import paddle
import random
import numpy as np
from paddlenlp.datasets import load_dataset
from functools import partial
from paddlenlp.data import Pad, Tuple
import paddle.nn as nn
import paddle.nn.functional as F
import paddlenlp
import importlib
import utils
import os
paddle.set_device('gpu')
# 新版本的PaddlePaddle应该使用以下方式
gpu_count = paddle.device.cuda.device_count()
print("Number of GPUs:", gpu_count)
def set_seed(seed):
"""sets random seed"""
random.seed(seed)
np.random.seed(seed)
paddle.seed(seed)
train_set_file = "./datasets/baoxian/train_aug.csv"
seed=1000
is_unsupervised=False
dropout=0.1
model_name_or_path='rocketqa-zh-base-query-encoder'
max_seq_length=128
batch_size=16
output_emb_size = 256
margin=0.0
scale=20
epochs=5
dup_rate=0.32
rdrop_coef = 0.1
set_seed(seed)
def read_simcse_text(data_path):
with open(data_path, "r", encoding="utf-8") as f:
for line in f:
data = line.rstrip()#去除右侧换行符
yield {"text_a": data, "text_b": data}
def read_text_pair(data_path, is_test=False):
with open(data_path, "r", encoding="utf-8") as f:
for line in f:
data = line.rstrip().split("\t")
if is_test :
if len(data) != 3:
continue
yield {"text_a": data[0], "text_b": data[1], "label": data[2]}
else:
if len(data) != 2:
continue
yield {"text_a": data[0], "text_b": data[1]}
if is_unsupervised:
train_ds = load_dataset(read_simcse_text, data_path=train_set_file, is_test=False, lazy=False)
else:
train_ds = load_dataset(read_text_pair, data_path=train_set_file, is_test=False, lazy=False)
for i in range(3):
print(train_ds[i])

from paddlenlp.transformers import AutoModel, AutoTokenizer
pretrained_model = AutoModel.from_pretrained(\
model_name_or_path, hidden_dropout_prob=dropout, attention_probs_dropout_prob=dropout)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
def convert_example(example, tokenizer, max_seq_length=512, do_evalute=False):
result = []
for key, text in example.items():
if "label" in key:
# do_evaluate
result += [example["label"]]
else:
# do_train
encoded_inputs = tokenizer(text=text,max_length=max_seq_length,truncation=True)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
result += [input_ids, token_type_ids]
return result
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn=lambda samples,fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id, dtype="int64"), # query_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id, dtype="int64"), # query_segment
Pad(axis=0, pad_val=tokenizer.pad_token_id, dtype="int64"), # title_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id, dtype="int64"), # title_segment
):fn(samples)
def create_dataloader(dataset, mode="train", batch_size=32, batchify_fn=None, trans_fn=None):
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == "train" else False
if mode == "train":
batch_sampler = paddle.io.DistributedBatchSampler(dataset, batch_size=batch_size, shuffle=shuffle)
else:
batch_sampler = paddle.io.BatchSampler(dataset, batch_size=batch_size, shuffle=shuffle)
