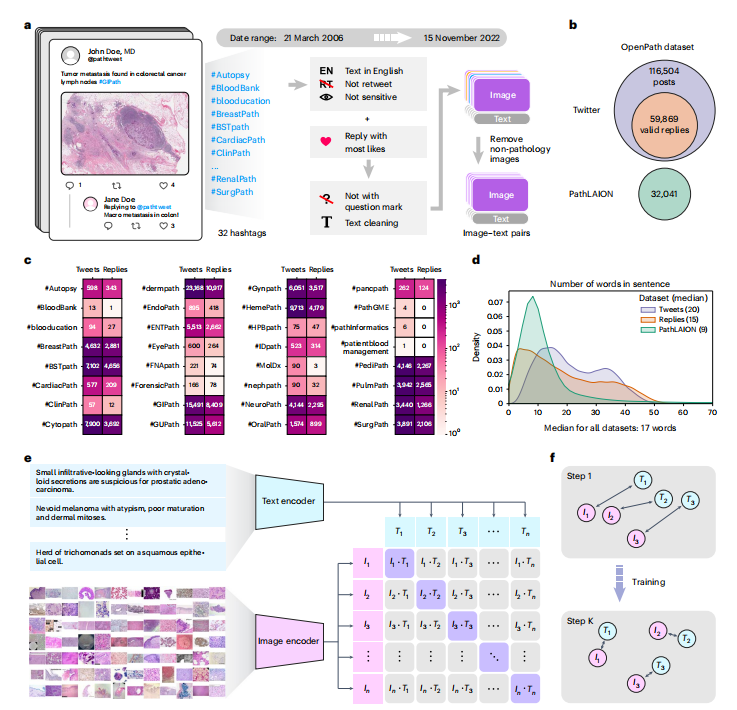
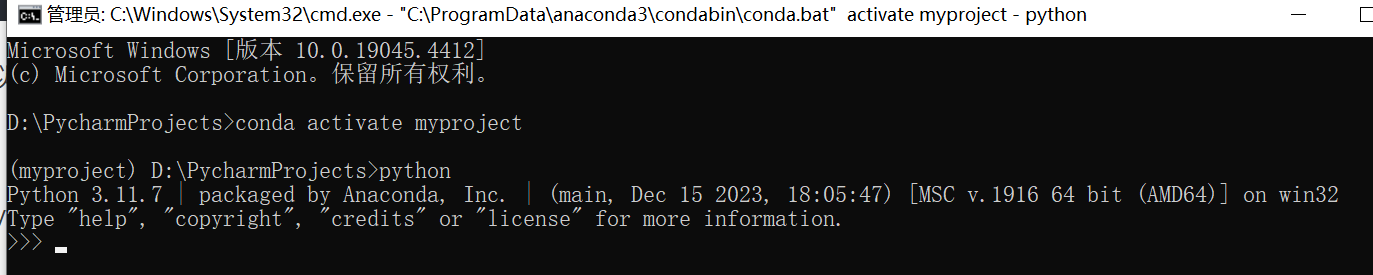
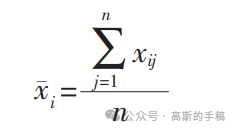加载环境
library("MASS")
require(MASS)
# Modern Applied Statistics with S,"S"指的是S语言,由贝尔实验室的约翰·钱伯斯(John Chambers)等人开发。S语言是R语言的前身,许多R语言的语法和功能都继承自S语言。
library("Matrix")
# Matrix包提供了用于处理稀疏和密集矩阵的函数。它可以高效地执行线性代数操作,比如计算矩阵的逆、求特征值等
# require(compiler)
# 使用require是因为它并不是必需的。如果你不使用compiler包,代码仍然可以正常运行。使用compiler包的目的是为了通过JIT(Just-In-Time)编译来提高代码的执行速度,特别是在处理大量循环或复杂计算时。
# enableJIT(4)
# 这是compiler的函数。这行代码启用JIT编译器,并设置为最高级别(4),即编译所有代码。这可以显著提高代码的执行速度。
计算未截断的检验分数
Non_Trucated_TestScore <- function(X, SampleSize, CorrMatrix)
{
Wi = matrix(SampleSize, nrow = 1);
sumW = sqrt(sum(Wi^2));
W = Wi / sumW;
Sigma = ginv(CorrMatrix);
XX = apply(X, 1, function(x) {
x1 <- matrix(x, ncol = length(x), nrow = 1);
T = W %*% Sigma %*% t(x1);
T = (T*T) / (W %*% Sigma %*% t(W));
return(T[1,1]);
}
);
return(XX);
}
SHom <- cmpfun(Non_Trucated_TestScore);
函数参数:
X: 一个矩阵,表示样本数据。X是一个M×K的矩阵,其中M是SNP的数量,K是要组合的汇总统计量的数量。矩阵的每一列包含一个性状的M个SNP的汇总统计量。如果在一个队列中分析了多个性状,每个性状的汇总统计量将放在一列中。矩阵的每一行代表一个SNP。SampleSize: 样本大小。SampleSize是一个长度为M的向量,包含了用于获得K个汇总统计量的M个样本量。当前版本假设不同SNP的样本量是相同的。SampleSize用于在组合汇总统计量时作为权重。CorrMatrix: 相关矩阵。CorrMatrix是X矩阵列之间的相关矩阵,是一个K×K的矩阵,其中K是汇总统计量的数量。。如果X矩阵中没有缺失值,可以通过调用R函数cor(X)来获得CorrMatrix。如果X中有缺失值,可以在删除具有缺失汇总统计量的SNP后以相同方式计算CorrMatrix。对于GWAS数据,这个过程对估计相关矩阵的影响很小。
