大型语言模型(LLMs)以其卓越的理解和生成类人文本的能力,从根本上增强了我们的日常生活,并改变了我们的工作环境。当今最先进的LLMs,如GPT4和Claude-3,托管在数据中心,配备了最先进的GPU(例如,NVIDIA H100)。这些GPU提供了广泛的高带宽内存,并提供了达到数千万亿次的计算能力。同时,出现了一个趋势,即将LLMs部署在无处不在的智能手机上,将它们转变为智能个人助理。这种转变旨在充分利用丰富的个人数据,同时通过避免将私有数据传输到云服务来维护隐私。
然而,尽管智能手机广泛使用,它们在满足LLM推断的复杂需求方面存在困难,因为它们的处理能力和内存大小受到限制。为了解决这些问题,研究人员探索了两种有希望的方法,用于在资源受限的条件下提供LLM推断。鉴于智能手机的有限内存容量,一种策略是部署缩减版的LLMs。例如,Google的Gemini Nano 3.25B,使用不到2GB的内存,通过减少智能能力以适应内存限制,代表了一种折中。这是由于更大的模型具有增强的智能,这种现象被称为“规模定律”。或者,一些技术旨在降低LLM权重在推断期间的计算和存储需求。PowerInfer通过将热激活神经元分配给GPU,冷神经元分配给CPU,在个人计算机(PC)上实现了11倍的推断速度提升。另一种方法,LLM in a Flash,通过使用基于闪存的NVMe存储来存储大型模型权重,来缓解内存限制。然而,这些解决方案在智能手机上失败了,因为智能手机具有较弱的、异构的硬件和存储设备,带宽较低,并且由于单个命令队列而不支持并发访问。这使得I/O活动成为移动设备上LLM推断的常见瓶颈。
PowerInfer-2,这是第一个在智能手机上执行LLM高速推断的框架,可以容纳高达470亿参数的模型,这些模型超出了设备的内存容量。PowerInfer-2是PowerInfer项目的后续工作,专门为智能手机设计。
1 背景
1.1 LLM 推理过程与关键指标
大语言模型(LLM)的推理过程主要分为两个阶段:
- 预填充阶段 : 处理用户输入的所有 token,生成第一个 token。
- 解码阶段 (Decoding): 逐个生成后续 token,直到输出序列完整或遇到结束 token (EOS)。
这两个阶段具有不同的计算模式:
- 预填充阶段: 处理所有 token,计算量较大。
- 解码阶段: 每次迭代只处理一个 token,计算量相对较小,但具有显著的稀疏性。
为了优化性能,LLM 推理系统需要针对这两个阶段分别设计计算策略。
1.2 可预测的稀疏激活
主流 LLM,如 GPT-4 和 Llama-2,通常采用解码器-only 的 Transformer 架构,其中 Feed-Forward Network (FFN) 块占据了大部分权重。FFN 块中的激活函数(如 ReLU)会导致大量的稀疏激活,即大部分神经元处于非激活状态。
幸运的是,FFN 块中神经元的激活情况可以在计算之前进行预测。例如,PowerInfer 和 DejaVu 等框架使用小型 MLP 网络来预测 FFN 块中神经元的动态激活情况。通过这些预测器,可以显著减少 FFN 中的神经元计算数量,从而加速推理过程。
1.3 智能手机存储分析
智能手机通常缺乏足够的 DRAM 内存来存储整个 LLM,因此部分模型权重需要存储在外部存储设备中,例如 Snapdragon 8gen3 中的 UFS 4.0。
为了设计高效的 LLM 推理系统,需要考虑智能手机存储介质的性能特征,包括:
- 读取吞吐量与块大小: 读取带宽随着读取块大小的增加而增加。
- 随机读取与数据范围: 随机读取的性能受随机读取范围的影响,范围越小,带宽越高。
- 读取吞吐量与 CPU 核心: CPU 核心的频率越高,读取带宽越高。