return paddle.io.DataLoader(\
dataset=dataset, batch_sampler=batch_sampler, collate_fn=batchify_fn, return_list=True)
batch_size=8
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
print(type(train_data_loader),len(train_data_loader))
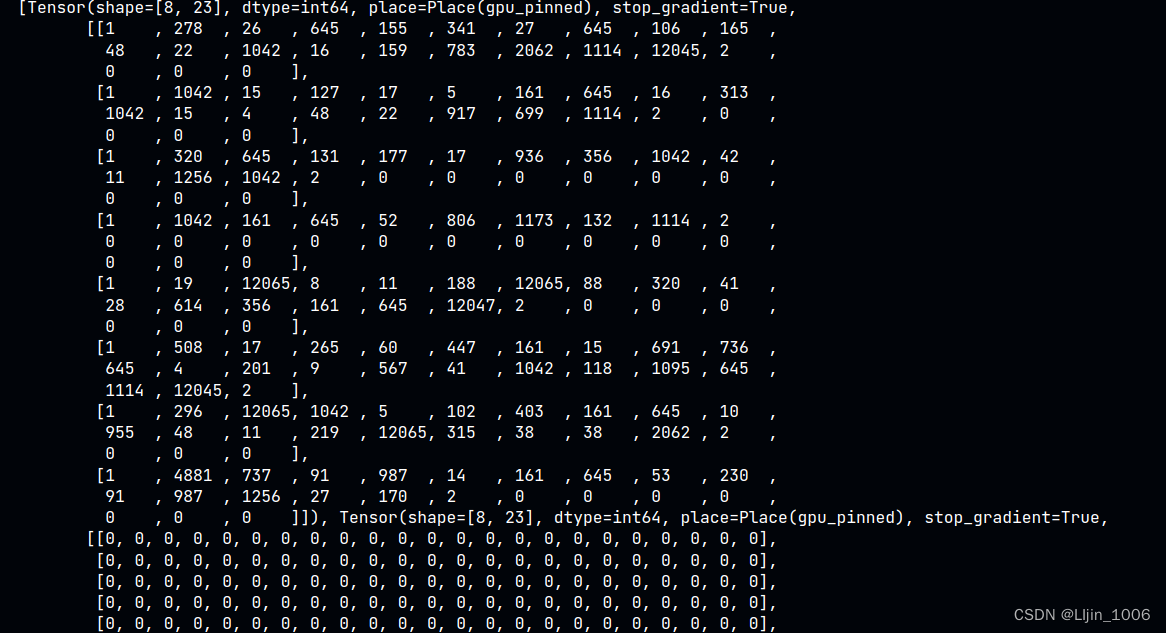
for i in train_data_loader:
print(i)
break
class SimCSE(nn.Layer):
def __init__(self, pretrained_model, dropout=None, margin=0.0, scale=20, output_emb_size=None):
super().__init__()
self.ptm = pretrained_model
self.dropout = nn.Dropout(dropout if dropout else 0.1)
self.output_emb_size = output_emb_size#输出嵌入大小
if output_emb_size > 0:
weight_attr = paddle.ParamAttr(initializer=paddle.nn.initializer.TruncatedNormal(std=0.02))
self.emb_reduce_linear = paddle.nn.Linear(768, output_emb_size, weight_attr=weight_attr)
self.margin = margin
# 使用缩放后的余弦相似度来帮助算法更快地收敛
self.scale = scale
self.classifier = nn.Linear(output_emb_size, 2)
# 对同一个输入样本进行两次带有不同dropout的模型前向传播,得到两组不同的输出分布。
self.rdrop_loss = paddlenlp.losses.RDropLoss()
@paddle.jit.to_static(
input_spec=[
paddle.static.InputSpec(shape=[None, None], dtype="int64"),
paddle.static.InputSpec(shape=[None, None], dtype="int64"),
]
)
def get_pooled_embedding(
self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None, with_pooler=True
):
sequence_output, cls_embedding = self.ptm(input_ids, token_type_ids, position_ids, attention_mask)
if with_pooler is False:#取序列中的开始符作为cls_embedding
cls_embedding = sequence_output[:, 0, :]
if self.output_emb_size > 0:
cls_embedding = self.emb_reduce_linear(cls_embedding)#线性转换
cls_embedding = self.dropout(cls_embedding)
cls_embedding = F.normalize(cls_embedding, p=2, axis=-1)#向量单位化(n,d)
return cls_embedding
def get_semantic_embedding(self, data_loader):
self.eval()
with paddle.no_grad():
for batch_data in data_loader:
input_ids, token_type_ids = batch_data
text_embeddings = self.get_pooled_embedding(input_ids, token_type_ids=token_type_ids)
yield text_embeddings#返回批次数据向量表示
def cosine_sim(
self,
query_input_ids,
title_input_ids,
query_token_type_ids=None,
query_position_ids=None,
query_attention_mask=None,
title_token_type_ids=None,
title_position_ids=None,
title_attention_mask=None,
with_pooler=True,
):
query_cls_embedding = self.get_pooled_embedding(#query向量表示(b,d)
query_input_ids, query_token_type_ids, query_position_ids, query_attention_mask, with_pooler=with_pooler
)
title_cls_embedding = self.get_pooled_embedding(#title向量表示(b,d)
title_input_ids, title_token_type_ids, title_position_ids, title_attention_mask, with_pooler=with_pooler
)
cosine_sim = paddle.sum(query_cls_embedding * title_cls_embedding, axis=-1)#query和title的余弦相似度
return cosine_sim
def forward(
self,
query_input_ids,
title_input_ids,
query_token_type_ids=None,
query_position_ids=None,
query_attention_mask=None,
title_token_type_ids=None,
title_position_ids=None,
title_attention_mask=None,
):
query_cls_embedding = self.get_pooled_embedding(#query向量表示(b,d)