函数的主要步骤如下:
- 计算权重
W,并对其进行归一化。 - 计算相关矩阵的广义逆矩阵
Sigma。 - 对每一行数据
x进行处理:- 将
x转换为矩阵x1。 - 计算检验分数
T。
- 将
- 返回每一行数据的检验分数。
用公式来表达:
计算权重
W:
W = W i ∑ W i 2 W = \frac{Wi}{\sqrt{\sum Wi^2}} W=∑Wi2Wi计算相关矩阵的广义逆矩阵
Sigma:
Σ = ginv ( CorrMatrix ) \Sigma = \text{ginv}(\text{CorrMatrix}) Σ=ginv(CorrMatrix)对每一行数据
x,计算检验分数T:
x 1 = matrix ( x , ncol = length ( x ) , nrow = 1 ) x1 = \text{matrix}(x, \text{ncol} = \text{length}(x), \text{nrow} = 1) x1=matrix(x,ncol=length(x),nrow=1)
T = W ⋅ Σ ⋅ x 1 T T = W \cdot \Sigma \cdot x1^T T=W⋅Σ⋅x1T
T = ( T ⋅ T ) W ⋅ Σ ⋅ W T T = \frac{(T \cdot T)}{W \cdot \Sigma \cdot W^T} T=W⋅Σ⋅WT(T⋅T)返回每一行数据的检验分数
T[1,1]。
最终返回所有行的检验分数。
计算截断的检验分数
# X:矩阵,每行表示一个SNP(M),每列表示一个变量(K)
# SampleSize:样本大小向量
# CorrMatrix:相关矩阵
# correct:是否校正权重flag,默认值为1
# startCutoff:截断起始值,默认为0
# endCutoff:截断结束值,默认为1
# CutoffStep:截断步长,默认值为0.05
# isAllpossible:是否使用所有可能的截断值,默认为TRUE
Trucated_TestScore <- function(X, SampleSize, CorrMatrix, correct = 1, startCutoff = 0, endCutoff = 1, CutoffStep = 0.05, isAllpossible = T)
{
N = dim(X)[2];
Wi = matrix(SampleSize, nrow = 1);
sumW = sqrt(sum(Wi^2));
W = Wi / sumW;
XX = apply(X, 1, function(x) {
TTT = -1;
if (isAllpossible == T ) {
cutoff = sort(unique(abs(x))); ## it will filter out any of them.
