前言
前几年比较火的是微服务,再然后就是云。讨论技术必谈微服务,要上云,开发出的产品也都是某某云。现在讨论比较少了,因为AI盖过他们。还有就是因为容器技术,现在几乎都是k8s,云原生。要比较快的上手k8s,那么首先要理解容器,而容器的代表无疑是Docker。在这篇文章我介绍容器的运行原理,如果理解了背后的原理。那么容器也就不再陌生了。
容器背景
一项技术能够火前提它划时代解决了行业当前问题的痛点,在以前我们要打包部署,就是安装教程安装一个另一个包。特别繁琐不说,还有因为测试和生产环境不一致。测试没问题,而到了生产环境就行了。这让很多开发和运维头疼不已,这时候有家公司做了小小创新。就是将要部署的项目连着运行的操作系统一起打包在一个压缩包里,这样不管部署在哪个环境。因为这个压缩包里都包含着,操作系统那么到哪都一样了。既然操作系统,都带着了,那么可不可以将要安装的项目,一些环境预安装。也就是需要哪些环境,都安装好。
我们先从头想一下,举个例子。我要安装nginx,在传统安装方式我要安装。每次都要执行一大推命令,构造环境。一个比较简单的方式,将这样命令都封装近shell脚本。这样每次安装,我也要执行一个命令即可。这有个问题,就是安装环境不一致。有时候需要适配你环境,那么你的脚本就需要去判断兼容。这时候你特别烦,想着能不能让所有环境操作系统都一致。让就将这个操作系统和项目打包在一起,这样这个压缩包到哪都能运行了。
以上压缩包就是我们说得docker镜像。这边还有一个问题,就是我测试环境和生产环境配置一些存储,网络不太一样。其他地方都一样,就是有些需要自定义配置,有些不需要。这边针对镜像做一些配置修改,运行起来的进程就是容器。
镜像
镜像概念
在讨论镜像前,先讨论下面对对象编程里提到的复用。就是如果我们有公共的代码,那么就提取出来。写成一个方法,让其他人也调用。这样公共的代码,可以被其他人调用。复用主要是为了方便将来维护,提高代码健壮性。而镜像思想和代码里复用,实际是一样的。就是我将部署的项目和操作系统一起打包,那最底层的操作系统和我们公共代码类似。不同镜像底层用的操作系统都一样,那么我将底层的操作系统提取出来,让大家都可以公用。这样我就减少了维护操作系统的成本。安装这个思路就有了镜像分层的实现方法。
镜像分层(Image Layering)是指将容器镜像(如Docker镜像)分解为一系列的只读层,每一层都依赖于前一层。这些层共同构成了完整的镜像。每一层通常包含了一系列文件和文件夹的变化(如添加、修改或删除)。
基础层(Base Layer):最底层,通常是操作系统或最小化的运行环境。
中间层(Intermediate Layers):在基础层之上,包含应用依赖、配置等。(Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。)
应用层(Application Layer):最高层,包含应用代码及其配置。
应用层是可读写的,就是我们可以对镜像做一些配置;而中间层一个以“-init”结尾的层,夹在只读层和读写层之间;基础层和中间层都可以逻辑删除,就是如果用户不需要一些插件那么可以通过wh(whiteout)实际就是逻辑删除,让在容器中看不到
镜像实例
下面我们看看具体的列子
# 基础镜像
# Dockerfile 中的每个原语执行后,都会生成一个对应的镜像层 (也就是说有几层,那么有几层镜像)
# 使用 OpenJDK 8 JRE 作为基础镜像
# 这创建了基础层,包含 Java 运行环境
FROM openjdk:8-jre
# 创建目录 /dream/server/temp
# 新增一层用于存储临时文件
RUN mkdir -p /dream/server/temp
# 创建目录 /var/logs/dump
# 新增一层用于存储日志和转储文件
RUN mkdir -p /var/logs/dump
# 设置时区为上海,复制时区信息到系统配置
# 新增一层更改时区设置
RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 设置时区名称
# 新增一层写入时区名称到配置文件
RUN echo "Asia/Shanghai" > /etc/timezone
# 添加应用程序 JAR 文件到镜像
# 新增一层包含应用程序的 JAR 文件
ADD dream-order.jar ./dream-order.jar
