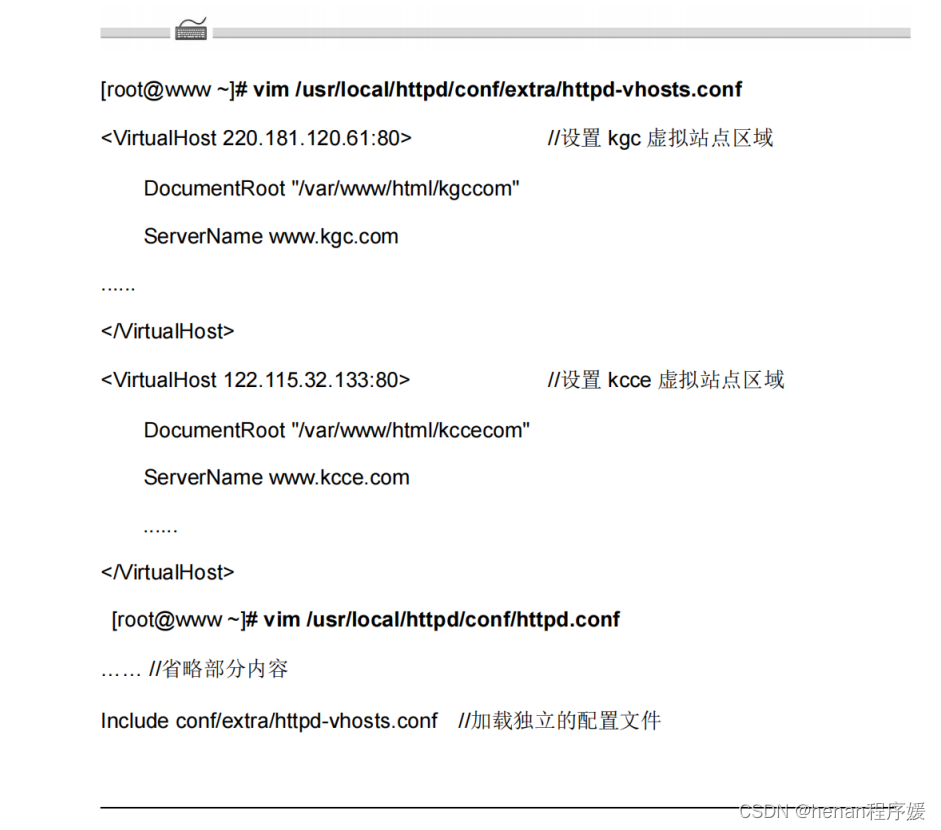
MVsplat 使用了Hydra 库来进行参数的配置 :
在文件运行的最开始的地方, 使用装饰器 使用 Hydra 这个库,一般都是对于 Main 函数进行修饰的,需要读取代码中的 yaml 文件:
@hydra.main(
version_base=None,
config_path="../config", ## config 文件的路径
config_name="main", ## 读取 main.yaml 文件
)
yaml 文件和 defaults 关键词搭配起来,可以去调用 其他的 yaml 配置文件。
Main.yaml 文件的内容如下:
defaults:
- dataset: re10k ## 表示 dataset 的配置文件在re10k.yaml 去读取
- optional dataset/view_sampler_dataset_specific_config: ${dataset/view_sampler}_${dataset}
- model/encoder: costvolume
- model/decoder: splatting_cuda
- loss: [mse]
Hydra 库 一般和 yaml 文件组合起来设置超参数
参考网址:https://zhuanlan.zhihu.com/p/662221581
启动命令:python -m src.main +experiment=re10k
这行命令会导致 程序的 config 最终会加入在 experiment 目录下的 读取 re10k.yaml 文件,作为配置文件
Pytorch Lighting 的学习
Youtube 小哥的教学视频: https://www.youtube.com/watch?v=XbIN9LaQycQ&list=PLhhyoLH6IjfyL740PTuXef4TstxAK6nGP&index=1
Lighting 的源代码库,查看API:
https://github.com/Lightning-AI/pytorch-lightning/blob/5aadfa62508ee20735083900273c8e3ff5867602/src/lightning/pytorch/core/module.py#L2
Overview:
1. 在继承 Lighting 的一个类里面,需要实现以下的函数:
训练的主函数:,最后只需要返回 loss 即可,之后的 Backward 操作 Lighting 会自己完成,并不需要用户编写。
def training_step(self, batch, batch_idx):
retrun Loss
这里返回 一个 Loss 或者 预测的 dictionary , 像loss.backward() 等工程性质的代码,在Lighting 已经被自动计算好了。
在 下面使用Test 和 Validate 的时候 会自动不计算和保留程序的梯度。
model.eval() and torch.no_grad() are called automatically for validation.