} else {
cutoff = seq(startCutoff, endCutoff, CutoffStep);
}
for (threshold in cutoff) {
x1 = x;
index = which(abs(x1) < threshold);
if (length(index) == N) break;
A = CorrMatrix;
W1 = W;
if (length(index) !=0 ) {
x1 = x1[-index];
A = A[-index, -index]; ## update the matrix
W1 = W[-index];
}
if (correct == 1)
{
index = which(x1 < 0);
if (length(index) != 0) {
W1[index] = -W1[index]; ## update the sign
}
}
A = ginv(A);
x1 = matrix(x1, nrow = 1);
W1 = matrix(W1, nrow = 1);
T = W1 %*% A %*% t(x1);
T = (T*T) / (W1 %*% A %*% t(W1));
if (TTT < T[1,1]) TTT = T[1,1];
}
return(TTT);
}
);
return(XX);
}
SHet <- cmpfun(Trucated_TestScore);
函数参数:
X: 一个矩阵,表示样本数据。SampleSize: 样本大小。CorrMatrix: 相关矩阵。correct: 一个布尔值,默认为1,表示是否需要修正符号。startCutoff: 截断的起始值,默认为0。endCutoff: 截断的结束值,默认为1。CutoffStep: 截断步长,默认为0.05。isAllpossible: 一个布尔值,默认为T,表示是否使用所有可能的截断值。
函数的主要步骤如下:
- 计算权重
W,并对其进行归一化。 - 对每一行数据
x进行处理:- 如果
isAllpossible为T,则计算所有可能的截断值cutoff。 - 否则,生成从
startCutoff到endCutoff的序列作为截断值。
- 如果
- 对每一个截断值
threshold:- 更新数据
x1和相关矩阵A,去除小于threshold的元素。 - 如果
correct为1,修正符号。 - 计算截断检验分数
T,并更新最大值TTT。
- 更新数据
- 返回每一行数据的最大截断检验分数。
用公式来表达:
计算权重
W:
W = W i ∑ W i 2 W = \frac{Wi}{\sqrt{\sum Wi^2}} W=∑Wi2Wi对每一行数据
x,计算截断值cutoff:
cutoff = { sort(unique(abs(x))) if isAllpossible = T seq(startCutoff, endCutoff, CutoffStep) otherwise \text{cutoff} = \begin{cases} \text{sort(unique(abs(x)))} & \text{if } \text{isAllpossible} = T \\ \text{seq(startCutoff, endCutoff, CutoffStep)} & \text{otherwise} \end{cases} cutoff={sort(unique(abs(x)))seq(startCutoff, endCutoff, CutoffStep)if isAllpossible=Totherwise对每一个截断值
threshold,更新数据x1和相关矩阵A:
x 1 = x (remove elements where ∣ x 1 ∣ < threshold ) x1 = x \quad \text{(remove elements where } |x1| < \text{threshold}) x1=x(remove elements where ∣x1∣<threshold)
A = CorrMatrix (remove corresponding rows and columns) A = \text{CorrMatrix} \quad \text{(remove corresponding rows and columns)} A=CorrMatrix(remove corresponding rows and columns)
W 1 = W (remove corresponding elements) W1 = W \quad \text{(remove corresponding elements)} W1=W(remove corresponding elements)如果
correct为1,修正符号:
W 1 [ index ] = − W 1 [ index ] (where x 1 < 0 ) W1[\text{index}] = -W1[\text{index}] \quad \text{(where } x1 < 0) W1[index]=−W1[index](where x1<0)计算截断检验分数
T:
A = ginv ( A ) A = \text{ginv}(A) A=ginv(A)
x 1 = matrix ( x 1 , n r o w = 1 ) x1 = \text{matrix}(x1, nrow = 1) x1=matrix(x1,nrow=1)
W 1 = matrix ( W 1 , n r o w = 1 ) W1 = \text{matrix}(W1, nrow = 1) W1=matrix(W1,nrow=1)
T = ( W 1 ⋅ A ⋅ x 1 T ) 2 W 1 ⋅ A ⋅ W 1 T T = \frac{(W1 \cdot A \cdot x1^T)^2}{W1 \cdot A \cdot W1^T} T=W1⋅A⋅W1T(W1⋅A⋅x1T)2返回每一行数据的最大截断检验分数