# 设置 JVM_OPTS 环境变量,默认为空
# 新增一层用于定义环境变量
ENV JVM_OPTS=""
# 定义容器启动时的默认命令
# 这将启动应用程序,使用 JVM_OPTS 环境变量配置 JVM
CMD java ${JVM_OPTS} -jar dream-order.jar
上面的每个命令都会生成一层镜像,最后我们看到的镜像就是一层层累加的。上面一层镜像,是基于下面一层镜像。这个特别像我们盖楼房,一层层。有没发现这个和我们的互联网协议五层模型特别像。
互联网协议五层模型:
1.物理层(Physical Layer):就是把电脑连接起来的物理手段。它主要规定了网络的一些电气特性,作用是负责传送0和1的电信号
2.数据链路层(Data Link Layer): 数据链路层负责在物理介质上可靠地传输数据帧。它处理物理寻址(通常是MAC地址)、帧的封装和解封装(将网络层提供的数据包封装为帧)、
帧分发和交换(Frame Distribution and Switching)、流量控制、错误检测和纠正等。以太网、Wi-Fi、PPP(Point-to-Point Protocol)。
3.网络层(Network Layer): 网络层(network layer)主要包括以下两个任务:
(1) 负责为分组交换网上的不同主机提供通信服务。在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组或包进行传送。在TCP/IP体系中,由于网络层使用IP协议,因此分组也叫做IP数据报,或简称为数据报。
(2) 选中合适的路由,使源主机运输层所传下来的分组,能够通过网络中的路由器找到目的主机。 协议:IP,ICMP,IGMP,ARP,RARP
4.传输层( Transport Layer):运输层(transport layer):负责向两个主机中进程之间的通信提供服务。
由于一个主机可同时运行多个进程,因此运输层有复用和分用的功能 :
复用,就是多个应用层进程可同时使用下面运输层的服务。
分用,就是把收到的信息分别交付给上面应用层中相应的进程。
运输层主要使用以下两种协议:
(1) 传输控制协议TCP(Transmission Control Protocol):面向连接的,数据传输的单位是报文段,能够提供可靠的交付。
(2) 用户数据包协议UDP(User Datagram Protocol):无连接的,数据传输的单位是用户数据报,不保证提供可靠的交付,只能提供“尽最大努力交付”
5.应用层(Application Layer):应用层(application layer):是体系结构中的最高。直接为用户的应用进程(例如电子邮件、文件传输和终端仿真)提供服务。
在因特网中的应用层协议很多,如支持万维网应用的HTTP协议,支持电子邮件的SMTP协议,支持文件传送的FTP协议,DNS,POP3,SNMP,Telnet等等。
道通为一,这么实现方式就是为了复用。
docker之所以这么火,是做了一个小小的创新就是镜像分层思想,解决了打包部署问题。这个行业的痛点问题,有时候解决一个比较大的问题,并不需要很难的技术和很复杂的思想,可能就是实现方式上的一个小创新。
容器
上面我们说到的镜像,解决了我们打包的问题,并且通过复用这一思想,将镜像进行分层。这边我们在使用中还遇到问题,就是每个容器都很小。那么我们不可能在一个物理机上就运行一个容器,这就导致一个物理机运行着多个容器。这时候,我们就特别害怕。害怕什么呢,就是因为没有隔离,那么可能出现一个容器的问题,导致当前这个物理机所有的容器都宕机。
在这里,举个现实生活中例子。古代海上丝绸之路的船,将每个船舱用隔舱板隔开。这样如果遇到触礁等海上事故,只会有当前这个船舱有问题,而其他货物因为有分割开不受影响。这就降低了风险。以上用到的技术就是隔离。那么放在容器里也是一样。我将每个容器都隔离,这样让容器不影响其他容器运行。一旦容器宕机只会影响当前容器,这就是隔离思想。还有当前容器如果不进行限制,那么会出现当前容器把物理机的CPU,内存,带宽等计算机资源占用了。而导致其他容器无法正常工作。上面提到的问题,需要解决的问题就是隔离和限制。
容器其实是一种沙盒技术.沙盒就是能够像一个集装箱一样,把你的应用“装”起来的技术。这样,应用与应用之间,就因为有了边界而不至于相互干扰;而被装进集装箱的应用,也可以被方便地搬来搬去.