- 读取吞吐量与核心数量: 与 NVMe 不同,UFS 存储只有一个命令队列,不支持并发访问,因此使用多个核心进行随机读取并不会提高 I/O 带宽。
2 PowerInfer-2
PowerInfer-2 是一个专为智能手机设计的高性能 LLM 推理框架,旨在解决智能手机计算能力有限和内存容量不足的挑战。它通过将传统的矩阵计算分解为细粒度的神经元集群计算,并利用智能手机中异构的计算、内存和 I/O 资源,实现了低延迟和高效率的 LLM 推理。
官网:https://powerinfer.ai/v2/
2.1 设计目标
- 低推断延迟:最小化预填充阶段(TTFT)和解码阶段(TBT)的推断延迟。
- 低内存占用:在推断期间减少内存使用,使得即使模型大小超过设备的内存限制,也能实现低延迟的LLM推断。
- 灵活性:确保设计能够无缝适应具有不同计算、内存和存储容量的智能手机。
2.2 核心概念
PowerInfer-2 引入了一个多态神经元引擎,该引擎动态地将神经元组合成神经元簇,利用LLM推断阶段和异构XPU的不同计算特性。
- 神经元簇的大小由计算单元的计算能力决定。
- 通过这种抽象,PowerInfer-2能够充分利用不同计算能力的XPUs。
2.3 架构
PowerInfer-2的架构分为在线推理和离线规划两部分,协同工作以实现高效的推理。

2.3.1 在线推理
PowerInfer-2 的在线推理流程包括以下四个协同组件:
- 多态神经元引擎: 根据推理阶段和硬件特性,动态地将神经元组合成神经元集群,并选择合适的计算单元进行计算。
- 内存神经元缓存: 存储频繁访问的神经元权重,以减少 I/O 操作的开销。
- 灵活的神经元加载: 根据模型的量化方法和 UFS I/O 特性,采用不同的加载策略,例如随机读取和顺序读取,以优化 I/O 读取吞吐量。
- 神经元集群级流水线: 将神经元集群的计算和 I/O 操作重叠执行,以最小化 I/O 等待时间。
2.3.2 离线规划
PowerInfer-2 的离线规划流程负责生成执行计划,指导在线推理过程。执行计划包括以下配置信息:
- 计算配置: 确定 CPU 和 NPU 在不同阶段或层的使用比例。
- 内存配置: 根据用户设定的推理速度,计算最优的神经元缓存大小。
- I/O 配置: 根据模型的稀疏性和冷热神经元的分布,确定灵活的神经元加载策略。
2.4 关键技术
2.4.1 多态神经元引擎
多态神经元引擎是 PowerInfer-2 的核心组件,它根据 LLM 推理的不同阶段和硬件特性,动态地将神经元组合成神经元集群,并选择合适的计算单元进行计算。
- 基于 NPU 的预填充: 在预填充阶段,所有用户输入的 token 都会并发处理,因此 PowerInfer-2 使用包含所有神经元的大的神经元集群,并利用 NPU 在处理大型矩阵乘法方面的优势来加速计算。
- 基于 CPU 的解码: 在解码阶段,每次迭代只处理一个 token,因此 PowerInfer-2 使用小的神经元集群,并利用 CPU 核心的灵活性来处理稀疏计算任务。
2.4.2 内存神经元缓存
内存神经元缓存用于存储频繁访问的神经元权重,以减少 I/O 操作的开销,具有以下特点:
- 分段设计: 根据不同 LLM 权重类型的特点,将缓存分为多个区域,每个区域采用不同的缓存策略,例如 LRU 替换策略。
- 神经元粒度: 缓存操作在神经元粒度上进行,可以更有效地利用缓存空间并提高缓存命中率。
2.4.3 灵活的神经元加载
PowerInfer-2 根据模型的量化方法和 UFS I/O 特性,采用不同的加载策略,以优化 I/O 读取吞吐量:
- 无量化模型: 使用大粒度的随机读取,例如一次性读取一个神经元的所有权重数据。
- 4 位量化模型: 使用小粒度的随机读取,并根据预测结果动态决定是否进行第二次读取,以避免不必要的 I/O 操作。
2.4.4 神经元集群级流水线