TTT:
T T T = max ( T ) TTT = \max(T) TTT=max(T)
最终返回所有行的最大截断检验分数。
估计Gamma分布的参数
EstimateGamma <- function (N = 1E6, SampleSize, CorrMatrix, correct = 1, startCutoff = 0, endCutoff = 1, CutoffStep = 0.05, isAllpossible = T) {
Wi = matrix(SampleSize, nrow = 1);
sumW = sqrt(sum(Wi^2));
W = Wi / sumW;
Permutation = mvrnorm(n = N, mu = c(rep(0, length(SampleSize))), Sigma = CorrMatrix, tol = 1e-8, empirical = F);
Stat = Trucated_TestScore(X = Permutation, SampleSize = SampleSize, CorrMatrix = CorrMatrix,
correct = correct, startCutoff = startCutoff, endCutoff = endCutoff,
CutoffStep = CutoffStep, isAllpossible = isAllpossible);
a = min(Stat)*3/4
ex3 = mean(Stat*Stat*Stat)
V = var(Stat);
for (i in 1:100){
E = mean(Stat)-a;
k = E^2/V
theta = V/E
a = (-3*k*(k+1)*theta**2+sqrt(9*k**2*(k+1)**2*theta**4-12*k*theta*(k*(k+1)*(k+2)*theta**3-ex3)))/6/k/theta
}
para = c(k,theta,a);
return(para);
}
函数参数:
N: 生成的样本数量,默认为1E6。SampleSize: 样本大小。CorrMatrix: 相关矩阵。correct: 一个布尔值,默认为1,表示是否需要修正符号。startCutoff: 截断的起始值,默认为0。endCutoff: 截断的结束值,默认为1。CutoffStep: 截断步长,默认为0.05。isAllpossible: 一个布尔值,默认为T,表示是否使用所有可能的截断值。
函数的主要步骤如下:
- 计算权重
W,并对其进行归一化。 - 生成
N个服从多元正态分布的随机样本Permutation。 - 使用
Trucated_TestScore函数计算截断检验分数Stat。 - 计算初始参数
a、ex3和V。 - 通过迭代更新参数
a,并计算Gamma分布的参数k和theta。 - 返回参数
k、theta和a。
用公式来表达:
计算权重
W:
W = W i ∑ W i 2 W = \frac{Wi}{\sqrt{\sum Wi^2}} W=∑Wi2Wi生成
N个服从多元正态分布的随机样本Permutation:
Permutation = mvrnorm ( n = N , μ = 0 , Σ = CorrMatrix ) \text{Permutation} = \text{mvrnorm}(n = N, \mu = \mathbf{0}, \Sigma = \text{CorrMatrix}) Permutation=mvrnorm(n=N,μ=0,Σ=CorrMatrix)使用
Trucated_TestScore函数计算截断检验分数Stat:
Stat = Trucated_TestScore ( X = Permutation , SampleSize = SampleSize , CorrMatrix = CorrMatrix , correct = correct , startCutoff = startCutoff , endCutoff = endCutoff , CutoffStep = CutoffStep , isAllpossible = isAllpossible ) \text{Stat} = \text{Trucated\_TestScore}(X = \text{Permutation}, \text{SampleSize} = \text{SampleSize}, \text{CorrMatrix} = \text{CorrMatrix}, \text{correct} = \text{correct}, \text{startCutoff} = \text{startCutoff}, \text{endCutoff} = \text{endCutoff}, \text{CutoffStep} = \text{CutoffStep}, \text{isAllpossible} = \text{isAllpossible}) Stat=Trucated_TestScore(X=Permutation,SampleSize=SampleSize,CorrMatrix=CorrMatrix,correct=correct,startCutoff=startCutoff,endCutoff=endCutoff,CutoffStep=CutoffStep,isAllpossible=isAllpossible)计算初始参数
a、ex3和V:
a = 3 4 min ( Stat ) a = \frac{3}{4} \min(\text{Stat}) a=43min(Stat)
ex3 = mean ( Stat 3 ) \text{ex3} = \text{mean}(\text{Stat}^3) ex3=mean(Stat3)
V = var ( Stat ) V = \text{var}(\text{Stat}) V=var(Stat)通过迭代更新参数
a,并计算Gamma分布的参数k和theta:
