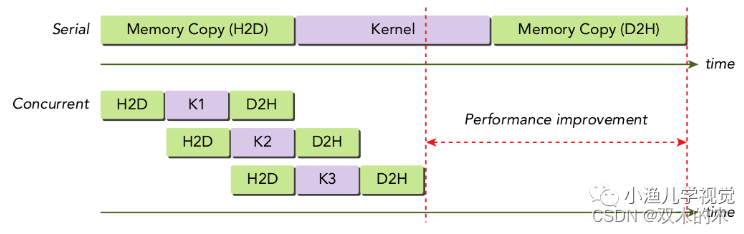
CUDA代码高效计算策略
高效公式
✒️Math代表数学计算量,Memory代表每个线程的内存
🌟提高效率思路:
最大化每个线程的计算量
最小化每个线程的内存读取速度
每个线程读取的数据量小
每个线程读取的速度快 PS:本地内存>共享内存>>全局内存
合并全局内存
⭐️提出:如果每个线程访问的是连续的内存地址,CUDA硬件会将这些内存访问合并成一次大的内存事务,从而提高内存访问效率。例如下面示例:
__global__ void kernel(float *A, float *B, int N) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
B[idx] = A[idx] * 2.0f;
}
}
效率:连续读取 > 间隔读取 >> 随机读取
//连续读取
__global__ void continuousRead(float *input, float *output, int N) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
output[idx] = input[idx];
}
}
//间隔读取
__global__ void strideRead(float *input, float *output, int N, int stride) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx * stride < N) {
output[idx] = input[idx * stride];stride代表步长,即间隔长度
}
}
//随机读取
__global__ void randomRead(float *input, float *output, int *indices, int N) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
output[idx] = input[indices[idx]];
}
}🌟PS:可能这个地方有人会有一些疑问:线程不是并行而非串行吗?为什么连续内存还有效果?
Reply:上一章我们提到CUDA线程在硬件上是以warps形式执行,而一个warp由32个连续的线程组成,在一个warp内,所有的线程是同步执行的。当这些线程同时请求内存时,如果这些线程访问的内存地址是连续的,GPU硬件可以将这些访问合并为一个或少数几个内存事务,这种合并就称为内存合并(Memory Coalescing)。
线程发散(避免)
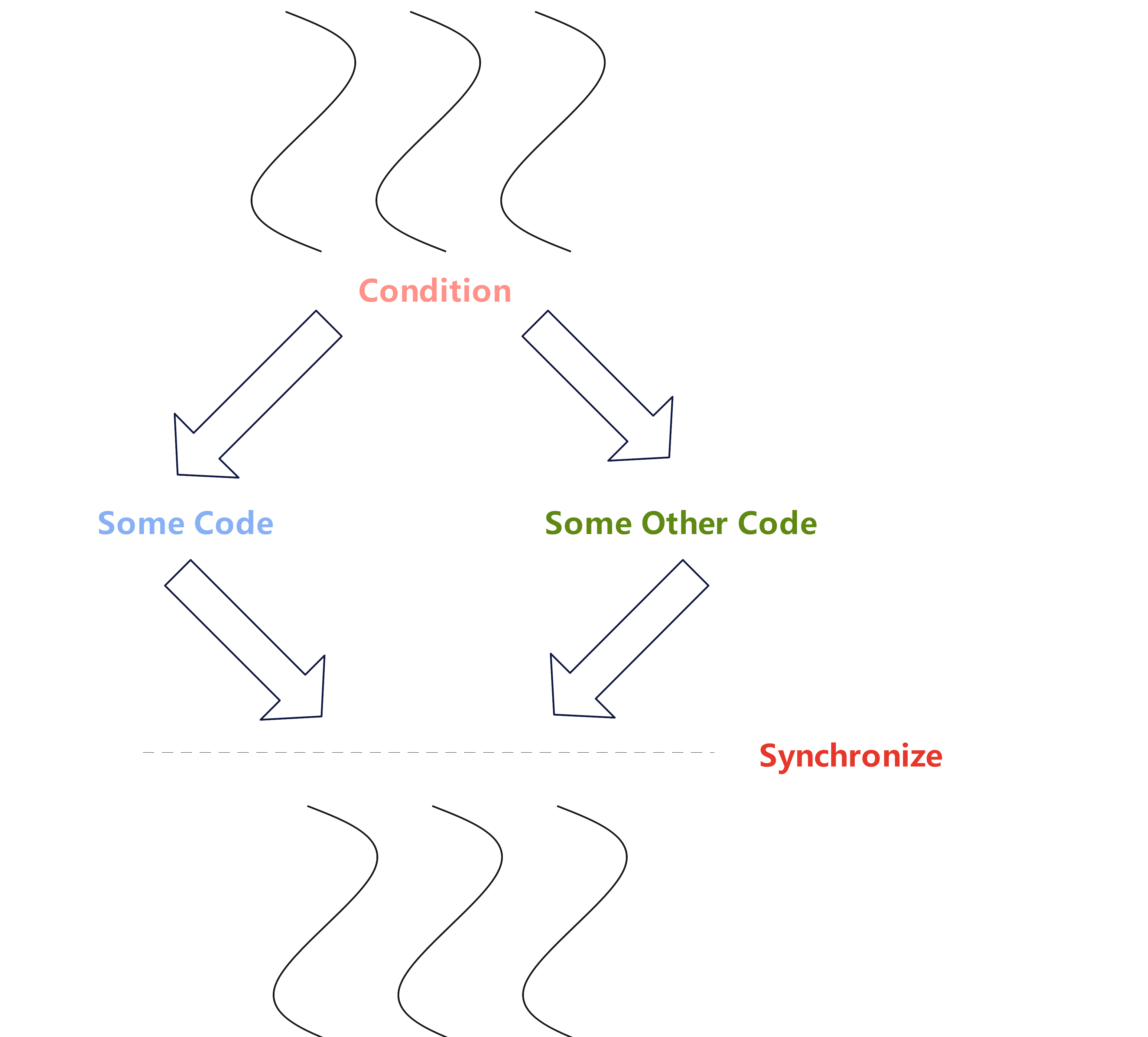
🚨线程发散:当warp中的线程遇到不同的执行路径时,会导致分支发散。在这种情况下,warp会按顺序执行每个分支路径,直到所有路径都执行完。例如下面导致发散的示例:
Kernel中做条件判断
__global__ void kernel(){
if(/*condition*/){
//some code 分支一
}else{
//some other code 分支二
}
}
循环长度不同
__global__ void kernel(){
//pre loop code
int tid = threadIdx.x;
for(int i=0;i<threadIdx.x;i++){
//loop code
}
//post loop code
