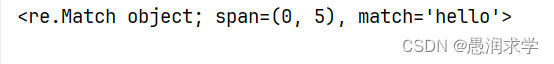目录
一、正则表达式与 re 模块
正则表达式(regular expression)是一种用于匹配和操作文本的强大工具,它是由一系列字符和特殊字符组成的模式字符串,用于描述、匹配一系列符合某个句法规则的字符串。
re 模块拥有全部的正则表达式功能,以及与这些功能对应的函数,这些函数使用一个模式字符串作为第一个参数。
二、匹配函数与模式符
1. 匹配对象与读取函数
re 模块中的匹配函数的返回值有时是一个特殊对象Match,经读取才能获取我们想要的数据类型。
Match.group():返回匹配子串(默认参数值为0,参数用法见下文的组合类元字符)Match.groups():返回各个分组的匹配子串的元组Match.span():返回匹配子串的索引范围
2. 单字符与 match() 函数
模式字符串中的大多数字母和符号都会简单地匹配自身,这样的模式符称为普通字符。普通字符和某些转义字符的匹配范围只有单个字符,这样的模式符称为单字符。
match(pattern, string):从文本串的左端开始匹配模式串的内容,成功则停止匹配,返回一个Match对象,失配则返回None
# 加载匹配函数
from re import match
# 定义获取匹配函数
def get_match(pattern, string):
match_obj = match(pattern, string)
if match_obj:
print(match_obj.group(), match_obj.span())
else:
print('not match!')
get_match('dan', 'dandelion') # dan (0, 3)
get_match('lion', 'dandelion') # not match!
由演示可知,match函数的一般匹配机制为:
将模式串与文本串指针左对齐,从左到右比较相同索引上的字符——若相同,则比较下一个字符,直至模式串没有下一个字符,就返回匹配;若不相同,则匹配失败。
3. 元字符
不匹配自身,而用于匹配非常规内容的一种模式符,称为元字符(metacharacters),包括. ^ $ * + ? { } [ ] \ | ( )
3.1 字符类与 search() 函数
除了空白符,以及转义元字符本身的转义字符,字符类的元字符都可以匹配多种字符,但只匹配符合条件的第一个。
字符类的元字符可分为三种:点式.,集合式[],转义式\.
其中,集合式的使用并不局限于以下几种,任意字符均可放入其中以扩充匹配范围,元字符在其中也会退化为普通字符,特别的,]在集合中需要被\注释或者置于集合首位。
| 模式符 | 匹配范围 |
|---|---|
. |
除换行符外的任一字符 |
[Aab] |
集合内任一字母 |
[a-c] [E-Z] [5-8] |
范围内任一alnum |
[a-zA-Z0-9] |
所有字母和数字 |
[^ex] |
集合范围的补集 |
\d |
数字 [0-9] |
\D |
非数字 [^0-9] |
\s |
空白符 [\t\n\r\f] |
\S |
非空白符 [^\t\n\r\f] |
\w |
alnum [a-zA-Z0-9] |
\W |
not alnum [^a-zA-Z0-9] |
search(pattern, string):在文本串中搜索模式串的内容,成功则停止搜索,返回一个Match对象;找不到则返回None
from re import search
def get_search(pattern, string):
search_obj = search(pattern, string)
if search_obj:
print(search_obj.group(), search_obj.span())
else:
print('not match!')
