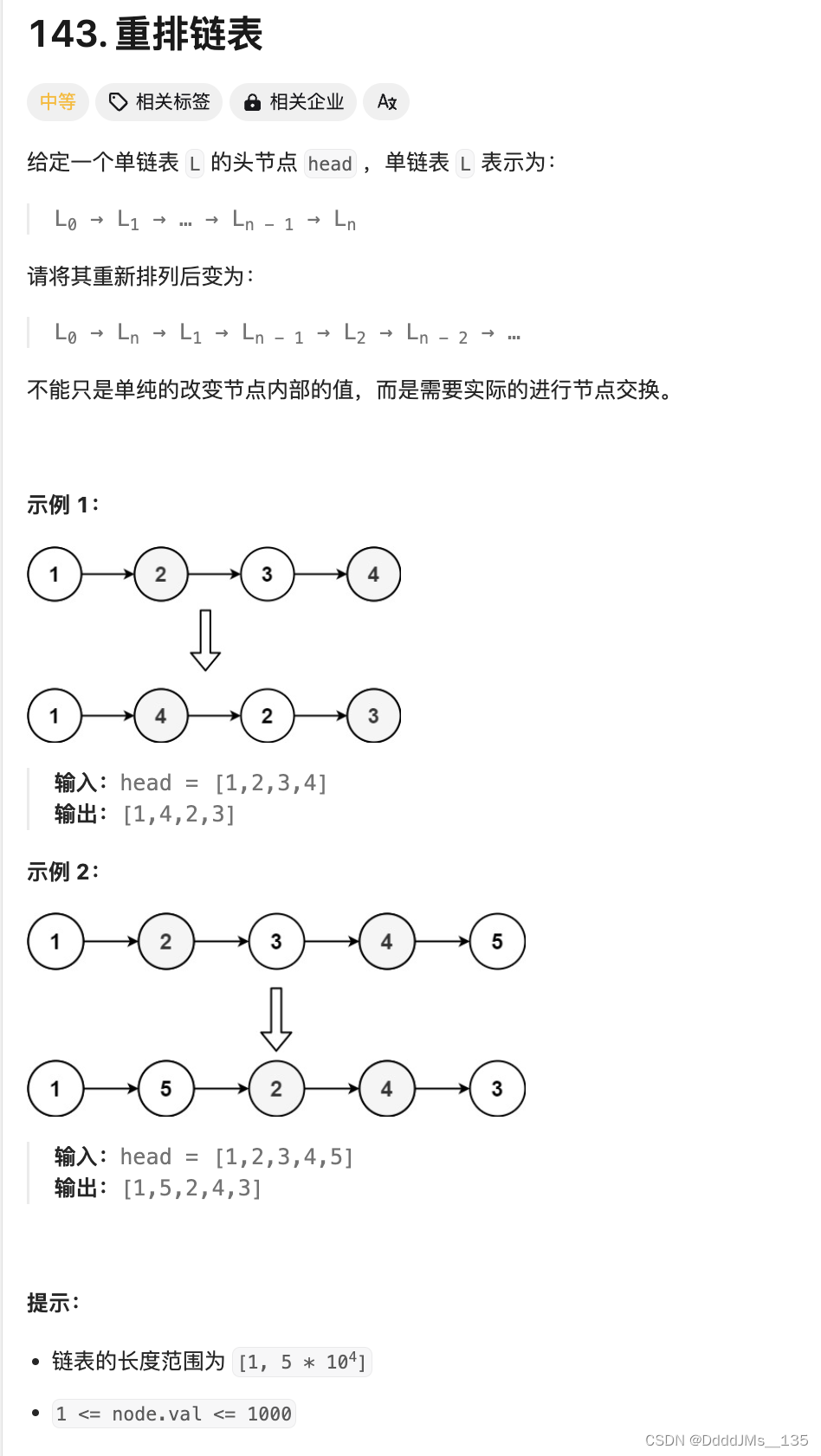
部署Qwen时尝试使用 vLLM。易于使用且具有最先进的服务吞吐量、高效的注意力键值内存管理(通过PagedAttention实现)、连续批处理输入请求、优化的CUDA内核等功能。
参考链接https://qwen.readthedocs.io/zh-cn/latest/deployment/vllm.html
1 vLLM离线推理代码
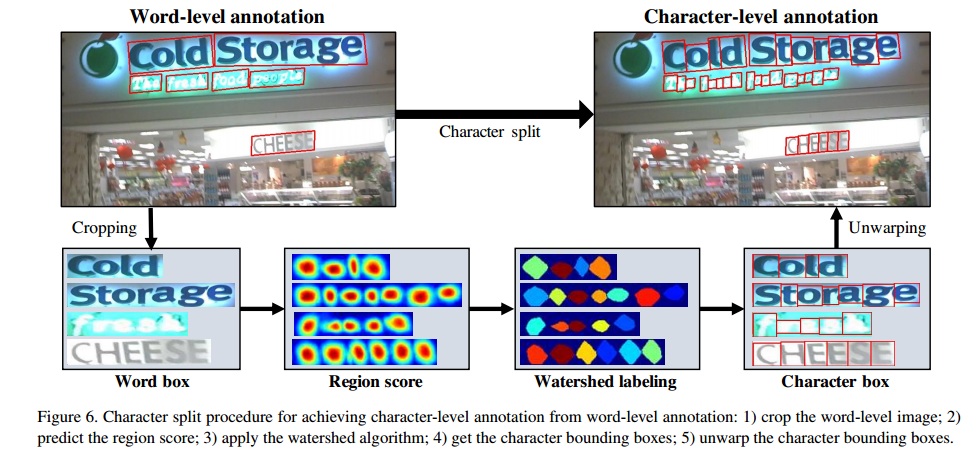
Qwen2代码支持的模型都被vLLM所支持。 vLLM最简单的使用方式是通过以下演示进行离线批量推理。
这段代码的工作流程如下 ,展示了如何使用 vLLM 库和 Hugging Face 的工具来执行文本生成任务,同时应用量化技术(如 GPTQ 或 AWQ)来优化模型性能。
- 加载分词器:使用与预训练模型匹配的分词器将输入文本转换为模型可以处理的格式。
- 设置解码参数:配置生成过程中的一些超参数,以控制输出文本的质量和特性。
- 初始化LLM:加载指定的预训练大型语言模型。
- 准备输入:创建并格式化输入文本,表示模型角色和用户输入。
- 生成文本:根据格式化的输入和解码参数生成响应文本。
- 打印结果:显示生成的文本。
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
# Pass the default decoding hyperparameters of Qwen2-7B-Instruct
# max_tokens is for the maximum length for generation.
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)
# Input the model name or path. Can be GPTQ or AWQ models.
llm = LLM(model="Qwen/Qwen2-7B-Instruct")
# Prepare your prompts
prompt = "Tell me something about large language models."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# generate outputs
outputs = llm.generate([text], sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
2 代码解释
这段代码展示了如何使用 vLLM 和 transformers 库来生成基于给定提示的文本。具体地,代码使用了一个名为 Qwen/Qwen2-7B-Instruct 的预训练大型语言模型(LLM),并应用了一些高级的解码策略(如温度、top-p、重复惩罚等)来控制生成文本的特性。
下面是对代码的详细解释:
2.1 导入必要的库
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
transformers库是 Hugging Face 的一个工具,用于处理和使用各种预训练的自然语言处理(NLP)模型。vLLM是一个专门用于高效推理的库,可以与不同类型的量化模型(如 GPTQ 或 AWQ)协作使用。
2.2 初始化分词器
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