}🌟不同线程需要执行的循环次数不同,而warp内所有线程是同步的,也就是说所有线程都要到达barrier才能进行下一步,这种线程差异导致线程分散
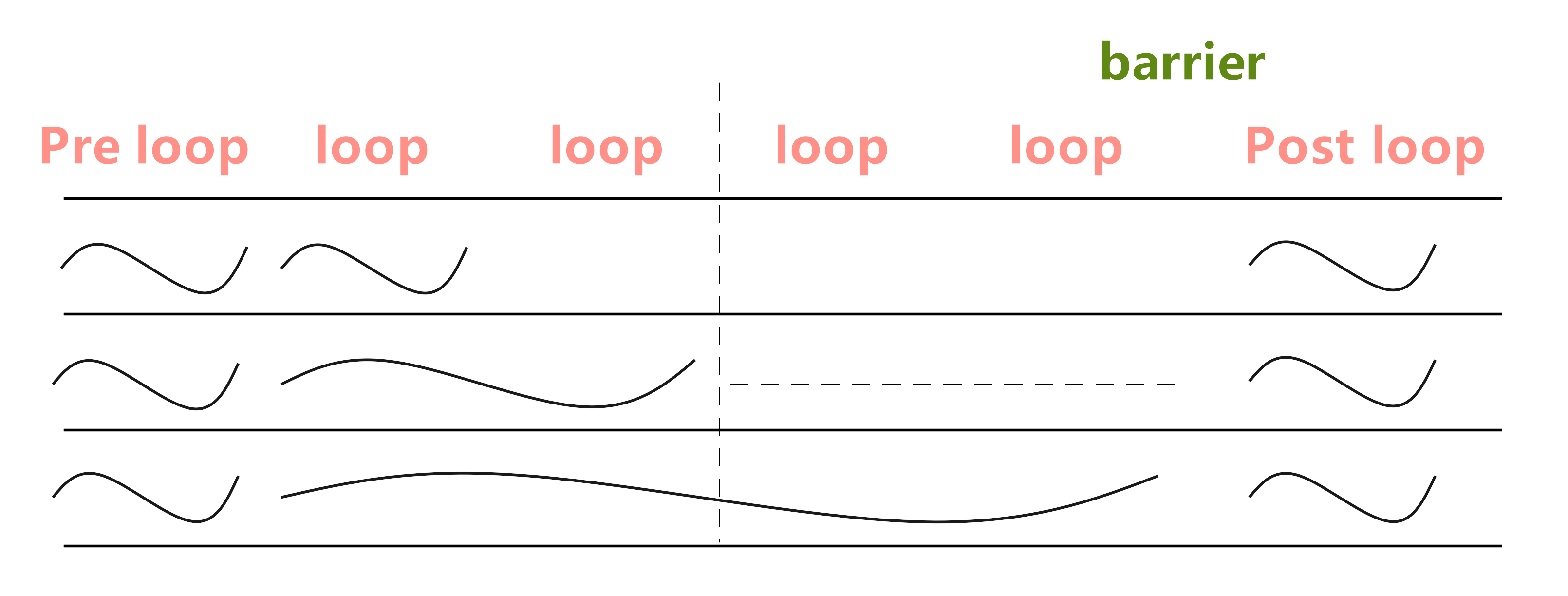
Kernel加载方式
🙅注意事项:Kernel 的加载中,自定义的线程数,线程块的数量等都不要超过系统本身的设定,否则, 会影响机器的效率。
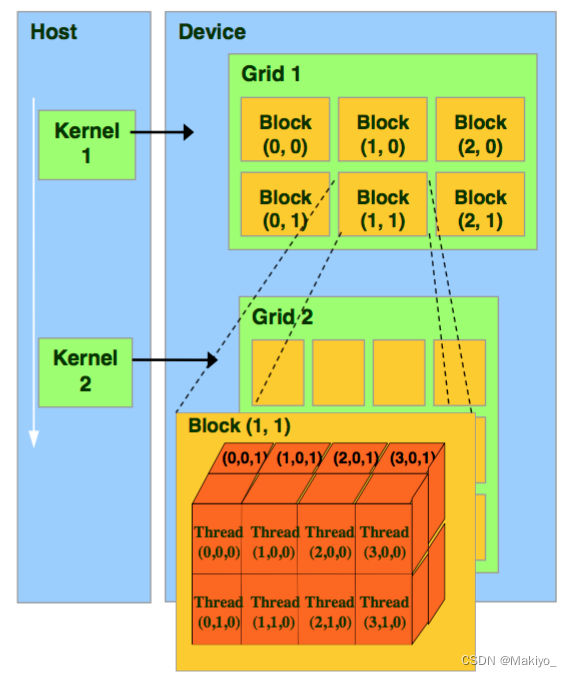
PS:线程是逻辑上分块,物理上不分块,每个线程在核函数Kernel中都有一个唯一的身份标识idx,且idx由<<<dimGrid,dimBlock>>>确定,dimGrid,dimBlock保存为内建变量(内建变量(Built-in Variables)是一些特殊的变量,它们由CUDA运行时系统提供,用于在CUDA核函数中获取线程和块的信息。这些变量是在编译时或运行时由CUDA驱动程序和运行时环境设置的)
//配置线程code,最大允许线程块大小1024
Kernel<<<dimGrid,dimBlock>>>(argv);
//Kernel: 在这里表示要执行的CUDA核函数的名称。 <<<dimGrid, dimBlock>>>:这部分称为启动配置(Launch Configuration),用来指定并行执行CUDA核函数时的线程组织和分布。 argv: 这是传递给CUDA核函数的参数列表。🌟详解:dimGrid用于指定网格(Grid)的维度和大小。网格是线程块(Thread Block)的集合,用于管理并发执行的线程块。dimBlock:用于指定线程块的维度和大小。线程块是GPU中并行执行的基本单位。
gridDim和blockDim是类型为dim3的变量,该变量为一个结构体,具有x,y,z三个成员。因此,显而易见的cuda可以组织三维网格和线程块
//dim3结构体
struct dim3 {
unsigned int x, y, z;
};
//Configuration Grid
//如果 dimGrid 是一维的,通常表示线程块网格只有一行
dim3 gridDim(blocksPerGrid, 1, 1);
//如果 dimGrid 是二维的,表示线程块网格是一个矩形
dim3 gridDim(blocksPerGridX, blocksPerGridY, 1);
//如果 dimGrid 是三维的,表示线程块网格是一个立方体
dim3 gridDim(blocksPerGridX, blocksPerGridY, blocksPerGridZ);
//Configuration thread Block
//一维线程块的定义
dim3 blockDim(threadsPerBlock, 1, 1);
//二维线程块的定义
dim3 blockDim(threadsPerBlockX, threadsPerBlockY, 1);
//三维线程块的定义
dim3 blockDim(threadsPerBlockX, threadsPerBlockY, threadsPerBlockZ);Kernel加载--1D模式
//网格与线程块均为1D
int idx = blockIdx.x*blockDim.x+threadIdx.x;
//加载方法
Kernel<<<numBlock,threadsPerBlock>>>(argv);
//网格1D与线程块为2D
int idx = blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
//加载方法
dim3 dimBlock(x,y);
