几种定位方式
简单代码
from selenium import webdriver
import time
# 创建浏览器驱动对象
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() # 参数写浏览器驱动文件的路径,若配置到环境变量就不用写了
# 访问网址
driver.get("https://www.baidu.com/")
#找到输入搜素框
inpEle = driver.find_element(By.ID,"kw")
inpEle.send_keys("海康交通大数据")
# 找到搜索按钮
sEle = driver.find_element(By.ID,"su")
sEle.click()
# 退出浏览器
# driver.quit()By中有8个,定位方式
- 使用class_name 时 如果遇到多个class值有多个情况的,选择其中之一
- link_text 是用在a标签的
- xpath , 两个// ,表示找后代,相对路径, / 表示找儿子, 全路径
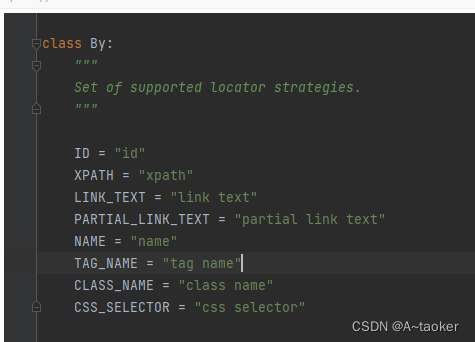
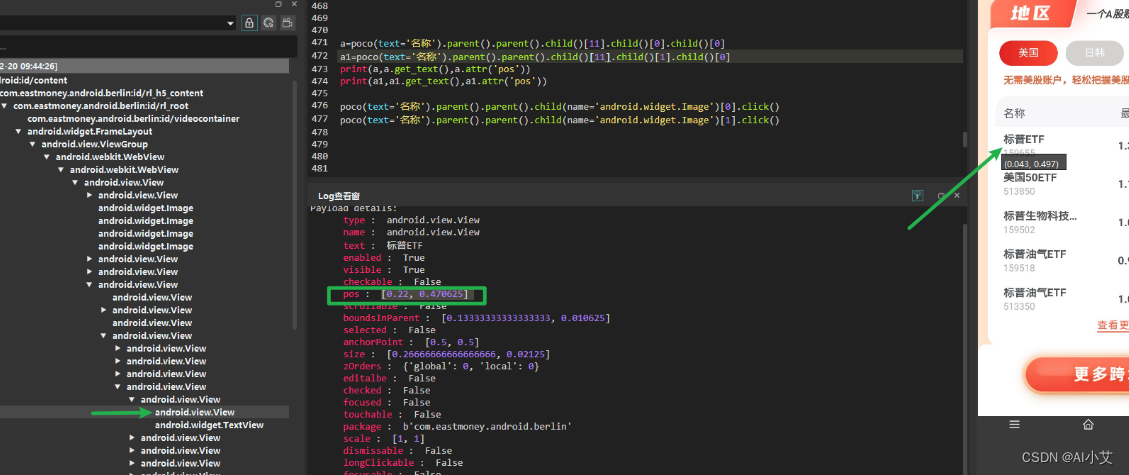
id ,class_name, name 底层都是css
如下图的源码可知: id ,class_name, name 底层都是css
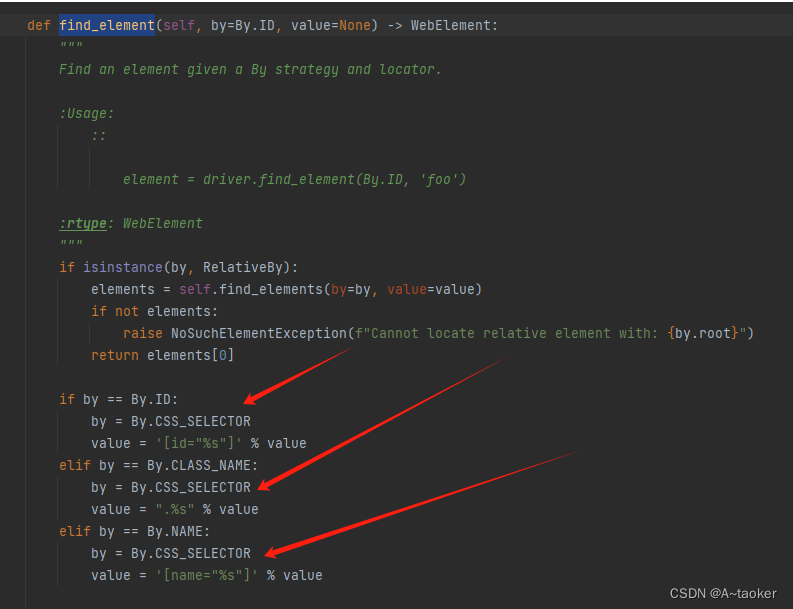
find_element 和 find_elements 区分
通过find_element 来找
- 找不到会报错
- 如果能匹配多个,匹配到第一个就找一个
find_elements, 返回的是列表
写法变形(后面框架要用到)
本来是这么写的
![]()
变成这么写, 把元素独立出来。就可以单独维护
ele = ('id','kw')
driver.find_element(*ele)css-selector 定位
1234 (直接连起来是and关系, 如果是 用(逗号)分割,就是or关系 ),and时顺序是1234
- 1.根据标签 P
- 2.根据id #id (12结合写法 P#id)
- 3.根据class .class1.class2