AutoTokenizer:从 Hugging Face 模型库中加载与模型Qwen/Qwen2-7B-Instruct匹配的分词器。这个分词器将用于处理输入文本,使其转换为模型可处理的格式。
2.3 配置解码参数
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)
用于配置生成文本的解码参数。
temperature:控制生成的随机性。较高的值(>1.0)会使输出更加多样化,较低的值(<1.0)会使输出更加确定性。top_p:核采样(Top-p)参数。0.8 表示保留累积概率为 80% 的最高概率词。top_p是核采样(nucleus sampling)的参数,用来控制从概率分布中选择下一个token的范围。top_p=0.8表示在选择下一个单词时,模型将仅从那些累积概率总和达到80%的候选单词中选择。具体来说,它会按照单词的概率排序,并从这些单词中随机选择,直到选出的单词的累积概率达到0.8。这可以使生成的文本更加多样化,而不会完全依赖最高概率的单词。相比于传统的贪婪搜索,这种方法通常会生成更加自然且连贯的文本,但也能保留一定的多样性。repetition_penalty:惩罚重复的词。>1 的值表示更高的惩罚,使生成的文本不那么重复。repetition_penalty=1.05表示在生成过程中,如果某个单词已经被生成过,其再次出现的可能性会被降低。具体来说,它通过乘以一个大于1的系数(1.05),减少这些单词的概率,避免生成重复内容。通过惩罚重复的单词,可以生成更丰富和多样的文本,避免出现重复的句子或片段。max_tokens:生成的最大token数量。max_tokens=512表示模型在生成过程中最多生成512个token。Token是文本的最小单元,它可以是单词、字符或子词,取决于分词器的定义。限制生成文本的长度,以避免生成过长的文本。如果达到这个长度,生成过程会自动停止。
2.4 初始化LLM模型
llm = LLM(model="Qwen/Qwen2-7B-Instruct")
LLM:初始化vLLM的大型语言模型(LLM),指定模型Qwen/Qwen2-7B-Instruct。
2.5 准备提示
prompt = "Tell me something about large language models."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
- 准备提示:创建一个提示,告诉模型用户希望生成什么内容。
- 消息列表:包含一个系统消息(设定模型的行为)和一个用户消息(实际的问题或请求)。
apply_chat_template:将这些消息应用到一个聊天模板中,格式化成模型需要的输入文本。apply_chat_template是一个方法,用于将输入消息(messages)应用到一个标准的聊天模板中,以便模型可以理解这些消息的结构。将多个消息按照预定义的格式组织起来,这些消息包括系统消息和用户消息,通常会标明每条消息的角色(system、user)和内容(content)。格式化后的文本将更好地与模型的预训练结构对齐,提升生成的准确性和自然性。例如,对于以下输入消息:
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me something about large language models."}
]