query_input_ids, query_token_type_ids, query_position_ids, query_attention_mask
)
title_cls_embedding = self.get_pooled_embedding(
title_input_ids, title_token_type_ids, title_position_ids, title_attention_mask
)
logits1 = self.classifier(query_cls_embedding)#(b,2)
logits2 = self.classifier(title_cls_embedding)#(b,2)
kl_loss = self.rdrop_loss(logits1, logits2)#kl散度损失
cosine_sim = paddle.matmul(query_cls_embedding, title_cls_embedding, transpose_y=True)#(b,b)
# 列表形式
margin_diag = paddle.full(
shape=[query_cls_embedding.shape[0]], fill_value=self.margin, dtype=paddle.get_default_dtype()
)
cosine_sim = cosine_sim - paddle.diag(margin_diag)#对角矩阵形式
# scale cosine to ease training converge
cosine_sim *= self.scale
labels = paddle.arange(0, query_cls_embedding.shape[0], dtype="int64")
labels = paddle.reshape(labels, shape=[-1, 1])#(b,1)
loss = F.cross_entropy(input=cosine_sim, label=labels)#多元交叉熵损失,内部会one-hot
return loss, kl_loss
margin_diag = paddle.full(
shape=[8], fill_value=0, dtype=paddle.get_default_dtype()
)
paddle.diag(margin_diag)
model = SimCSE(
pretrained_model,
margin=margin,
scale=scale,
output_emb_size=output_emb_size)
num_training_steps = len(train_data_loader) *epochs
lr_scheduler = utils.get_scheduler(num_training_steps,0.1)
optimizer = paddle.optimizer.Adam(lr_scheduler,parameters=model.parameters())
def word_repetition(input_ids, token_type_ids, dup_rate=0.32):#重复词策略
"""Word Repetition strategy."""
input_ids = input_ids.numpy().tolist()
token_type_ids = token_type_ids.numpy().tolist()
batch_size, seq_len = len(input_ids), len(input_ids[0])
repetitied_input_ids = []
repetitied_token_type_ids = []
rep_seq_len = seq_len
for batch_id in range(batch_size):
cur_input_id = input_ids[batch_id]
actual_len = np.count_nonzero(cur_input_id)
dup_word_index = []
# If sequence length is less than 5, skip it
if actual_len > 5:
dup_len = random.randint(a=0, b=max(2, int(dup_rate * actual_len)))
# Skip cls and sep position
dup_word_index = random.sample(list(range(1, actual_len - 1)), k=dup_len)
r_input_id = []
r_token_type_id = []
for idx, word_id in enumerate(cur_input_id):
# Insert duplicate word
if idx in dup_word_index:
r_input_id.append(word_id)
r_token_type_id.append(token_type_ids[batch_id][idx])
r_input_id.append(word_id)
r_token_type_id.append(token_type_ids[batch_id][idx])
after_dup_len = len(r_input_id)
repetitied_input_ids.append(r_input_id)
repetitied_token_type_ids.append(r_token_type_id)
if after_dup_len > rep_seq_len:
rep_seq_len = after_dup_len
# Padding the data to the same length
for batch_id in range(batch_size):
after_dup_len = len(repetitied_input_ids[batch_id])
pad_len = rep_seq_len - after_dup_len
repetitied_input_ids[batch_id] += [0] * pad_len
repetitied_token_type_ids[batch_id] += [0] * pad_len
return paddle.to_tensor(repetitied_input_ids, dtype="int64"), paddle.to_tensor(
repetitied_token_type_ids, dtype="int64"
)
def train(model,dataloader,optimizer,scheduler,global_step):
model.train()
total_loss=0.
