如何在Python中实现决策树分类?
在机器学习领域,决策树算法是一种常用且高效的分类与回归方法。它不仅易于理解和解释,还能处理数值型和分类型数据。本文将带你深入探索Python中的决策树算法,理解其基本原理,并通过代码示例来展示如何在实际应用中使用这一强大的工具。
一、决策树算法概述
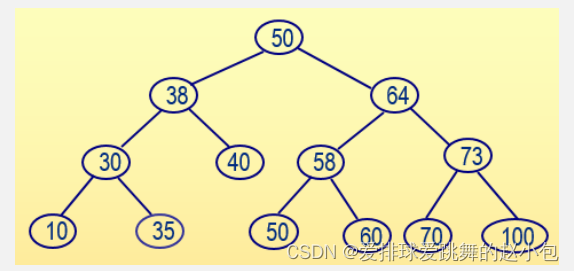
决策树是一种树状结构,其中每个内部节点表示一个特征的测试,每个分支表示测试结果的输出,而每个叶子节点则表示一个类别或回归值。决策树的生成过程可以看作是对特征空间的递归划分,直到满足某些停止条件为止。
决策树算法主要分为分类决策树(Classification Tree)和回归决策树(Regression Tree)。分类决策树用于分类任务,而回归决策树则用于回归任务。
二、决策树的基本原理
决策树的生成基于以下几个核心概念:
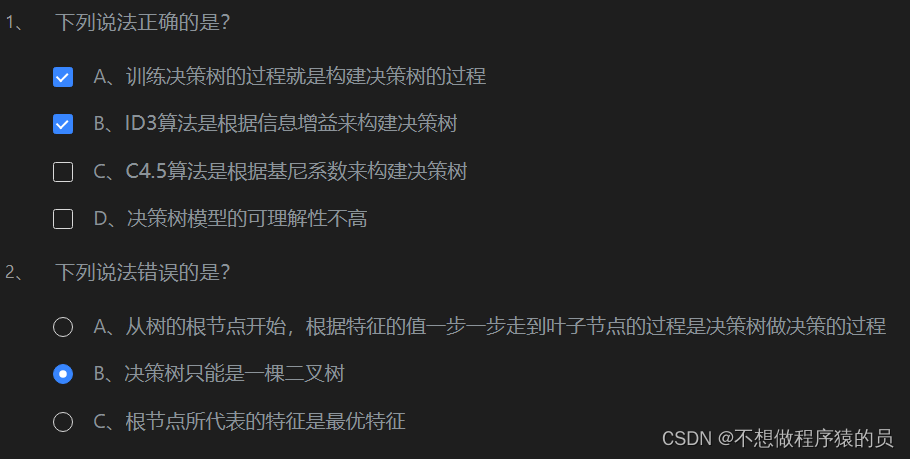
- 特征选择:在每一步分裂中,选择一个特征来划分数据。常用的选择标准有信息增益、信息增益率和基尼指数。
- 停止条件:当所有特征都已被使用或者某一节点的数据全部属于同一类别时,停止分裂。
- 剪枝:为防止过拟合,可以通过剪枝技术来简化决策树。剪枝分为预剪枝和后剪枝两种。
三、在Python中实现决策树
在Python中,我们可以使用scikit-learn库来实现决策树算法。下面是一个使用决策树进行分类的示例:
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'模型的准确率: {accuracy:.2f}')
# 可视化决策树
plt.figure(figsize=(12, 8))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()
四、决策树的优缺点
决策树算法有许多优点,但也存在一些不足:
优点:
- 易于理解和解释:树结构直观,决策路径清晰。
- 无需特征归一化:无需对数据进行标准化或归一化处理。
- 处理数据类型多样:既可以处理数值型数据,也可以处理分类型数据。
缺点:
- 容易过拟合:如果不进行剪枝处理,决策树容易对训练数据过拟合。
- 对噪声数据敏感:小的噪声数据可能会对树的结构产生较大影响。
- 偏向于选择较多取值的特征:决策树倾向于选择那些取值较多的特征进行分裂。
五、决策树的优化
为了解决决策树的不足,我们可以采用以下几种方法进行优化:
- 剪枝:通过预剪枝和后剪枝技术来防止过拟合。
- 集成学习:结合多棵决策树,如随机森林(Random Forest)和梯度提升树(Gradient Boosting Trees),来提高模型的稳定性和准确性。
- 参数调整:通过调整决策树的参数,如最大深度、最小样本分裂数等,来优化模型性能。
六、实战:PlugLink中的决策树应用
在实际应用中,决策树常被用于各种分类和回归任务。PlugLink作为一个开源的自动化工作流平台,也能利用决策树算法来实现智能化的自动决策。例如,可以通过决策树对大量客户数据进行分类,帮助企业自动识别潜在客户,优化营销策略。
# 示例代码:使用PlugLink进行客户分类
from PlugLink import PlugLink
def classify_customers(data):
# 假设data是一个包含客户信息的DataFrame
X = data[['feature1', 'feature2', 'feature3']]
y = data['target']
# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='entropy', max_depth=5)
clf.fit(X, y)
# 返回分类结果
return clf.predict(X)
# 将分类函数注册为PlugLink插件
pluglink = PlugLink()
pluglink.register_plugin('customer_classifier', classify_customers)
更多关于PlugLink的信息和源码,请访问PlugLink项目。
七、结语
决策树算法作为一种经典的机器学习方法,具有广泛的应用前景。通过本文的介绍,希望你能更好地理解决策树的基本原理,并能够在Python中熟练运用这一工具。未来,随着技术的发展和创新,决策树算法将在更多领域展现其强大的威力,为我们的工作和生活带来更多便利。