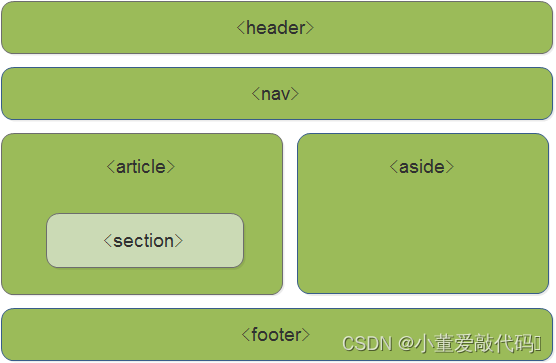
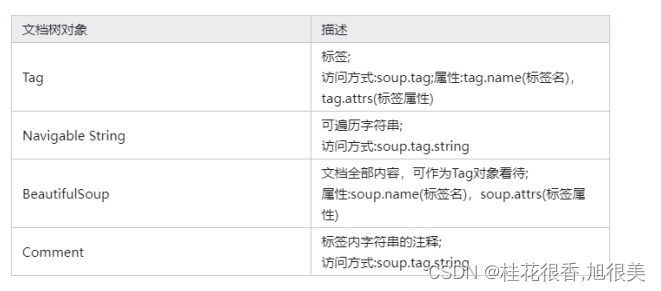
from selectolax.parser import *
import math
class CountInfo:
def __init__(self):
self.textCount = 0
self.linkTextCount = 0
self.tagCount = 0
self.linkTagCount = 0
self.density = 0
self.densitySum = 0
self.score = 0
self.pCount = 0
self.leafList = []
def __str__(self) -> str:
return f"textCount: {self.textCount}, linkTextCount: {self.linkTextCount}, tagCount: {self.tagCount}, linkTagCount: {self.linkTagCount}, density: {self.density}, densitySum: {self.densitySum}, score: {self.score}, pCount: {self.pCount}, leafList: {self.leafList}"
class ContentExtractor:
def __init__(self):
pass
def reload(self, content):
self.doc = HTMLParser(content)
self.infoMap = []
def clear(self):
tags = ["script", "noscript", "style", "iframe", "br"]
self.doc.strip_tags(tags)
def computeInfo(self, node):
if node.tag != "-text":
countInfo = CountInfo()
for child_node in node.iter(include_text=True):
childCountInfo = self.computeInfo(child_node)
countInfo.textCount += childCountInfo.textCount
countInfo.linkTextCount += childCountInfo.linkTextCount
countInfo.tagCount += childCountInfo.tagCount
countInfo.linkTagCount += childCountInfo.linkTagCount
countInfo.leafList.extend(childCountInfo.leafList)
countInfo.densitySum += childCountInfo.density
countInfo.pCount += childCountInfo.pCount
countInfo.tagCount += 1
tagname = node.tag
if tagname == "a":
countInfo.linkTextCount = countInfo.textCount
countInfo.linkTagCount += 1
elif tagname == "p":