- 如果是xpth和 css 属性值写法,属性值要把 空格带上,写完整 【属性=“值 值”】时
- 另外补充:如果是By.CLASS_NAME ,定位方式, 多个class,也只能写一个
- 4.根据属性 ["属性"=“属性值”]
- 不常规 [属性] (补充:不写值,表示有此属性的)
- 常用 input[id="username"] + 加上标签更容易唯一 属性可以模糊匹配属性值如下图
- input[class="class1 class2"])
- 还能模糊,包含[*=],开头是[^=],结尾是[$=]
- 根据路径
- 空格 后代 如:#kw p 找后代的p标签 空格 (表示在某一节点 后代里去找 p)
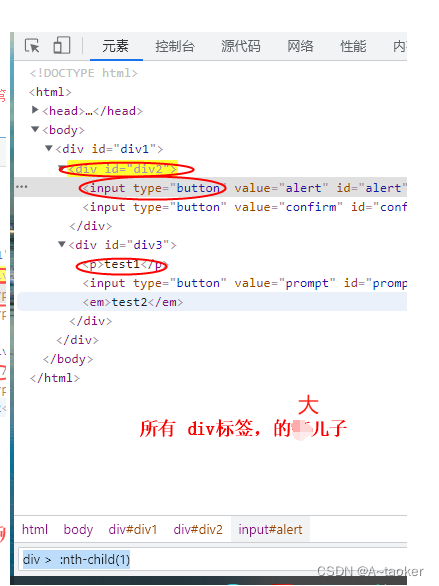
- > 找儿子 如:#a1 > p 儿子选择器 > 大于 (补充 >* 表示所有儿子, 空格* 表示所有后代)
- + 找二弟 (找相邻弟弟) 如 :#ab1 + li 选择相邻弟弟 + (补充:+p 表示紧挨着的是p才能找到,p如果没有紧挨着还找不到)
- ~ 找同级弟弟 如:#ab2 ~ li 选择所有亲弟弟 ~ (补充 ~ * 表示所有的弟弟)
- 伪类选择器:(常用的三个)
- :nth-child(n) 表示找结果的第几个:如:p:nth-child(1) # 第一个p
- :first-child 结合 > ,可以用来查某个标签儿子中的大儿子 div>:first-child
- :last-child
- 补充:
- :nth-of-type(1) 表示某种类型的第一个?
- :not(p) 不要某种标签 (括号里可以写标签,或者.classsname, # id )
用css定位时补充:假如id为数字开头
#id #id值,这种不行
[id="31qvvq"] # css的属性值定位是可以的
Xpath定位
/ 一个表示一层一层往下找 (儿子中找)
// 两个表示从后代找 (后代中找)
只有两种情况,我会用xpath
a. 想用多个属性, //input[@id='kw' and @class]
b .想用文本来取时 //*[text(),"文本"] //*[contains(text(),"文本")]