Kernel<<<numBlock,threadsPerBlock>>>(argv);
//网格1D与线程块为3D
int idx = blockIdx.x * blockDim.x * blockDim.y * blockDim.z + threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x;
//加载方法
dim3 dimBlock(x,y,z);
Kernel<<<numBlock,threadsPerBlock>>>(argv);Kernel加载--2D模式
//网格2D与线程块为1D
int blockId = blockIdx.y * gridDim.x + blockIdx.x;
int Idx = blockId * blockDim.x + threadIdx.x;
//加载方法
dim3 dimGrid(x,y);
Kernel<<<numBlock,threadsPerBlock>>>(argv);
//网格2D与线程块为2D
int blockId = blockIdx.y * gridDim.x + blockIdx.x;
int Idx = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x;
//加载方法
dim3 dimGrid(x1,y1),dimBlock(x2,y2);
Kernel<<<dimGrid,dimBlock>>>(argv);
//网格2D与线程块为3D
int blockId = blockIdx.y * gridDim.x + blockIdx.x;
int Idx = blockId * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x)+ threadIdx.x;
//加载方法
dim3 dimGrid(x1,y1),dimBlock(x2,y2,z2);
Kernel<<<dimGrid,dimBlock>>>(argv);Kernel加载方法--3D模式
//网格3D与线程块为1D
int blockId = blockIdx.x+ blockIdx.y * gridDim.x+ gridDim.x * gridDim.y * blockIdx.z;
int Idx = blockId * blockDim.x + threadIdx.x;
//加载方法
dim3 dimGrid(x,y,z);
Kernel<<<dimGrid,threadsPerBlock>>>(argv);
//网格3D与线程块为2D
int blockId = blockIdx.x+ blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z;
int Idx = blockId * (blockDim.x * blockDim.y)+ (threadIdx.y * blockDim.x) + threadIdx.x;
//加载方法
dim3 dimGrid(x1,y1,z1),dimBlock(x2,y2);
Kernel<<<dimGrid,dimBlock>>>(argv);
//网格3D与线程块为3D
int blockId = blockIdx.x+ blockIdx.y * gridDim.x+ gridDim.x * gridDim.y * blockIdx.z;
int Idx = blockId * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x)+ threadIdx.x;