隔离和限制
容器,其实是一种特殊的进程而已。Docker 容器使用了 PID 命名空间来隔离进程。
上面这句话,告诉我们容器就是进程。进程简单说就是运行中的程序。
进程是操作系统对正在运行的程序抽象,并发运行是一个进程的指令和另一个进程的指令是交错进行,操作系统实现这种交错执行的机制称为上下文切换。
你说容器就是一种特殊的进程,那么我用 ps指令也能看到这个进程吧。然后用 ps执行了,没有看到容器进程。带着这个疑问,你想到查看正在运行的容器命令是 docker ps。这两个指令都差不多,是不是功能都非常像呢。带着这个疑问,我们先讲下Linux里的两个技术Cgroups和Namespace。
ps命令(Process Status)
实际要真正理解容器技术,那么需要掌握Linux的Cgroups和Namespace,理解了以上两种技术那么容器也就真正理解了。所以容器并不是什么神奇的技术,只是对Linux的两个特性一种应用罢了。
容器底层技术:cgroup实现资源限额,namespace实现资源隔离。
Namespace
Namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。宿主机来说,这些被“隔离”了的进程跟其他进程并没有太大区别。
上面我们说到ps和docker ps指令,这两个有什么关系吗。下面我将用ps命令,获取容器进程信息。
[root@localhost ~]# docker inspect --format '{{.State.Pid}}' d0bf1104b641
25605
[root@localhost ~]# ps --forest -p 25605
PID TTY TIME CMD
25605 ? 01:30:23 mysqld
这里直接使用ps命令,查询不到该容器的相关信息,只有使用加上指定进程ID才行。这里用到了Namespace里的PID隔离。
[root@localhost ~]# ps
PID TTY TIME CMD
24482 pts/0 00:00:00 ps
29940 pts/0 00:00:00 bash
[root@localhost ~]#
当然Linux 名称空间(namespace)不止有PID隔离,还有以下不同的隔离信息。
Linux 名称空间(namespace)支持以下八种资源的隔离
Mount 隔离文件系统,功能上大致可以类比 chroot.每个挂载命名空间都有自己的文件系统挂载点,使得不同命名空间可以拥有不同的文件系统视图。
UTS 每个UTS命名空间都有自己的主机名和域名,实现了主机名和域名的隔离。
IPC 每个IPC命名空间都有自己的System V IPC对象(如信号量、共享内存、消息队列),实现了进程间通信的隔离。
PID 隔离进程编号,无法看到其他名称空间中的 PID,意味着无法对其他进程产生影响.(使用int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL); 创建进程,)
Network 每个网络命名空间都有自己的网络设备、IP地址、路由表、网络连接等,实现了网络资源的隔离。
User 每个用户命名空间都有自己的用户和用户组标识符,使得不同命名空间中的用户和用户组相互隔离。
Cgroup 隔离 cgroups 信息,进程有自己的 cgroups 的根目录视图在/proc/self/cgroup 不会看到整个系统的信息)
Time 隔离系统时间,2020 年 3 月最新的 5.6 内核开始支持进程独立设置系统时间
Mount namespace让容器看上去拥有整个文件系统;UTS namespace让容器有自己的hostname;IPC namespace让容器拥有自己的共享内存和信号量(semaphore)来实现进程间通信;容器拥有自己独立的一套PID,这就是PID namespace提供的功能;Network namespace让容器拥有自己独立的网卡、IP、路由等资源;User namespace让容器能够管理自己的用户,host不能看到容器中创建的用户。
上面提到的Mount namespace,PID namespace,Network namespace在平时我们用的比较多。后面我会教详细的讲解,这边大家有个概念。
cgroups
Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制(不让一个进程把所有资源都占用了)
Linux Cgroups 的全称是 Linux Control Groups。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
说白了就是,限制当前运行的容器能够使用多少资源。为了防止容器异常,占用宿主机所有资源。而导致其他容器因获取不到资源也引起异常。
我们看下cgroups,我们访问 /sys/fs/cgroup/cpu 目录
[root@localhost docker]# cd /sys/fs/cgroup/cpu
[root@localhost cpu]# ll
total 0
-rw-r--r--. 1 root root 0 Mar 11 15:41 cgroup.clone_children
--w--w--w-. 1 root root 0 Mar 11 15:41 cgroup.event_control
-rw-r--r--. 1 root root 0 Mar 11 15:41 cgroup.procs
-r--r--r--. 1 root root 0 Mar 11 15:41 cgroup.sane_behavior
-r--r--r--. 1 root root 0 Mar 11 15:41 cpuacct.stat
-rw-r--r--. 1 root root 0 Mar 11 15:41 cpuacct.usage
-r--r--r--. 1 root root 0 Mar 11 15:41 cpuacct.usage_percpu
-rw-r--r--. 1 root root 0 Mar 11 15:41 cpu.cfs_period_us
-rw-r--r--. 1 root root 0 Mar 11 15:41 cpu.cfs_quota_us
-rw-r--r--. 1 root root 0 Mar 11 15:41 cpu.rt_period_us
-rw-r--r--. 1 root root 0 Mar 11 15:41 cpu.rt_runtime_us
-rw-r--r--. 1 root root 0 Mar 11 15:41 cpu.shares