countInfo.pCount += 1
pureLen = countInfo.textCount - countInfo.linkTextCount
tag_len = countInfo.tagCount - countInfo.linkTagCount
if pureLen == 0 or tag_len == 0:
countInfo.density = 0
else:
countInfo.density = pureLen / tag_len
self.infoMap.append({"node": node, "countInfo": countInfo})
return countInfo
else:
countInfo = CountInfo()
text = node.text_content
text_len = len(text)
countInfo.textCount = text_len
countInfo.leafList.append(text_len)
return countInfo
def computerVar(self, data):
"""方差"""
if not data:
return 0
if len(data) == 1:
return data[0] / 2
avg = sum(data) / len(data)
return sum((x - avg) ** 2 for x in data) / len(data)
def computeScore(self, countInfo):
"计算得分"
sqrt = math.sqrt(self.computerVar(countInfo.leafList) + 1)
score = (
math.log(sqrt)
* countInfo.densitySum
* math.log(countInfo.textCount - countInfo.linkTextCount + 1)
* math.log10(countInfo.pCount + 2)
)
return score
def getContentElement(self):
self.clear()
if not self.doc.body:
return ""
self.computeInfo(self.doc.body)
content = None
maxScore = 0
for obj in self.infoMap:
node = obj.get("node")
if node.tag == "a" or node.tag == "body":
continue
score = self.computeScore(obj.get("countInfo"))
if score > maxScore:
maxScore = score
content = node
return content

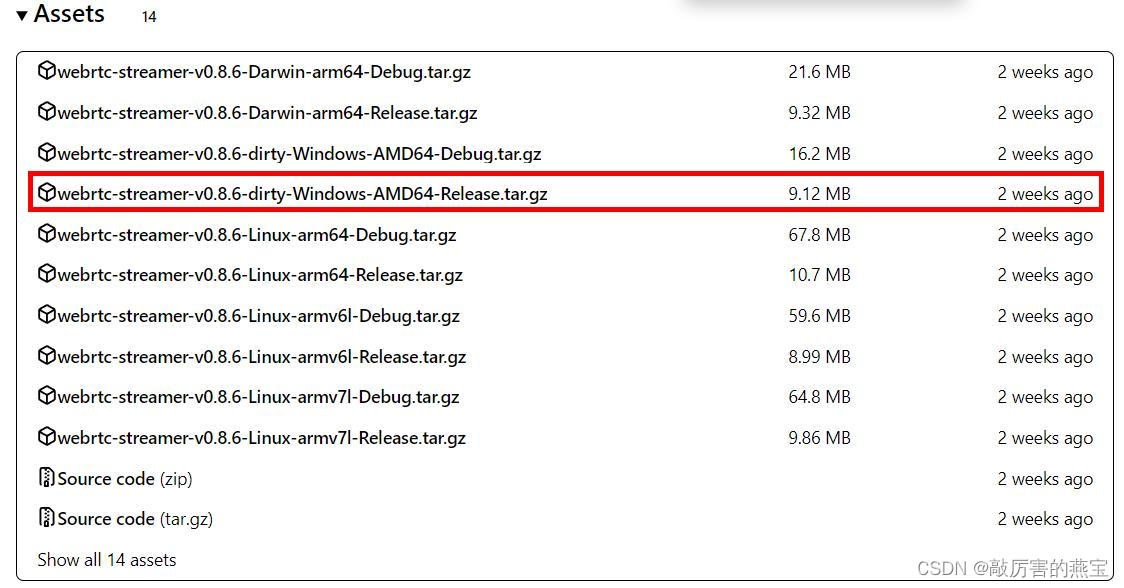
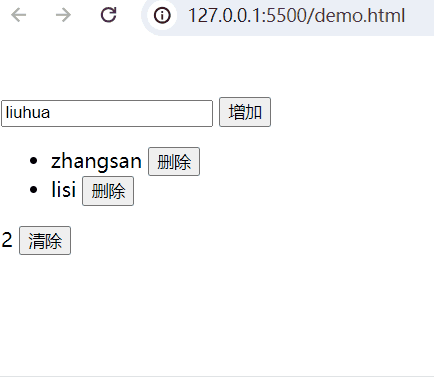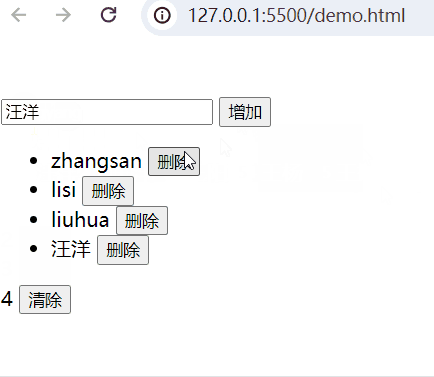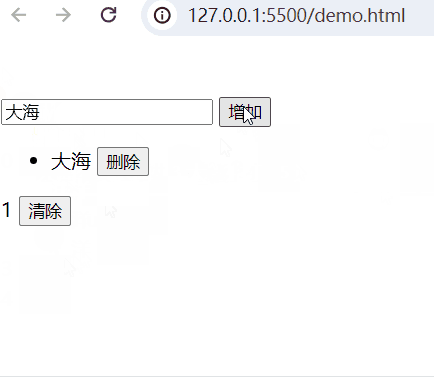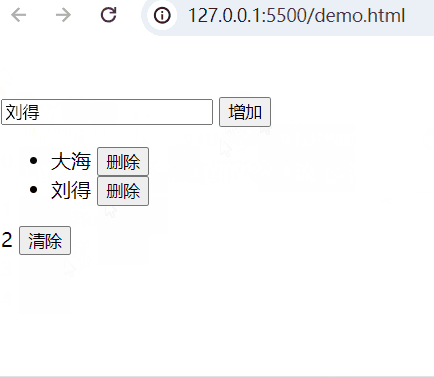
HTML好玩代码(正式版)
2024-06-13 11:24:09 25 阅读