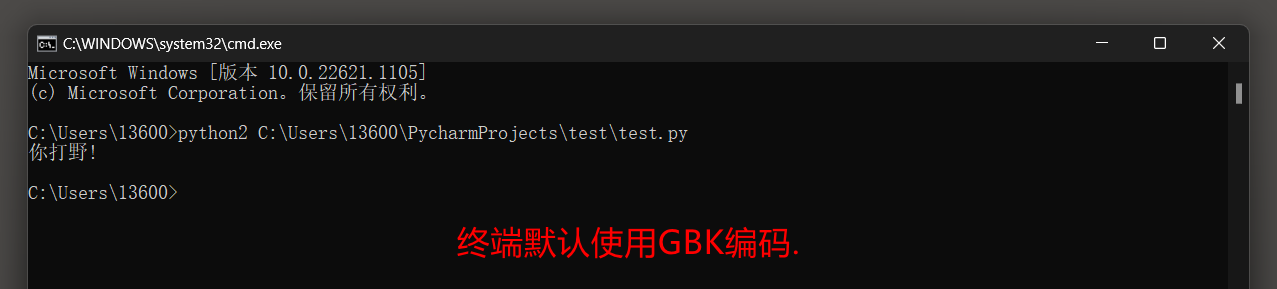
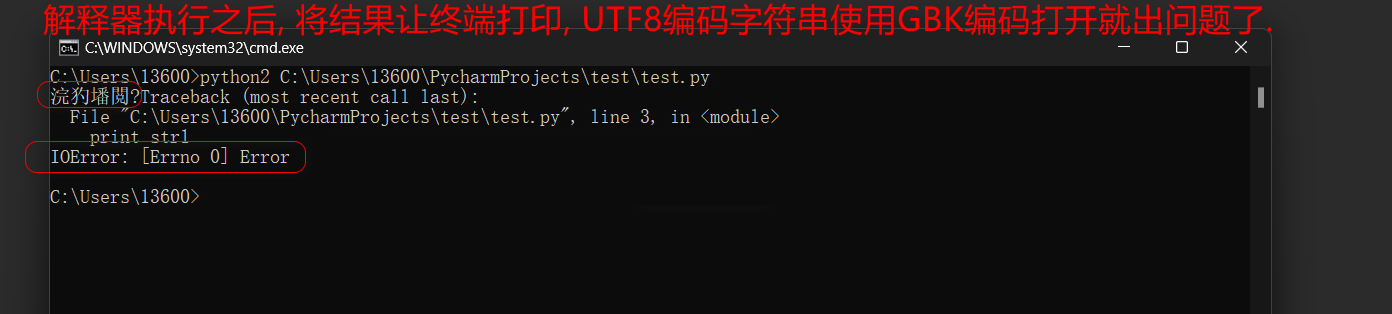
以UTF8格式解释源码 , 使用命名行模式运行会出现乱码和引发IoError异常 , 解决方法 :
* 1. 将字符串设置为Unicodee字符串 .
* 2. 使用模块修改cmd的默认编码为UTF8 .
str1 = '你打野!'
print str1
Pychamr中运行没有问题 , 但是命令行方式运行出现乱码 , 还引发了一个IOError的异常 .
别人说的 : 这个问题是windows实现C函数的问题 : https : / / bugs . python . org / issue1602 # msg148990
str1 = u'你打野!'
print str1
import os
import win_unicode_console
win_unicode_console. enable( )
os. system( "chcp 65001" )
str1 = '你打野!'
print str1
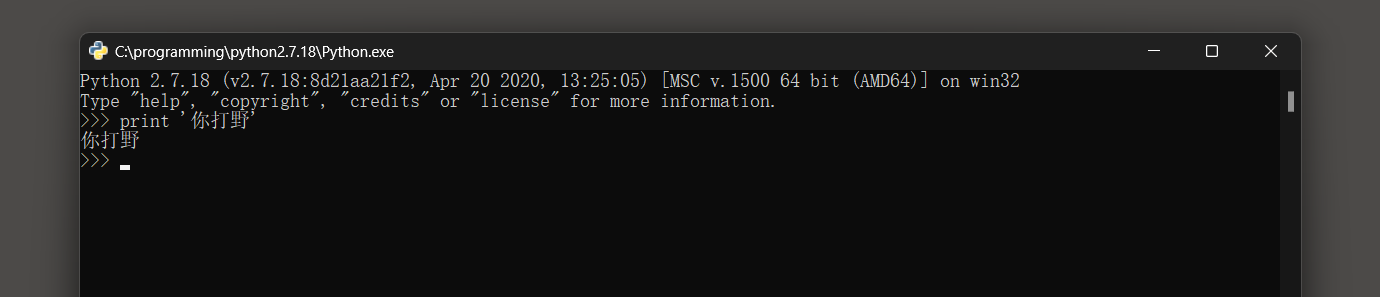
使用终端调用解释器交互环境时 , 解释会使以GBK编码加载 , 使用中文不会报错 .