-r--r--r--. 1 root root 0 Mar 11 15:41 cpu.stat
drwxr-xr-x. 9 root root 0 Jun 6 09:49 docker
-rw-r--r--. 1 root root 0 Mar 11 15:41 notify_on_release
-rw-r--r--. 1 root root 0 Mar 11 15:41 release_agent
drwxr-xr-x. 75 root root 0 Jun 11 15:58 system.slice
-rw-r--r--. 1 root root 0 Mar 11 15:41 tasks
drwxr-xr-x. 2 root root 0 Mar 12 10:46 user.slice
[root@localhost cpu]#
这里我们发现有个docker文件夹,我们点进去。发现有很多随机字符串的文件夹,仔细一看随机数和容器id有点像。
drwxr-xr-x. 2 root root 0 Jun 6 09:49 2d33003123e8798a0e2b393bfa42d6aa5a0068ef329c2d6be57d7d02b0c29a37
drwxr-xr-x. 2 root root 0 Jun 4 10:10 5934dce0f09a32cfddf01bb17cce4982f388afa0010653f377b7a224ac0857d8
drwxr-xr-x. 2 root root 0 May 21 11:08 a13ebc7910f124ac235275055db58d2b87a577232aeffd25732fe343916e7056
drwxr-xr-x. 2 root root 0 May 21 16:00 bd0852ed6b63a66a350cb7e97c9584a57716dad58d782138a4b575c5c3596980
drwxr-xr-x. 2 root root 0 Jun 3 10:53 buildkit
drwxr-xr-x. 2 root root 0 Mar 12 11:16 cb7f7afeee8caa0d9b8fe79763611d6f9a06ae021fb4fefbb72e157cd59b814c
-rw-r--r--. 1 root root 0 Mar 12 11:15 cgroup.clone_children
--w--w--w-. 1 root root 0 Mar 12 11:15 cgroup.event_control
-rw-r--r--. 1 root root 0 Mar 12 11:15 cgroup.procs
-r--r--r--. 1 root root 0 Mar 12 11:15 cpuacct.stat
-rw-r--r--. 1 root root 0 Mar 12 11:15 cpuacct.usage
-r--r--r--. 1 root root 0 Mar 12 11:15 cpuacct.usage_percpu
-rw-r--r--. 1 root root 0 Mar 12 11:15 cpu.cfs_period_us
-rw-r--r--. 1 root root 0 Mar 12 11:15 cpu.cfs_quota_us
-rw-r--r--. 1 root root 0 Mar 12 11:15 cpu.rt_period_us
-rw-r--r--. 1 root root 0 Mar 12 11:15 cpu.rt_runtime_us
-rw-r--r--. 1 root root 0 Mar 12 11:15 cpu.shares
-r--r--r--. 1 root root 0 Mar 12 11:15 cpu.stat
drwxr-xr-x. 2 root root 0 May 21 10:35 d0bf1104b64151847646b12b36041cc9b8bafb151ebcfa1e51af77e084249c3a
-rw-r--r--. 1 root root 0 Mar 12 11:15 no
对比一下发现就是容器id,d0bf1104b641和d0bf1104b64151847646b12b36041cc9b8bafb151ebcfa1e51af77e084249c3a
docker ps指令 CONTAINER ID: 显示每个容器的唯一 ID(前 12 位)
Linux CPU 管理,限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间。我们可以查看,对CPU资源的限制。
[root@localhost d0bf1104b64151847646b12b36041cc9b8bafb151ebcfa1e51af77e084249c3a]# cat cpu.cfs_period_us
100000
[root@localhost d0bf1104b64151847646b12b36041cc9b8bafb151ebcfa1e51af77e084249c3a]# cat cpu.cfs_quota_us
-1
因为前面我创建的容器,没有对CPU资源进行限制所以是-1.读者可以尝试下,运行容器增加资源的限制。这边目录值是否会更改。
进入到容器
我们知道要进入到容器,执行指令 docker exec -it <CONTAINER_ID> /bin/bash
[root@localhost ~]# docker exec -it d0bf1104b641 /bin/bash
root@d0bf1104b641:/# ls
bin docker-entrypoint-initdb.d home media proc sbin tmp
boot entrypoint.sh lib mnt root srv usr
dev etc lib64 opt run sys var
在前面我们说过了容器就是一个特殊的进程,要进入到容器,实际也就是访问当前这个特殊的进程。我们在宿主机里看不到,因为使用namespace进行隔离了。
#define _GNU_SOURCE
#include <fcntl.h>
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
// 定义错误处理宏,用于打印错误信息并退出程序
#define errExit(msg) \
do { \
perror(msg); \
exit(EXIT_FAILURE); \
} while (0)
// 运行指令 ./set_ns /proc/27522/ns/net /bin/bash