//加载方法
dim3 dimGrid(x1,y1,z1),dimBlock(x2,y2,z2);
Kernel<<<dimGrid,dimBlock>>>(argv);kernel函数关键字
__global__ 关键字
声明核函数:__global__ 关键字用于声明一个函数,这个函数将在 GPU 上并行执行,每个线程都可以独立地执行该函数。这种函数称为 CUDA 核函数。
GPU 执行上下文:CUDA 核函数由大量的线程并行执行,每个线程都使用唯一的线程ID来确定它的数据和计算任务。
函数限制:CUDA 核函数不能有可变长度的参数列表,也不能有静态变量。
⭐️注意:在CUDA编程中,__global__ 修饰的 CUDA 核函数(Kernel Function)只能返回 void。这是因为 CUDA 核函数是用来并行执行计算任务的,通常不需要返回具体的数值给调用者,而是通过修改传递给核函数的指针参数来改变数据。
__device__关键字
声明核函数:__device__ 修饰符用于声明函数(包括全局函数和静态成员函数),表示这些函数将在设备(GPU)上执行,即它们是 CUDA 设备函数。
函数限制:__device__ 函数只能从设备上调用,不能从主机(CPU)上调用。这些函数通常用于在 GPU 上执行的计算任务,例如 CUDA 核函数或设备内部的工具函数。
__host__关键字
声明核函数:__host__ 修饰符用于声明函数在主机(CPU)上执行,即它们是普通的主机函数。
函数限制:默认情况下,函数被视为 __host__ 函数,因此通常不需要显式地添加 __host__ 修饰符。这些函数可以在主机(CPU)上调用。

CUDA中的各种内存的代码使用
本地变量Local Memory
__global__ void use_local_memory(float in_data)
{
float f;
f = in_data;
//real code
}全局变量Global Memory
//h_xx命名一般代表host变量,d_xx命名一般代表device变量
__global__ void use_global_memory(float *in_data){
//in_data is a pointer into global memory on the device
in_data[threadIdx.x] = 2.0f;
}
float h_arr[128];
float *d_arr;
//allocate global memory on the device,place result int "d__arr"
cudaMalloc((void**)&d_arr,sizeof(float)*128);//强制类型转换 (void**)&d_arr 是为了符合 cudaMalloc 函数的参数要求,以便正确地分配并获取设备上的内存地址。
//now copy data from host memory h_arr to device memory d_arr
cudaMemcpy((void*)d__arr,(void*)h_arr,sizeof(float)*128,cudaMemcpyHostToDevice);
//launch the kernel 1block of 128 threads
use_global_memory<<<1,128>>>(d__arr);
//copy the modified array back to the host