apply_chat_template可能将它们格式化为类似于:
system: You are a helpful assistant.
user: Tell me something about large language models.
assistant:
这使得模型能识别对话的上下文并生成更相关的回应。
tokenize=False:表示不立即分词,而是保持文本格式;指定是否立即对文本进行分词处理。保持文本的原始格式,而不立即将其转换为模型所需的token ID。它允许返回一个未分词的纯文本字符串。保持文本为字符串格式,可以在进一步处理或调试时更方便地查看和操作。add_generation_prompt=True:参数指定是否在生成的文本末尾添加一个生成提示符。在格式化文本的末尾添加一个提示符(通常是模型用来开始生成内容的标记)。模型会识别到提示符,并知道这是开始生成新内容的位置,从而更好地生成文本。例如,add_generation_prompt=True 可能会在输入文本的末尾添加一个类似于“assistant: ”的标记,告诉模型它应该在这里开始生成新的回复。
2.6 生成输出
outputs = llm.generate([text], sampling_params)
generate方法:使用准备好的文本和解码参数生成模型的输出。
2.7 打印输出
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
- 遍历输出:迭代模型的输出,打印每个输出的提示(prompt)和生成的文本(generated text)。
output.prompt:原始提示文本。output.outputs[0].text:生成的文本内容。
3 vLLM 实现原理
vLLM 是一种高效的大规模语言模型推理引擎,它优化了语言模型的推理速度和资源使用。理解 vLLM 的实现原理包括以下几个关键方面:
3.1 高效内存管理
vLLM 实现了高效的内存管理策略,最大化了 GPU 内存的利用率:
分片内存分配:vLLM 使用一种分片内存管理器,将模型的内存分成多个分片(chunks),每个分片负责管理一部分内存。这种方式允许动态调整内存分配,以适应不同大小的输入和批量(batch)处理需求。
缓存优化:vLLM 实现了缓存机制,预分配并维护模型推理过程中所需的缓存(如 past_key_values)。这种方法减少了每次推理时的内存分配和管理开销。
3.2 高效并行化和流水线处理
vLLM 通过高效并行化和流水线处理技术优化了推理速度:
分布式计算:vLLM 支持多 GPU 的分布式计算,将模型和计算任务分布在多个 GPU 上,以实现并行处理。这种方式减少了单个 GPU 的负载,同时提升了整体推理速度。
流水线处理:vLLM 实现了推理过程的流水线化,将推理过程分成多个阶段,每个阶段在不同的 GPU 上运行,以减少 GPU 的空闲时间和数据传输延迟。这种方式使得不同的 GPU 可以同时处理不同的推理任务,提高了吞吐量。
3.3 优化的解码算法
vLLM 优化了解码算法,以提高生成文本的效率和质量:
并行解码:vLLM 实现了并行解码策略,可以同时处理多个候选项。这减少了生成每个 token 所需的时间,提升了生成速度。
解码策略支持:vLLM 支持多种高级解码策略,如温度采样(temperature sampling)、核采样(top-p sampling)、束搜索(beam search)等。这些策略允许调整生成的多样性和质量,以满足不同的应用需求。