int main(int argc, char* argv[]) {
int fd;
// 检查命令行参数是否足够
if (argc < 3) {
fprintf(stderr, "Usage: %s <namespace-file> <command> [<arg>...]\n", argv[0]);
exit(EXIT_FAILURE);
}
// 打开指定的命名空间文件,只读方式
fd = open(argv[1], O_RDONLY);
if (fd == -1) {
errExit("open");
}
// 使用 setns 系统调用将当前进程加入到指定的命名空间
// 在 setns() 之后我看到的这两个网卡,正是我在前面启动的 Docker 容器里的网卡。也就是说,我新创建的这个 /bin/bash 进程,由于加入了该容器进程(PID=25686)的 Network Namepace,它看到的网络设备与这个容器里是一样的,即:/bin/bash 进程的网络设备视图,也被修改了。
if (setns(fd, 0) == -1) {
errExit("setns");
}
// 关闭命名空间文件描述符
close(fd);
// 使用 execvp 系统调用执行指定的命令,并将参数传递给该命令
// argv[2] 是命令名,&argv[2] 是参数数组(包括命令名本身)
execvp(argv[2], &argv[2]);
// 如果 execvp 返回,说明执行失败,调用错误处理宏
errExit("execvp");
}
执行 ./set_ns /proc/27522/ns/net 旨在将当前进程加入到目标进程(PID 27522)的网络命名空间,我们可以看下执行前的ifconfig信息和执行后的ifconfig信息,同时查看该容器的ifconfig信息。通过将当前进程加入到目标进程,我们实现了进入容器操作。
进入到容器后,我们发现这个目录很像Linux的根目录。
root@d0bf1104b641:/# ls -l
total 8
drwxr-xr-x. 2 root root 4096 Dec 20 2021 bin
drwxr-xr-x. 2 root root 6 Oct 3 2021 boot
drwxr-xr-x. 15 root root 3000 May 21 10:35 dev
drwxr-xr-x. 2 root root 6 Dec 21 2021 docker-entrypoint-initdb.d
lrwxrwxrwx. 1 root root 34 Dec 21 2021 entrypoint.sh -> usr/local/bin/docker-entrypoint.sh
drwxr-xr-x. 1 root root 66 May 21 10:35 etc
drwxr-xr-x. 2 root root 6 Oct 3 2021 home
drwxr-xr-x. 1 root root 30 Dec 21 2021 lib
drwxr-xr-x. 2 root root 34 Dec 20 2021 lib64
drwxr-xr-x. 2 root root 6 Dec 20 2021 media
drwxr-xr-x. 2 root root 6 Dec 20 2021 mnt
drwxr-xr-x. 2 root root 6 Dec 20 2021 opt
dr-xr-xr-x. 270 root root 0 May 21 10:35 proc
drwx------. 1 root root 27 Jun 12 15:26 root
drwxr-xr-x. 1 root root 20 Dec 21 2021 run
drwxr-xr-x. 2 root root 4096 Dec 20 2021 sbin
drwxr-xr-x. 2 root root 6 Dec 20 2021 srv
dr-xr-xr-x. 13 root root 0 Mar 11 15:41 sys
drwxrwxrwt. 1 root root 6 Jun 5 17:13 tmp
drwxr-xr-x. 1 root root 19 Dec 20 2021 usr
drwxr-xr-x. 1 root root 41 Dec 20 2021 var
带着这个疑问,我们查看当前容器的信息详情
docker inspect d0bf1104b641
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/f9e2b217feaec95f6811c2354b9bfe59be443a770565e2ed38cbb38bc9639091-init/diff:/var/lib/docker/overlay2/540a590cbbdc30df3d48c76bfe67a9e45fd6e96a8d9e49e9effbc15628f76971/diff:/var/lib/docker/overlay2/529af2e89e51b53072aae514cd312ba2c35144424b997197a9021911d7d80c2b/diff:/var/lib/docker/overlay2/ed13e3b63eb6dc85110260c960eaabedbadf762229049efb5b6a72b1a6b295aa/diff:/var/lib/docker/overlay2/3bb2e99b675ac312eea6189b914d7bf69d556ca2dfde16bea172b99e37493d60/diff:/var/lib/docker/overlay2/accd4ed580d553fe878471d7024fe1a8c703eb0b32e2da4261127aa390c71bea/diff:/var/lib/docker/overlay2/4ae095b1bb58a374139ee6d79435120be808e28f67d523d11a4a89c0d44350c7/diff:/var/lib/docker/overlay2/2a619c666b518530514c673d8f9849714317eb91378a358062ec7e80585f47fa/diff:/var/lib/docker/overlay2/f33115ab6c3d33e7b9b997792a9047bd4331a52795cd5f964d2d259b657ff39e/diff:/var/lib/docker/overlay2/8d761bb724a960cd85c2547f085dd050532a556c120b4e9f26bd80948679d8c8/diff:/var/lib/docker/overlay2/126004d9bb2a06beb2220bae780935c131429a4d07769e5d9cd1c5bec7451614/diff:/var/lib/docker/overlay2/5437b28cad9e653e278d992ae903f8389be2bb2043ce4f8b754690ba83afa69d/diff:/var/lib/docker/overlay2/cdeee2f669c901e67d464aff46cf42f2b01e5b7e30e8beeaf7d86af82232201f/diff",