for i in 1 : 100 do \text{for } i \text{ in } 1:100 \text{ do} for i in 1:100 do
E = mean ( Stat ) − a E = \text{mean}(\text{Stat}) - a E=mean(Stat)−a
k = E 2 V k = \frac{E^2}{V} k=VE2
θ = V E \theta = \frac{V}{E} θ=EV
a = − 3 k ( k + 1 ) θ 2 + 9 k 2 ( k + 1 ) 2 θ 4 − 12 k θ ( k ( k + 1 ) ( k + 2 ) θ 3 − ex3 ) 6 k θ a = \frac{-3k(k+1)\theta^2 + \sqrt{9k^2(k+1)^2\theta^4 - 12k\theta(k(k+1)(k+2)\theta^3 - \text{ex3})}}{6k\theta} a=6kθ−3k(k+1)θ2+9k2(k+1)2θ4−12kθ(k(k+1)(k+2)θ3−ex3)返回参数
k、theta和a:
para = ( k , θ , a ) \text{para} = (k, \theta, a) para=(k,θ,a)
最终返回所有行的检验分数。
计算经验分布
# N:模拟次数,默认值为1E6,即100,000
# 其它参数与 Trucated_TestScore 相同
EmpDist <- function (N = 1E6, SampleSize, CorrMatrix, correct = 1, startCutoff = 0, endCutoff = 1, CutoffStep = 0.05, isAllpossible = T) {
Wi = matrix(SampleSize, nrow = 1);
sumW = sqrt(sum(Wi^2));
W = Wi / sumW;
Permutation = mvrnorm(n = N, mu = c(rep(0, length(SampleSize))), Sigma = CorrMatrix, tol = 1e-8, empirical = F);
Stat = Trucated_TestScore(X = Permutation, SampleSize = SampleSize, CorrMatrix = CorrMatrix, correct = correct, startCutoff = startCutoff, endCutoff = endCutoff, CutoffStep = CutoffStep, isAllpossible = isAllpossible);
return(Stat);
}
函数参数:
N: 生成的样本数量,默认为1,000,000。SampleSize: 样本大小。CorrMatrix: 相关矩阵。correct: 一个布尔值,默认为1,表示是否需要修正符号。startCutoff: 截断的起始值,默认为0。endCutoff: 截断的结束值,默认为1。CutoffStep: 截断步长,默认为0.05。isAllpossible: 一个布尔值,默认为T,表示是否使用所有可能的截断值。
函数的主要步骤如下:
- 计算权重
W,并对其进行归一化。 - 使用多元正态分布生成
N个样本,均值为0,协方差矩阵为CorrMatrix。 - 调用
Trucated_TestScore函数计算截断检验分数。 - 返回计算得到的统计量
Stat。
用公式来表达:
计算权重
W:
W = W i ∑ W i 2 W = \frac{Wi}{\sqrt{\sum Wi^2}} W=∑Wi2Wi使用多元正态分布生成
N个样本:
Permutation = mvrnorm ( n = N , μ = 0 , Σ = CorrMatrix ) \text{Permutation} = \text{mvrnorm}(n = N, \mu = \mathbf{0}, \Sigma = \text{CorrMatrix}) Permutation=mvrnorm(n=N,μ=0,Σ=CorrMatrix)调用
Trucated_TestScore函数计算截断检验分数:
Stat = Trucated_TestScore ( X = Permutation , SampleSize = SampleSize , CorrMatrix = CorrMatrix , correct = correct , startCutoff = startCutoff , endCutoff = endCutoff , CutoffStep = CutoffStep , isAllpossible = isAllpossible ) \text{Stat} = \text{Trucated\_TestScore}(X = \text{Permutation}, \text{SampleSize} = \text{SampleSize}, \text{CorrMatrix} = \text{CorrMatrix}, \text{correct} = \text{correct}, \text{startCutoff} = \text{startCutoff}, \text{endCutoff} = \text{endCutoff}, \text{CutoffStep} = \text{CutoffStep}, \text{isAllpossible} = \text{isAllpossible}) Stat=Trucated_TestScore(X=Permutation,SampleSize=SampleSize,CorrMatrix=CorrMatrix,correct=correct,startCutoff=startCutoff,endCutoff=endCutoff,CutoffStep=CutoffStep,isAllpossible=isAllpossible)返回统计量
Stat。