实战:利用Spark SQL实现词频统计
目标
- 使用Apache Spark的Spark SQL模块,实现一个词频统计程序。
环境准备
本地文件准备
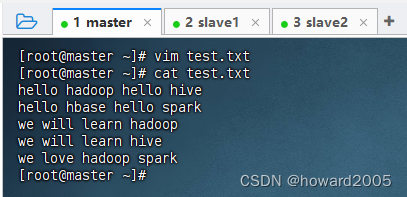
- 在本地
/home目录下创建words.txt文件。
- 在本地
HDFS文件准备
- 创建HDFS目录
/wordcount/input。 - 将
words.txt文件上传到HDFS的/wordcount/input目录。
- 创建HDFS目录
交互式实现
方法一
- 读取文本文件并生成数据集。
- 扁平化映射,将文本拆分为单词。
- 将数据集转换为数据帧,并重命名列。
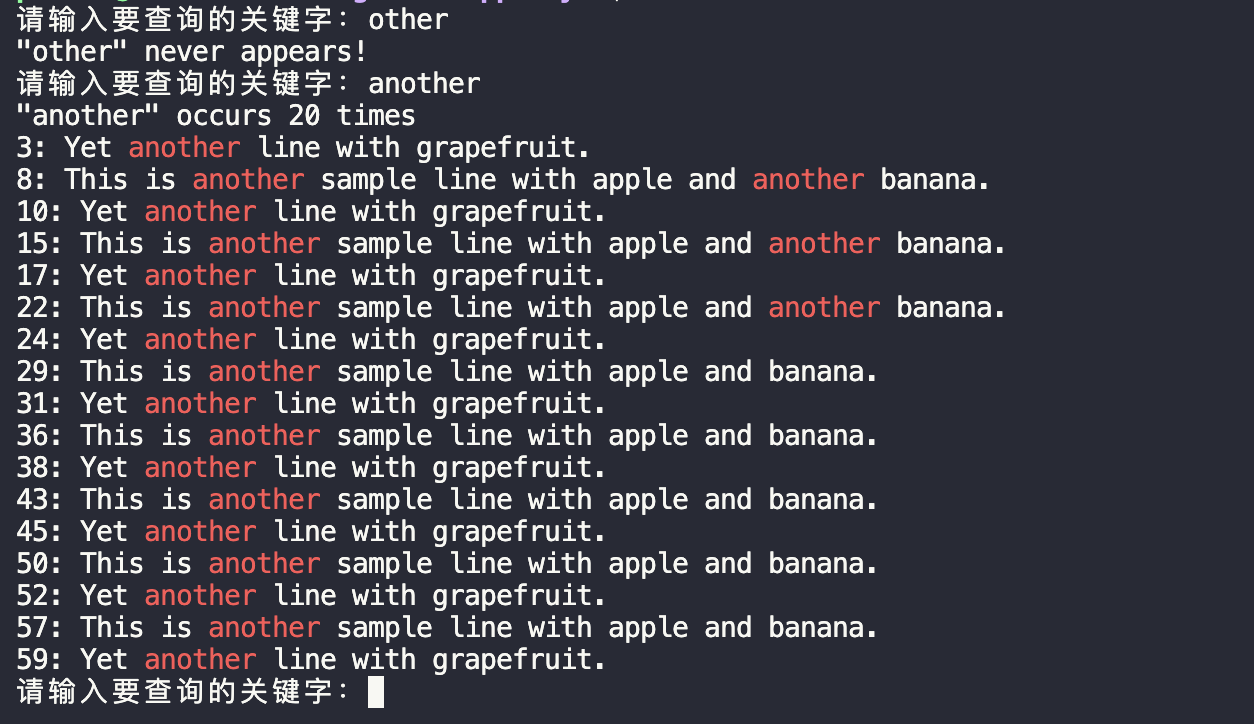
- 创建临时视图,使用SQL查询进行词频统计。
- 将统计结果保存到HDFS,并查看结果。
方法二
- 直接读取文本文件生成数据帧。
- 创建基于数据帧的临时视图。
- 使用SQL查询和
explode函数进行词频统计。 - 显示统计结果。
Spark项目实现
创建Maven项目
- 创建Jakarta EE项目,修改源程序目录为Scala。
添加依赖
- 删除原有依赖,添加Spark Core和Spark SQL依赖。
设置源程序文件夹
- 配置
sourceDirectory为Scala源代码目录。
- 配置
添加Scala SDK
- 在项目结构中添加已安装的Scala SDK。
创建日志和HDFS配置文件
- 在
resources目录下创建log4j.properties和hdfs-site.xml。
- 在
创建词频统计对象
- 在
net.huawei.sql包中创建WordCount对象,实现词频统计逻辑。
- 在
运行程序
- 清理输出目录,运行程序,并在控制台查看结果。
- 查看HDFS中的输出文件和内容。
技术要点
- 使用Spark SQL进行数据处理和分析。
- 利用
explode函数处理数组或集合。 - 通过SQL查询进行数据聚合和排序。
- 处理HDFS文件系统与本地文件系统的交互。
预期结果
- 成功统计文本文件中的词频,并按降序排列。
- 将统计结果输出到HDFS,并能够正确显示。
可能遇到的问题
- HDFS配置错误导致无法连接或读取文件。
- Spark SQL查询语法错误。
- Maven项目依赖问题导致编译失败。
- Scala版本与项目不兼容。
结论
通过本实战,参与者将能够掌握使用Spark SQL进行文本处理和数据分析的技能,理解如何在分布式环境中处理大数据,并学会解决实际开发中可能遇到的问题。