"MergedDir": "/var/lib/docker/overlay2/f9e2b217feaec95f6811c2354b9bfe59be443a770565e2ed38cbb38bc9639091/merged",
"UpperDir": "/var/lib/docker/overlay2/f9e2b217feaec95f6811c2354b9bfe59be443a770565e2ed38cbb38bc9639091/diff",
"WorkDir": "/var/lib/docker/overlay2/f9e2b217feaec95f6811c2354b9bfe59be443a770565e2ed38cbb38bc9639091/work"
},
"Name": "overlay2"
}
LowerDir: 包含基础镜像和中间镜像层的路径。
MergedDir: 组合所有层的目录,用于容器的运行时视图。
UpperDir: 容器文件系统的最顶层,保存容器运行时的修改。
WorkDir: overlay2 用于操作的临时目录。
这段 JSON 数据来自 Docker 容器的 inspect 输出,描述了容器的文件系统信息。Docker 使用 存储驱动(在这个例子中是 overlay2)来管理容器的文件系统层。GraphDriver 部分展示了这些层的具体路径。
overlay2 是 Docker 的默认存储驱动(在较新的 Linux 内核中),使用 OverlayFS 来实现高效的文件系统层叠加。它通过将多个目录(层)组合成一个文件系统视图(合并层)来工作。
在前面介绍的镜像中,我们描述过镜像为了复用,同时方便用户自定义修改配置。镜像构成是一层一层,叠加起来的。这边镜像使用的技术是 联合文件系统(Union File System, UnionFS)
联合文件系统(Union File System, UnionFS)是一种允许多个文件系统以叠加(union)的方式组合成一个单一的文件系统视图的文件系统。联合文件系统通过将不同层次的文件系统合并为一个单独的文件系统,使得用户可以同时访问所有层次的文件和目录
Union File System 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。(A:a和x目录 B:b和x ,新的目录挂载A和B那么C:a,b,x (x最终只有一份))
AUFS(Another Union File System)是 Docker 早期版本中使用的一种联合文件系统,现在用OverlayFS 和 Overlay2(docker默认)。
我们这边查看MergedDir目录,发现这个目录内容和我们进入到容器里看到一模一样。
[root@localhost ~]# cd /var/lib/docker/overlay2/f9e2b217feaec95f6811c2354b9bfe59be443a770565e2ed38cbb38bc9639091/merged
[root@localhost merged]# ll
total 8
drwxr-xr-x. 2 root root 4096 Dec 20 2021 bin
drwxr-xr-x. 2 root root 6 Oct 3 2021 boot
drwxr-xr-x. 1 root root 43 May 21 10:35 dev
drwxr-xr-x. 2 root root 6 Dec 21 2021 docker-entrypoint-initdb.d
lrwxrwxrwx. 1 root root 34 Dec 21 2021 entrypoint.sh -> usr/local/bin/docker-entrypoint.sh
drwxr-xr-x. 1 root root 66 May 21 10:35 etc
drwxr-xr-x. 2 root root 6 Oct 3 2021 home
drwxr-xr-x. 1 root root 30 Dec 21 2021 lib
drwxr-xr-x. 2 root root 34 Dec 20 2021 lib64
drwxr-xr-x. 2 root root 6 Dec 20 2021 media
drwxr-xr-x. 2 root root 6 Dec 20 2021 mnt
drwxr-xr-x. 2 root root 6 Dec 20 2021 opt
drwxr-xr-x. 2 root root 6 Oct 3 2021 proc
drwx------. 1 root root 27 Jun 12 15:26 root
drwxr-xr-x. 1 root root 20 Dec 21 2021 run
drwxr-xr-x. 2 root root 4096 Dec 20 2021 sbin
drwxr-xr-x. 2 root root 6 Dec 20 2021 srv
drwxr-xr-x. 2 root root 6 Oct 3 2021 sys
drwxrwxrwt. 1 root root 6 Jun 5 17:13 tmp
drwxr-xr-x. 1 root root 19 Dec 20 2021 usr
drwxr-xr-x. 1 root root 41 Dec 20 2021 var
这里我们基本上可以猜想,我们在容器里看到的目录,就是以上宿主机里的目录。这边他们用到的一个技术 Mount Namespace。
Mount Namespace 正是基于对 chroot 的不断改良才被发明出来的,它也是 Linux 操作系统里的第一个 Namespace。
chroot 是一个 Unix 和类 Unix 系统中的命令,更改当前进程及其子进程的根目录(即 / 目录)。它将指定的目录作为新的根目录,并限制进程对文件系统的访问范围,使得进程只能访问指定目录及其子目录下的文件.