神经元集群级流水线技术将神经元集群的计算和 I/O 操作重叠执行,以最小化 I/O 等待时间:
- 将矩阵计算分解为神经元集群: PowerInfer-2 将矩阵计算分解为多个神经元集群的计算,每个神经元集群可以独立执行。
- 并发执行计算和 I/O 操作: 当一个神经元集群的计算完成后,立即开始处理下一个矩阵中内存中的神经元集群的计算,从而隐藏 I/O 等待时间。
2.4.5 执行计划生成
PowerInfer-2 的离线规划流程会根据模型和硬件特性生成执行计划,指导在线推理过程:
- 硬件特性分析: 使用离线分析器评估 CPU、I/O 和内存的性能。
- 模型特性分析: 使用离线分析器评估模型的稀疏性、冷热神经元的分布和缓存特性。
- 成本模型: 使用成本模型优化执行计划,目标是最大化解码速度,同时满足用户指定的约束条件。
3 评估
3.1 实验设置
3.1.1 硬件选择
- OnePlus 12 和 OnePlus Ace 2: 选择了高端和中端手机进行评估,代表不同性能水平的智能手机。
- Snapdragon 8 Gen 3 和 Snapdragon 8+ Gen 1: 不同的 SoC,体现了不同计算能力的差异。
- UFS 4.0 和 UFS 3.1: 不同的存储介质,评估其对 I/O 性能的影响。
3.1.2 模型选择
选择了四种不同架构和模型大小的语言模型,分别是:
- 稀疏Llama-7B/13B
- TurboSparse-Mixtral-47B
- TurboSparse-Mistral-7B
3.1.3. 基线
PowerInfer-2与三种最先进的LLM推断框架进行了比较:llama.cpp、LLM in a Flash和MLC-LLM。Llama.cpp是目前支持将部分模型权重卸载到闪存存储(通过mmap)的最快大型模型推断框架,也是许多其他框架的后端,如Ollama。LLM in a Flash是为PC环境设计的,不是开源的。对于PowerInfer-2和LLMFlash,部署了我们的稀疏化模型,而其他基线系统则使用了原始模型进行速度比较。
3.1.4 工作负载
评估的工作负载是从实际LLM任务中选择的,包括多轮对话, 代码生成, 数学问题求解和角色扮演:,评估 PowerInfer-2 在不同任务下的性能表现。
3.1.5 评估指标
- 生成速度 (tokens/s): 作为主要评估指标,直观地反映系统性能。
- 预填充速度和解码速度: 分别评估预填充和解码阶段的性能。
- 解码速度分布: 分析不同任务和 token 级别的解码速度分布,评估系统的鲁棒性。
3.2 评估结果
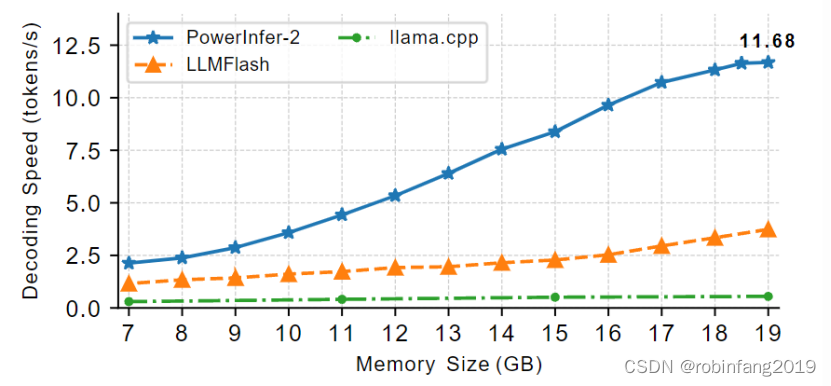
- 性能提升: PowerInfer-2 在多种模型和硬件上实现了显著的性能提升,最高可达 29.2 倍。
- 内存节省: 在内存充足的情况下,PowerInfer-2 能够节省约 40% 的内存使用,同时保持高性能。
- 鲁棒性: PowerInfer-2 在不同任务下表现出良好的鲁棒性,解码速度稳定。
3.3 关键发现
- NPU 优势: 在预填充阶段,NPU 的计算能力显著优于 CPU 和 GPU。
- I/O 优化: PowerInfer-2 通过灵活的神经元加载和神经元级流水线机制,有效减少了 I/O 延迟。
- 缓存策略: 分段神经元缓存设计有效地提高了缓存命中率,降低了 I/O 负载。
- 内存容量影响: 解码速度随内存容量线性增长,表明 I/O 是主要瓶颈。
3.4 未来工作
- 支持更多模型和硬件: 将 PowerInfer-2 扩展到更多 LLM 模型和智能手机硬件。
- 模型压缩: 探索模型压缩技术,进一步降低模型大小和内存占用。
- 端到端优化: 将 PowerInfer-2 与其他优化技术相结合,实现端到端的 LLM 推理优化。