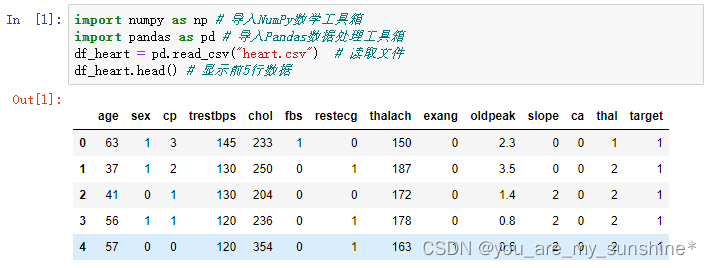
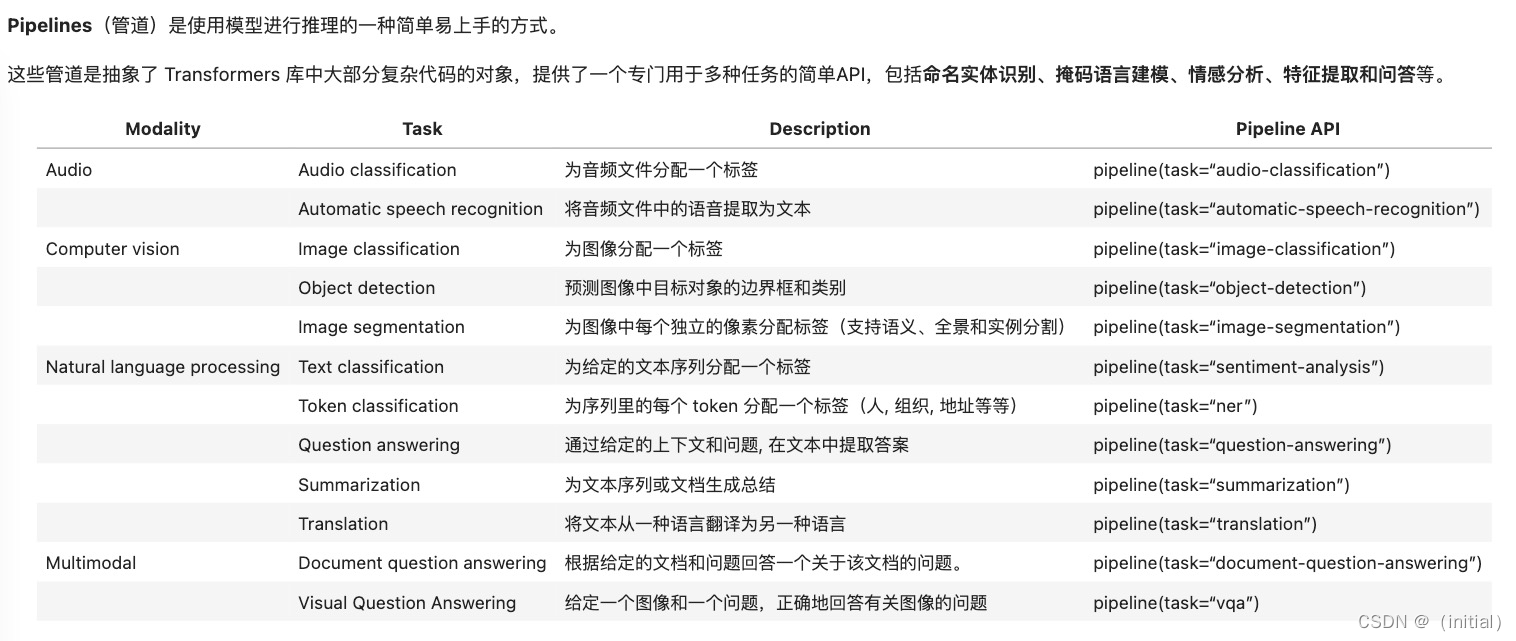
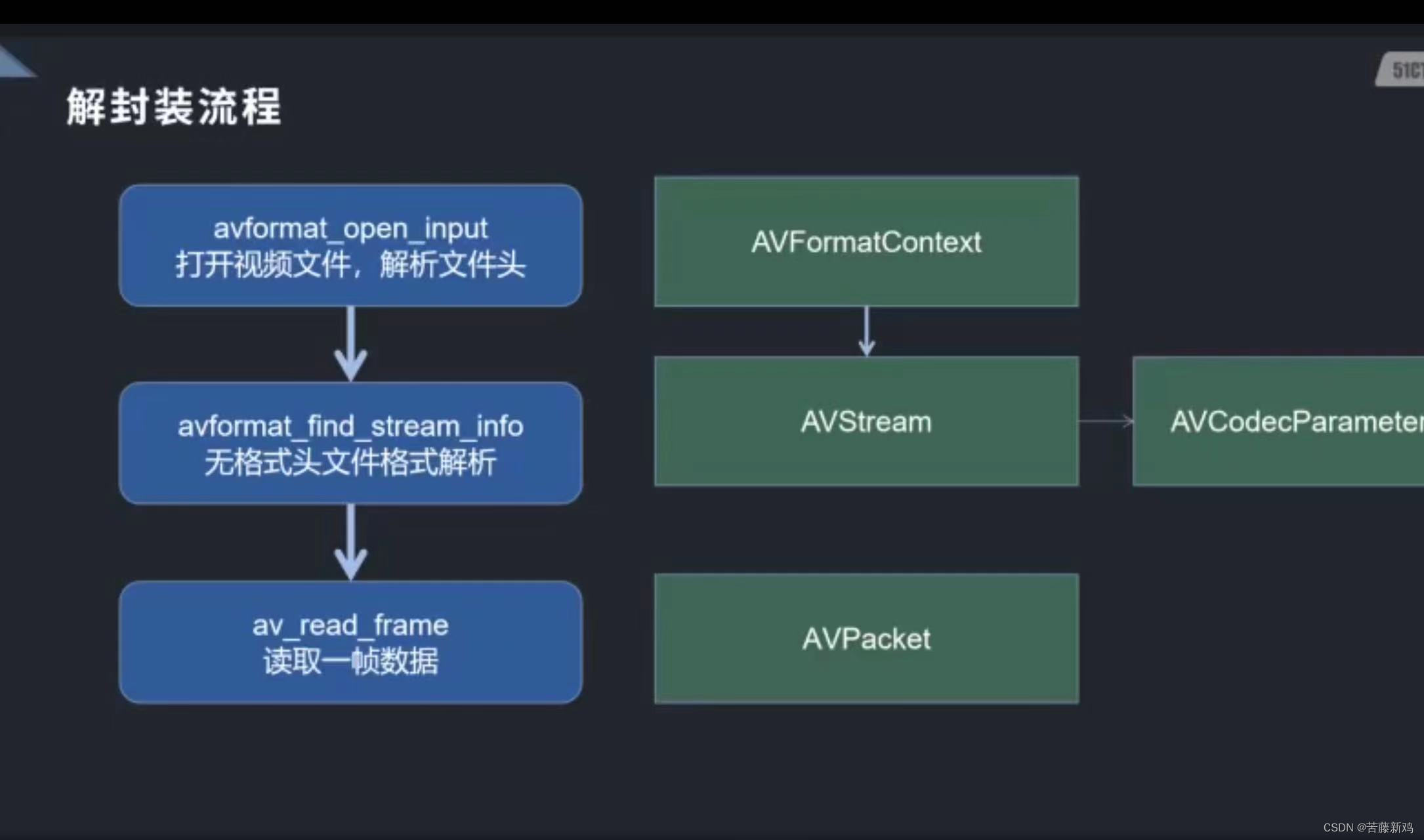
在机器学习的过程中,数据的划分是至关重要的步骤。为了评估模型的泛化性能,我们通常会将数据集划分为训练集、测试集和验证集。这三个集合各有不同的作用,下面我们将逐一介绍。
一、训练集
训练集是用于训练模型的数据集。通过使用训练集对模型进行训练,我们可以得到一系列的模型参数,如线性回归中的权重和偏差,神经网络中的权重和偏置项等。在训练过程中,我们通过优化算法不断调整模型参数,使得模型能够更好地拟合训练数据。训练集的主要目标是用于找出最佳的模型参数。
二、验证集
验证集主要用于模型选择和调整。验证集可以用来评估模型的性能,如准确率、损失函数等,以便我们能够选择最佳的模型参数和模型结构。同时,我们也可以使用验证集来调整模型的复杂度,防止过拟合或欠拟合现象的发生。在神经网络的训练过程中,我们通常会使用验证集来选择最佳的隐藏层数和节点数。
三、测试集