这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
有时候我们想自定义容器输出文件目录,比如一些配置文件,日志文件。我们希望在宿主机里目录,目录里也能看到,容器关闭和停止了也还在。那么我们也可以自己挂载。
version : '3.8'
services:
redis:
image: redis:6.2.6
container_name: redis
ports:
- "6379:6379"
volumes:
- /data/redis/datadir:/data
- /data/redis/conf/redis.conf:/usr/local/etc/redis/redis.conf
- /data/redis/logs:/logs
command: redis-server --requirepass 123456
restart: always
以上docker-compose Redis例子,就是将容器里和宿主机绑定挂载了。这样我们可以直接在宿主机里就能看到相关内容了。
绑定挂载(bind mount)是 Linux 中的一种文件系统挂载机制,它允许将一个现有的目录或文件挂载到另一个位置。与传统的挂载不同,绑定挂载不需要新的文件系统,只是将现有的目录或文件在另一个位置进行重新映射。
绑定挂载实际上是一个 inode 替换的过程。在 Linux 操作系统中,inode 可以理解为存放文件内容的“对象”,而 dentry,也叫目录项,就是访问这个 inode 所使用的“指针”。(就是更改文件的指向)
docker inspect 是 Docker 命令行工具中的一个命令,用于获取 Docker 容器或镜像的详细信息。它返回一个 JSON 格式的输出,包含了关于指定对象(容器或镜像)的各种详细信息。
那么Docker容器实际为我们做什么了:
启用 Linux Namespace 配置;(隔离,宿主机之间的进程)
设置指定的 Cgroups 参数;(限制容器的资源)
切换进程的根目录(Change Root)。(更改它的挂载目录)
如果我们要自己实现容器,那么只要实现以上操作即可
说了这么多,对容器有了大概的认识和了解。那么容器和虚拟机有什么区别呢
在以上描述中,容器隔离和限制都是通过Linux操作系统完成,Docker没有自己实现这方便。这不像虚拟机需要运行一个完整的操作系统出来,同时虚拟机的虚拟化技术,都要通过虚拟软件转发。效率明显会更低。在这里大家有没故意到Docker容器是利用Linux的cgroup实现资源限额,namespace实现资源隔离。那么Microsoft Windows和Apple Mac,没有这些技术那么怎么运行容器。这边实际是Microsoft Windows和Apple Mac虚拟化出一个轻量级Linux,再运行Docker Engine。
容器网络
在前面我们为了安全,使容器之间相互隔离,不互相影响。但是在很多情况下,我们又希望容器之间能够互相访问,容器能够被外界访问,容器也能访问外面的网络。这就涉及到容器和容器之间,容器和宿主机之间,容器和互联网之间。
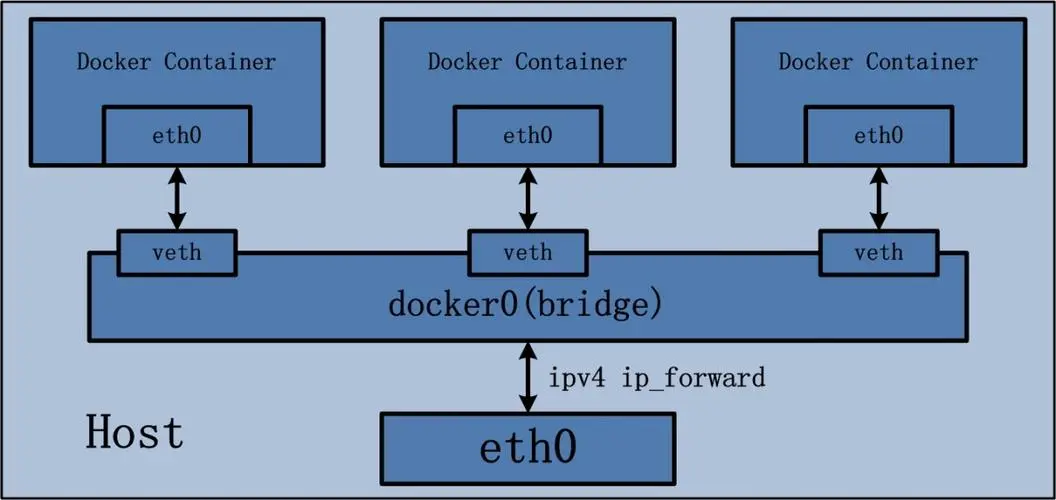
根据前面的信息,容器之间是隔离的。这有点像,一个地方被一条河分割开了。这两块地,因为这条河彼此都没交流。现在想交流了,那么就建一座桥。网络之间也是,在这里叫网桥。
docker0 的工作原理
1. 创建 docker0 网桥
当 Docker 服务启动时,会自动创建一个名为 docker0 的网桥。
该网桥拥有一个 IP 地址(默认是 172.17.0.1),并创建一个子网(默认是 172.17.0.0/16)。
2. 容器连接到 docker0
当一个新容器启动并加入桥接网络时,Docker 会为该容器分配一个虚拟网卡(veth)。
这个虚拟网卡的一端连接到容器内部,另一端连接到 docker0 网桥。
容器获取一个来自 docker0 网桥的子网 IP 地址,例如 172.17.0.2。
3. 网络流量处理
容器之间的通信:容器通过 docker0 网桥可以相互直接通信。例如,容器 A(172.17.0.2)可以 ping 容器 B(172.17.0.3)。
容器与宿主机的通信:容器可以与宿主机(172.17.0.1)通信,宿主机也可以通过 docker0 网桥访问容器。
容器访问外部网络:当容器访问外部网络时,流量通过 docker0 网桥,然后进行 NAT 转换,使用宿主机的网络接口访问外部网络。
我们用ifconfig查看网络信息
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:79ff:fe4f:dcab prefixlen 64 scopeid 0x20<link>
ether 02:42:79:4f:dc:ab txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4 bytes 356 (356.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
我们看下IPv4 地址配置
inet 172.17.0.1: docker0 网桥的 IPv4 地址。它是 docker0 网桥的网关地址,用于 Docker 容器与主机通信。