for step, batch in enumerate(dataloader, start=1):
query_input_ids, query_token_type_ids, title_input_ids,title_token_type_ids = batch
if random.random() < 0.5:
query_input_ids, query_token_type_ids = word_repetition(\
query_input_ids, query_token_type_ids,dup_rate)
title_input_ids, title_token_type_ids = word_repetition(\
title_input_ids,title_token_type_ids,dup_rate)
loss, kl_loss = model(
query_input_ids=query_input_ids,
title_input_ids=title_input_ids,
query_token_type_ids=query_token_type_ids,
title_token_type_ids=title_token_type_ids)
loss = loss + kl_loss *rdrop_coef
loss.backward()#反向传播
optimizer.step()#梯度更新
optimizer.clear_grad()#梯度归0
scheduler.step()#更新学习率
global_step += 1
total_loss += loss.item()
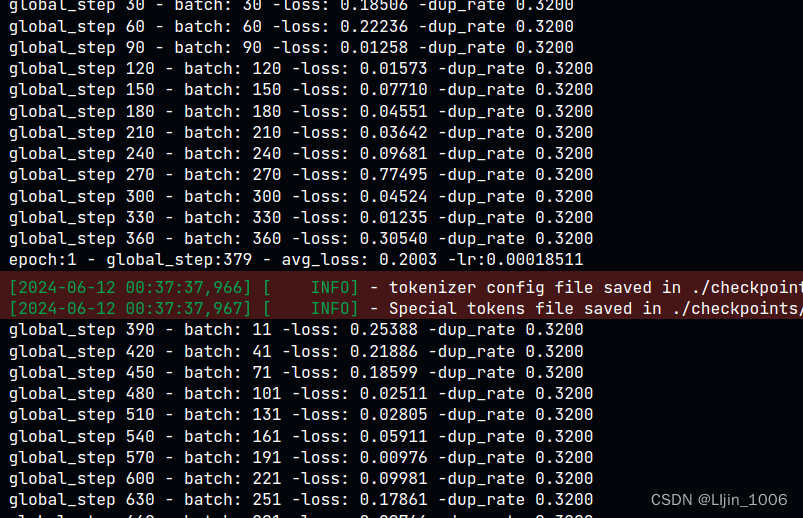
if global_step % 30 == 0 and global_step!=0:
print("global_step %d - batch: %d -loss: %.5f -dup_rate %.4f"
%(global_step,step,loss.item(),dup_rate))
avg_loss=total_loss/len(dataloader)
return avg_loss,global_step
def train_epochs(epochs,save_path):
global_step = 0#全局步
best_loss=float('inf')#最好的损失
for epoch in range(1,epochs+1):
avg_loss,global_step = train(model,train_data_loader,optimizer,\
lr_scheduler,global_step)
print("epoch:%d - global_step:%d - avg_loss: %.4f -best_loss:%.4f -lr:%.8f" \
% (epoch,global_step,avg_loss,best_loss,optimizer.get_lr()))
if avg_loss < best_loss:
paddle.save(model.state_dict(),\
save_path+'bqqa_best_1.pdparams')
tokenizer.save_pretrained(save_path)
best_loss=avg_loss
save_path='./checkpoints/bqqa/'
if not os.path.exists(save_path):
os.makedirs(save_path)
train_epochs(epochs,save_path)