bytes类型在Python中被称为 '字节串' , 不过很少有人说字节名字 .
bytes类型 : 使用引号引起来的一组字节序列 , 将数据以字节的形式存储 .
bytes类型以二进制字节序列的形式记录所需记录的对象 ( 2 进制太长 , bytes类型最终以十六进制展示 ) ,
至于该对象到底怎么表示 , 则由相应的编码格式解码所决定 .
bytes通常用于网络数据传输 , 二进制图片和文件的保存等 .
在Python2中字符串就是字节串 , Python3中新增bytes类型 , 将字符串和bytes类型彻底分开了 ,
字符串使用Unicode类型存储 , 不在使用字节串 .
Bytes数据类型在所有的操作和使用甚至内置方法上和字符串数据类型基本一样 , 也是不可变的序列对象 .
* 字符串是以字符为单位进行处理的 , bytes类型是以字节为单位处理的 .
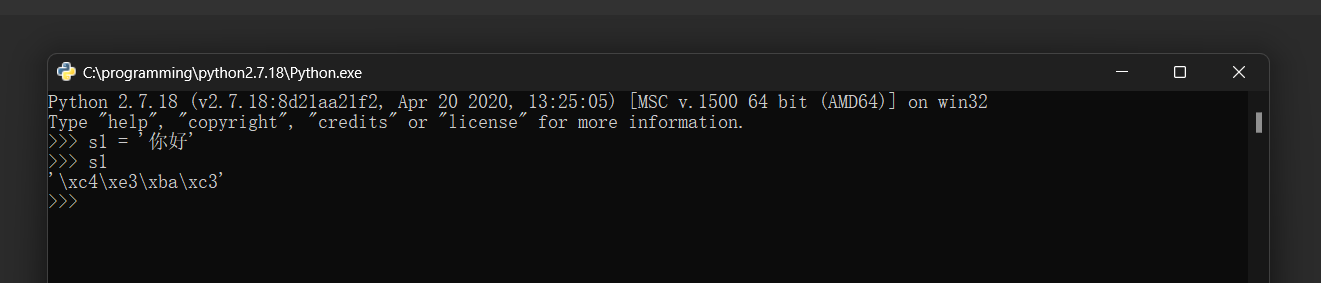
>> > s1 = '你好'
>> > s1
'\xc4\xe3\xba\xc3'
\ x是小写的十六进制转义字符 , 每个十六进制数代表一个字节 ( 八位二进制数 ) .
字符 '你' 用 '\xc4\xe3' 表示 .
字符 '好' 用 '\xba\xc3' 表示 .
同一个字符串如果采用不同的编码方式生成bytes对象不一样 .
s1 = '你好'
print ( s1)
s2 = s1. encode( 'gbk' )
print ( s2, type ( s2) )
b1 = b''
print ( b1, type ( b1) )
b2 = b'hello'
print ( b2)
b3 = bytes ( '你好' , encoding= 'gbk' )
print ( b3)
b4 = '你好' . encode( 'gbk' )
print ( b4)
Python内置字节串与字符串互相转换的方法 : ( 编码与解码仅针对字符串类型 . )
bytes = str . encode ( '编码方式' ) 默认使用UTF8编码 , 将str类型编程为bytes类型 .
str = bytes . decode ( '解码方式' ) 默以使用UTF8解码 , 将bytes类型解码成成str类型 .
* 纯英文的字符 , 可以直接在字符串前面加上b , 将str类型编程为bytes类型 .
b1 = b'hello'
print ( b1)
print ( b1. decode( ) )
str1 = '你好!'
e1 = str1. encode( 'UTF8' )
print ( e1, type ( e1) )
e11 = str1. encode( 'UTF8' )
print ( e11, type ( e11) )
e2 = str1. encode( 'GBK' )
print ( e2, type ( e2) )
d1 = e1. decode( 'UTF8' )
print ( d1, type ( d1) )
d11 = e11. decode( )
print ( d11, type ( d11) )
d2 = e2. decode( 'GBK' )
print ( d2, type ( d2) )
s1 = '你好'
e1 = bytes ( s1, encoding= 'utf8' )
print ( e1)
for i in e1:
print ( i, hex ( i) , bin ( i) )
运行终端工具窗口显示 :
b '\xe4\xbd\xa0\xe5\xa5\xbd'
228 0xe4 0 b11100100
189 0xbd 0 b10111101
160 0xa0 0 b10100000
229 0xe5 0 b11100101
165 0xa5 0 b10100101
189 0xbd 0 b10111101