3.4 量化技术
vLLM 使用量化技术来减少模型大小和内存使用,从而加速推理:
权重量化:vLLM 支持将模型的权重量化为更小的数据类型(如 INT4、INT8),以减少内存占用和传输带宽。这使得模型能够在内存受限的环境中高效运行。
动态量化:vLLM 实现了动态量化机制,在推理过程中实时调整量化参数,以在保持精度的同时最大化性能。
3.5 融合模块(Fused Modules)
vLLM 引入了融合模块,通过将多个操作融合为单个高效的操作来减少计算开销:
层融合:将模型的多个层(如前馈层和注意力层)合并为一个操作。这减少了各层之间的数据传输开销,提高了计算效率。
操作融合:将多个矩阵操作和激活函数合并为单个高效的计算操作。这种方式减少了操作之间的开销,使得推理过程更加高效。
3.6 定制硬件支持
vLLM 优化了对特定硬件的支持,以进一步提升性能:
Flash Attention:vLLM 实现了 Flash Attention 算法,这是一种加速注意力计算的方法,能够在不牺牲精度的情况下显著提升速度。
GPU 加速:vLLM 针对现代 GPU(如 NVIDIA 的 Ampere 和 Hopper 架构)进行了优化,充分利用 GPU 的计算能力和内存带宽。
3.7 模型并行和数据并行
vLLM 实现了模型并行和数据并行技术,以处理大规模模型和大批量数据:
模型并行:将模型分割到多个 GPU 上,每个 GPU 处理模型的一部分。这种方式适合超大规模的模型,能够将模型的计算分布到多个 GPU 以适应内存限制。
数据并行:在多个 GPU 上同时处理不同的输入数据,这样可以利用多 GPU 的计算能力加速推理过程。
3.8 定制缓存管理
vLLM 实现了高效的缓存管理,以优化推理过程中的状态维护:
自定义缓存:vLLM 预分配并管理推理过程中使用的缓存空间,如 past_key_values。通过预分配缓存,可以减少推理过程中因动态内存分配带来的开销。
缓存复用:在推理过程中复用缓存数据,以减少内存的反复分配和释放,提高推理效率。
3.9 自动化和灵活的配置
vLLM 提供了自动化和灵活的配置选项,允许用户根据需求调整推理过程的参数:
自动化配置:vLLM 可以根据硬件和任务需求自动配置最佳的推理参数,如批量大小、序列长度等。
灵活的参数调整:用户可以通过简单的接口调整推理参数,以适应不同的应用场景和性能要求。
![[<span style='color:red;'>大</span><span style='color:red;'>模型</span>]<span style='color:red;'>Qwen</span>-Audio-chat WebDemo <span style='color:red;'>部署</span>](https://img-blog.csdnimg.cn/direct/e2935baa06674badacba9928a372ab80.png#pic_center)

![[<span style='color:red;'>大</span><span style='color:red;'>模型</span>]<span style='color:red;'>Qwen</span>1.5-7B-Chat-GPTQ-Int4 <span style='color:red;'>部署</span>环境](https://img-blog.csdnimg.cn/direct/a00a5637ff5e459a9e274da85c6afac7.png#pic_center)