netmask 255.255.0.0: 子网掩码,表示 172.17.0.0 网络中的所有地址可以被 docker0 网桥管理。
broadcast 172.17.255.255: 广播地址,允许将数据包发送到子网内的所有设备
Docker网络类型:none、host、docker_default、bridge
none:没有网络不需要网络时,且对安全要求比较高
host:连接到host网络的容器共享Docker host的网络栈,容器的网络配置与host完全一样。直接使用Docker host的网络最大的好处就是性能,缺点没有隔离就无法避免网络资源的冲突,譬如端口号就不允许重复
bridge:为每个容器分配设置IP,并将容器连接到一个docker0虚拟网桥,默认为该模式
桥接模式,使用 --network=bridge 指定,这种也是未指定网络参数时的默认网络。桥接模式下,Docker 会为新容器分配独立的网络名称空间,创建好 veth pair,一端接入容器,另一端接入到 docker0 网桥上。
Docker 为每个容器自动分配好 IP 地址,默认配置下地址范围是 172.17.0.0/24,docker0 的地址默认是 172.17.0.1,并且设置所有容器的网关均为 docker0,这样所有接入同一个网桥内的容器直接依靠二层网络来通信,在此范围之外的容器、主机就必须通过网关来访问。
下面我们看个具体例子,同样拿上面的Redis例子
version : '3.8'
services:
redis:
image: redis:6.2.6
container_name: redis
ports:
- "6379:6379"
volumes:
- /data/redis/datadir:/data
- /data/redis/conf/redis.conf:/usr/local/etc/redis/redis.conf
- /data/redis/logs:/logs
command: redis-server --requirepass 123456
restart: always
我们看到这边有端口映射,加了端口映射。我们可以通过访问 localhost:6379(假设您在本地运行 Docker)来连接 Redis 服务,该请求会被 Docker 转发到运行 Redis 的容器的 6379 端口。当中的原理就是
端口映射的工作原理
1. 基本概念
容器内部端口: 容器内应用程序监听的端口。
宿主机端口: 宿主机上通过外部网络访问容器服务时使用的端口。
端口映射: 将宿主机端口与容器内部端口连接,使得外部访问宿主机端口时,实际流量会被重定向到容器内部端口。
2. Docker 网桥与 docker0
docker0 是 Docker 创建的默认虚拟网桥,用于连接和隔离容器内部的网络流量。所有加入默认桥接网络的容器都通过 docker0 相互连接。
容器内部网络通过 docker0 网桥连接。
docker0 网桥有一个自己的 IP 子网(如 172.17.0.0/16),用于分配容器 IP 地址。
3. iptables 规则与 NAT
Docker 使用 Linux 内核的 iptables 来配置 NAT(网络地址转换)规则,从而实现端口映射。这些规则负责将宿主机端口上的流量转发到对应容器的内部端口。
NAT: Docker 使用 NAT 来将宿主机端口上的外部流量重定向到容器的 IP 和端口。
iptables: Docker 配置 iptables 来管理流量重定向的规则。以下是一些关键表和链:
PREROUTING: 处理进入主机的数据包,决定它们的路由。
POSTROUTING: 处理离开主机的数据包,执行 NAT 操作。
4. 数据包流动过程
外部请求到宿主机: 外部客户端向宿主机的特定端口(例如,6379)发送请求。
iptables NAT 规则匹配: 宿主机上的 iptables 规则捕获该请求,识别出它需要被转发到 Docker 容器。
重定向到容器: 根据 iptables NAT 规则,请求被重定向到容器的内部 IP(例如,172.17.0.2)和对应端口(例如,6379)。
容器处理请求: 容器内部的服务(例如,Redis)接收并处理该请求。
响应返回: 处理后的响应数据通过相同的路径返回给外部客户端,经过 NAT 和 docker0 网桥返回到宿主机,再到外部客户端。
我们看下关于Redis的iptables规则:
[root@localhost merged]# sudo iptables -t nat -L POSTROUTING -n -v | grep 6379
0 0 MASQUERADE tcp -- * * 172.19.0.3 172.19.0.3 tcp dpt:6379
MASQUERADE 是一个与网络地址转换(NAT)相关的概念,主要用于将本地网络的流量伪装成一个公共 IP 地址以便访问外部网络。
NAT(网络地址转换, Network Address Translation) 是一种通过修改数据包的源或目的地址来实现网络通信的技术。
总结
以上是对容器的一些介绍,书中知识来源于《深入剖析Kubernetes》、《每天5分钟玩转Docker容器技术》 大家有时间可以查阅这两本书籍。