测试集主要用于评估模型的泛化性能。当我们使用训练集和验证集对模型进行训练和调整后,我们就可以使用测试集来评估模型的性能了。测试集的数据是未知的,因此测试结果能够更准确地反映模型的泛化能力。在机器学习中,我们通常使用测试集来评估模型的最终性能,以便我们能够对模型进行比较和选择。
在实际应用中,如何划分训练集、验证集和测试集并没有固定的比例,通常需要根据具体的问题和数据量来进行调整。常用的比例有70%:15%:15%或60%:20%:20%。另外,也可以采用交叉验证(Cross-validation)的方法来进行模型选择和参数调整。
四、模型选择
模型选择是机器学习中一个重要的步骤,它涉及到选择最佳的模型和模型参数。在模型选择的过程中,我们通常会使用验证集来进行比较和选择。我们可以通过调整不同的模型参数和结构,在验证集上评估模型的性能,然后选择最佳的模型作为最终的模型。
在实际应用中,除了模型的性能外,我们还需要考虑其他因素,如模型的复杂度、可解释性、计算成本等。在某些情况下,我们可能需要对模型进行折衷选择,以平衡各种因素的需求。
总结来说,训练集、验证集和测试集在机器学习中起着至关重要的作用。通过合理的划分和使用它们,我们可以更好地评估模型的性能和泛化能力,并进行有效的模型选择。在实际应用中,需要根据具体的问题和数据量来调整数据集的划分比例和方法,以便获得最佳的模型性能