测试的主函数:
def testing_step(self, batch, batch_idx):
配置优化器:
def configure_optimizers(self):
2. 配置训练器Trainer :
trainer = Trainer(
max_epochs=-1, ## 设置为 -1 表示可以无限训练
accelerator="gpu",
logger=logger,
devices="auto",
strategy="ddp" if torch.cuda.device_count() > 1 else "auto",
callbacks=callbacks,
check_val_every_n_epoch=None, ## 我们是暗战 step 来计算,而不是 epoch
val_check_interval=500, ## 500个step 运行一次 validation
enable_progress_bar=cfg.mode == "test",
gradient_clip_val=cfg.trainer.gradient_clip_val, ## 梯度裁剪。 防止出现梯度消失或者爆炸。
max_steps=cfg.trainer.max_steps, ## 指定了 最大的 steps
num_sanity_val_steps=cfg.trainer.num_sanity_val_steps, ## 训练前先进行 validate, 保证代码没有出错
)
在 Pytorch 中使用 Tensorboard Logger:
- 先在主函数里面定义 TensorboardLogger, 并且添加到 Trainer 当中:
logger = TensorBoardLogger(save_dir=cfg_dict.output,version=cfg.descriptor)
trainer = Trainer(
max_epochs=-1,
accelerator="gpu",
logger=logger, ## 使用 Tensorboard 的 Logger
devices="auto"
)
- 先在 training_step 当中 使用我们定义的 Logger:
self.logger.experiment.add_image()
self.log('PSNR', psnr, prog_bar=True, on_step=True, on_epoch=False)
3. Metrics :
Video 里面说可以在 **回调函数 training_step ** 去计算某一些指标.
def training_step(self, batch, batch_idx):
4. DataModule
Lighting 的 Dataset 和 Pytorch 的 Dataset 的定义方式是很相近的。 都是需要先 自己定义一个 Dataset, 然后根据自己定义的 Dataset 去实现 对应的 Dataloader
在 DataModule 里面需要实现3个 DataLoader
class DataModule(LightningDataModule):
def prepare_data(self): ## 最开始运行的 函数,一般也可以用于读取数据
self.dataset =
pass
def train_dataloader(self):
return DataLoader(self.datset)
def val_dataloader(self):
return DataLoader(self.datset)
def test_dataloader(self, dataset_cfg=None):
prepare_data: 会首先调用这个函数去 准备 数据集,比如说生成 **Dataset. ** MVSNeRF 的代码就是在 默认的 prepare_data 里面去 生成了 数据集 self.train_datatset。
def prepare_data(self):
dataset = dataset_dict[self.args.dataset_name]
train_dir, val_dir = self.args.datadir , self.args.datadir
self.train_dataset = dataset(root_dir=train_dir, split='train', max_len=-1 , downSample=args.imgScale_train)
self.val_dataset = dataset(root_dir=val_dir, split='val', max_len=10 , downSample=args.imgScale_test)#
但是所有的 关于 Dataset 的 参数设定,最后都需要 体现在 DataLoader 的参数当中,或者 Datalodaer 的参数之前。
4. Device
Pytorch Lighting 会自动分布device, 因此代码里不需要显式调用 .cuda() 或者 device.
Remove any .cuda() or .to(device) Calls
装饰器 rank_zero_only
这个 命令表示,这个函数只会在 GPU:0 上进行运行,而不会在多GPU 训练的时候进入到其他的 GPU。
@rank_zero_only
def validation_step(self, batch, batch_idx):
batch: BatchedExample = self.data_shim(batch)
if self.global_rank == 0:
print(
f"validation step {self.global_step};"
)