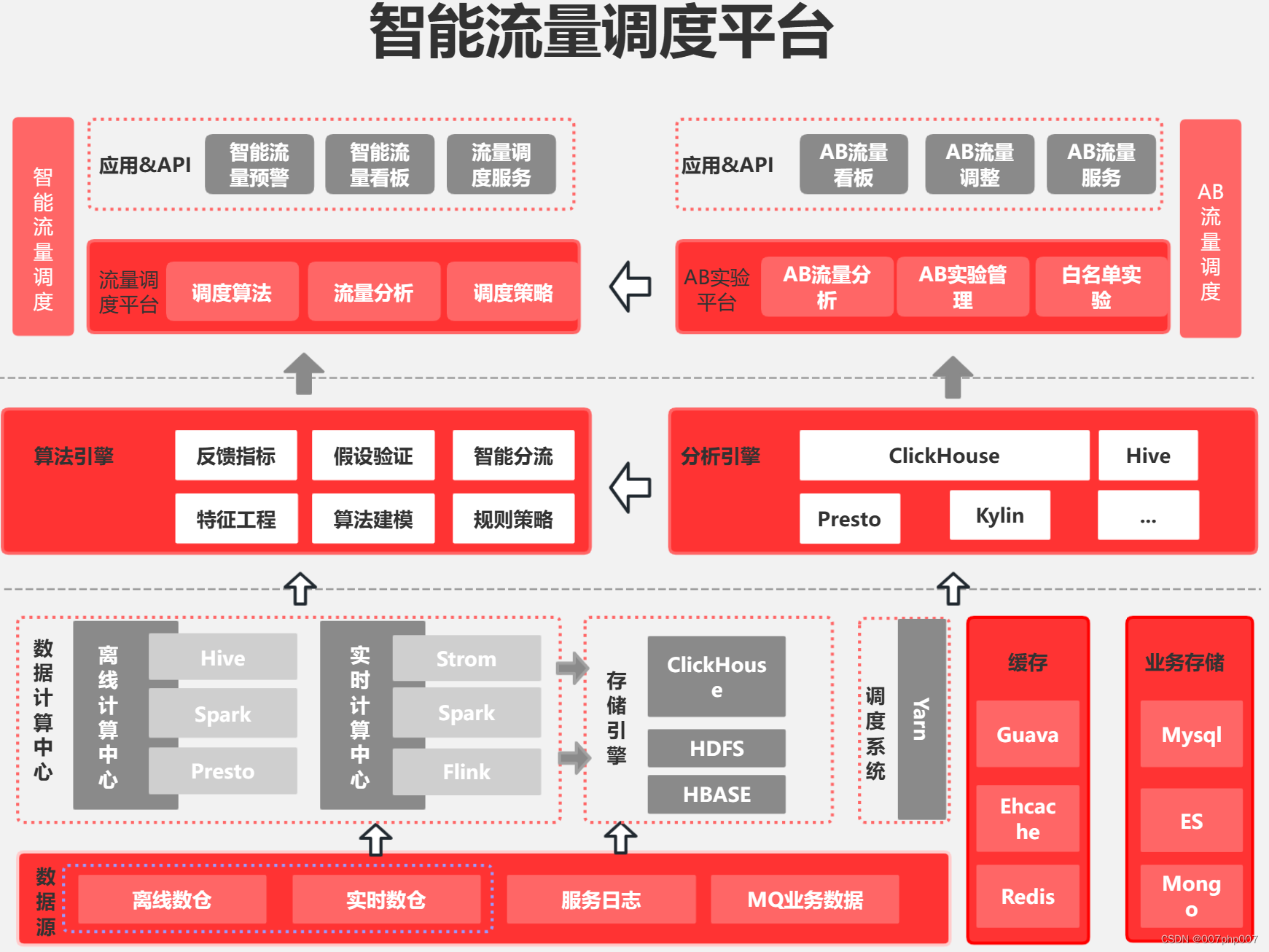
需求是处理一个excel表格
表格结构为:标题、正文的xml文件地址
结果表:标题、处理了xml、html标签后的正文
总代码
import pandas as pd
import xml.etree.ElementTree as ET
import re
if __name__ == '__main__':
baseUrl = "/Desktop/工作项目/AI/工作-语料/**信息/"
# 读取Excel文件
excel_data = pd.read_excel(baseUrl + '**信息.xlsx')
# 创建一个空的列表,用于存储每行的数据
rows_data = []
# 错误计数
cnt = 0
# 总行数
index = 0
# 遍历Excel文件的每一行
for index, row in excel_data.iterrows():
# 读取XML文件路径
xml_path = row['文章正文']
try:
print(index)
# 判断XML文件路径是否为空
if pd.isnull(xml_path):
print('文章正文为空:', row['标题'])
cnt += 1
continue
# 打开XML文件
with open(baseUrl + 'info/' + xml_path, 'r', encoding='utf-8') as file:
html_content = file.read()
tree = ET.fromstring(html_content)
# 提取<content>标签中的内容
content_start = html_content.find('<content>') + len('<content>')
content_end = html_content.find('</content>')
content_text = html_content[content_start:content_end]
# 去除HTML标签
cleaned_text = re.sub('<[^<]+?>', '', content_text)
# 删除所有的
cleaned_text = cleaned_text.replace(' ', '')
# 判断文章正文是否为空
if not cleaned_text:
print('文章正文为空:', row['标题'])
cnt += 1
continue
# 判断正文长度是否小于100
if len(cleaned_text) < 100:
print('文章正文长度小于100:', row['标题'])
print('文章正文:', cleaned_text)
cnt += 1
continue
# 添加到列表中
rows_data.append({'标题': row['标题'], '文章正文': cleaned_text})
except Exception as e:
print('-----------------------error:', row['标题'])
print('Exception type:', type(e).__name__)
print('Error message:', e)
# 创建新的DataFrame
new_data = pd.DataFrame(rows_data)
print(cnt)
# 导出到Excel文件
new_data.to_excel(baseUrl + 'new_file.xlsx', index=False)
其中
1. excel导入、导出
使用pandas,例子:
import pandas as pd
# 读取Excel文件
excel_data = pd.read_excel('file.xlsx')
# 打印数据
print(excel_data)
遍历每一行:
for index, row in excel_data.iterrows():
取出某一列的所有行:
import pandas as pd
# 读取Excel文件
excel_data = pd.read_excel('file.xlsx')
# 读取特定列数据,比如第一列
column_data = excel_data['ColumnName']
导出数据:
rows_data = [{'标题': '标题', '文章正文': '文章正文'}]
# 创建新的DataFrame
new_data = pd.DataFrame(rows_data)
# 导出到Excel文件
new_data.to_excel(baseUrl + 'new_file.xlsx', index=False)
2. python打开本地文件
with open(baseUrl + 'info/' + xml_path, 'r', encoding='utf-8') as file:
html_content = file.read()
3. 抽取数据并去掉标签
# 提取<content>标签中的内容
content_start = html_content.find('<content>') + len('<content>')
content_end = html_content.find('</content>')
content_text = html_content[content_start:content_end]
# 去除HTML标签
cleaned_text = re.sub('<[^<]+?>', '', content_text)
# 删除所有的
cleaned_text = cleaned_text.replace(' ', '')