get_search('.a', "banana") # ba (0, 2)
get_search('a[a-zA-Z0-9]', 'banana') # an (1, 3)
get_search(r'an\w', 'banana') # ana (1, 4)
由演示可知,search函数的一般匹配机制为:
将模式串与文本串指针左对齐,从左到右比较相同索引上的字符——若相同,则比较下一个字符,直至模式串没有下一个字符,就停止并返回匹配;若不相同,则将模式串开头与失配字符的指针对齐,继续比较,若文本串没有下一个字符,则匹配失败。
3.2 重复类与 sub() 函数
重复类的元字符用于指定正则的某部分必须重复匹配一定的次数。这部分正则(ex)可以是单个字符,也可以是()内的多个字符。
重复类的元字符使得模式串的指针暂时不发生移动,直至文本串的指针移动一段距离,或者失配。
| 模式符 | 匹配次数 |
|---|---|
ex* |
任意次(可有可无) |
ex+ |
非零次(至少一次) |
ex? |
一次或零次 |
ex{m, n} |
m <= times <= n |
ex{, n} |
times <= n |
ex{m,} |
times >= m |
ex{m} |
times = m |
sub(pattern, repl, string, count=0):在string中搜索pattern,并将其替换为repl,规定替换count次,默认全部替换。返回替换后的字符串。
from re import sub
print(sub(r'\d+', '999', '123,456,789', count=8))
# 999,999,999
3.3 零宽断言
断言(assertion)是编程中一种用于检查和验证程序逻辑正确性的技术。在Python中,断言语句指的是:对某个条件进行判断,若为假,程序会立即终止并抛出AssertionError异常,还会附上指定的错误信息。
其语法如下:assert condition, message
i = 1
assert i == 0, '123'
Traceback (most recent call last):
File "E:\Pycharm_Python\course\demo.py", line 2, in <module>
assert i == 0, '123'
AssertionError: 123
正则中的断言,指的是用于判断的元字符。它们不匹配字符,不会使指针位置发生移动,相当于不占用任何字符,故称为零宽断言。
3.4 定位类与 findall() 函数
定位类的元字符用于规定正则匹配的子串在文本串中的位置,属于零宽断言,它们只能出现在正则式的两端。
特别的,某些元字符与空白符相同,若要使其发挥作用,可用原字符注释。
| 模式符 | 匹配位置 |
|---|---|
^ex |
文本串或内部行的开头 |
ex& |
文本串或内部行的结尾 |
\Aex |
文本串的开头 |
ex\Z |
文本串的结尾 |
\bex |
单词的开头 |
ex\b |
单词的结尾 |
\Bex |
非单词的开头 |
ex\B |
非单词的结尾 |
还有一类定位断言,用于检查是否存在某个词缀,但不将其包含在匹配结果中。
其中,位于开头的称为后视断言,位于末尾的称为前视断言;存在则匹配的称为肯定型断言,不存在则匹配的称为否定型断言。
否定型断言匹配的正则式必须是定长的。
| 模式符 | 匹配位置 |
|---|---|
ex(?=suffix) |
后缀suffix之前 |
ex(?!suffix) |
无后缀suffix |
(?<=prefix)ex |
前缀prefix之后 |
(?<!prefix)ex |
前缀prefix之后 |
findall(pattern, string):在string中搜索pattern,并返回匹配结果的列表。
from re import findall
s = 'doiing done do doing'
ex = r'\b\w{3}(?!ing\b)'
# 先匹配子串,再分隔词缀,最后判定
print(findall(ex, s)) # ['don', 'doi']
3.5 管道符
管道符|表示匹配多个正则式,相当于正则式的逻辑或运算。其中,匹配优先级为从左到右。
fullmatch(pattern, string):在string中搜索pattern,并返回匹配结果的列表。
from re import findall
s = 'i love u'
ex = 'i|u'
print(findall(ex, s)) # ['i', 'u']
3.6 组合类
组合类的元字符用于对正则进行分组标记,以便于整体修饰和精确获取,分为普通组、命名组和非捕获组。
3.6.1 普通组
用()标识出组合的开始和结尾,匹配组合内的任意正则,并捕获组合的内容。普通组的索引按正则中从左到右出现的顺序依次为1, 2, 3,....
from re import match
pattern = r"(\d+)-(\d)+" # 只有第二组被整体修饰
s = "2024-0901"
v = match(pattern, s)
# 获取正则匹配到的全部内容
print(v.group()) # 2024-0901
# 获取指定组合捕获到的内容
print(v.group(1)) # 2024
# 组内只保留最后一次重复匹配的结果
print(v.group(2)) # 1
# 获取各个组合捕获到的内容元组
print(v.groups()) # ('2024', '1')
3.6.2 命名组
(?P<name>)的行为与普通组一致,区别在于其引用方式不仅可以通过索引获取,还能通过关键字获取。
from re import match
pattern = r"(?P<year>\d+)-(\d)+"
s = "2024-0901"
v = match(pattern, s)
print(v.group(1)) # 2024
print(v.group('year')) # 2024
3.6.3 非捕获组
(?:)仍具有整体修饰的功能,但不再捕获组合中的内容,也不计入正则内的组合索引序列。
3.7 贪婪模式与非贪婪模式
贪婪模式,是指正则进行重复匹配时,匹配引擎将尝试重复尽可能多的次数,若表达式的后续部分不匹配,则匹配引擎将回退并以较少的重复次数再次尝试。默认条件下,正则匹配操作遵循贪婪模式。
同理,非贪婪模式则与之相反。简单的说,具有重复符的正则的匹配结果并不唯一,贪婪模式下,匹配子串会取最长;而非贪婪模式下,则取最短。
该模式针对重复匹配设置,其格式为:在重复符后添加?,即切换为非贪婪模式。
from re import findall
ex1 = r'a.*b'
ex2 = r"a.*?b"
s = "aabcb"
# 贪婪
print(findall(ex1, s)) # ['aabcb']
# 非贪婪
print(findall(ex2, s)) # ['aab']