cudaMemcpy((void*)h__arr,(void*)d_arr,sizeof(float)*128,cudaMemcpyDeviceToHost);共享变量
__global__ void use_shared_memory_GPU(float *array)
{
// local variables, private to each thread
int i, index = threadIdx.x;
float average, sum = 0.0f;
// __shared__ variables are visible to all threads in the thread block
// and have the same lifetime as the thread block
__shared__ float sh_arr[128];
// copy data from "array" in global memory to sh_arr in shared memory.
// here, each thread is responsible for copying a single element.
sh_arr[index] = array[index];
__syncthreads(); // ensure all the writes to shared memory have completed
// now, sh_arr is fully populated. Let's find the average of all previous elements
for (i=0; i<index; i++) { sum += sh_arr[i]; }
average = sum / (index + 1.0f);
// if array[index] is greater than the average of array[0..index-1], replace with average.
// since array[] is in global memory, this change will be seen by the host (and potentially
// other thread blocks, if any)
if (array[index] > average) { array[index] = average; }
// the following code has NO EFFECT: it modifies shared memory, but
// the resulting modified data is never copied back to global memory
// and vanishes when the thread block completes
sh_arr[index] = 3.14;
}
int main(int argc, char **argv)
{
/*
* First, call a kernel that shows using local memory
*/
use_local_memory_GPU<<<1, 128>>>(2.0f);
/*
* Next, call a kernel that shows using global memory
*/
float h_arr[128]; // convention: h_ variables live on host
float *d_arr; // convention: d_ variables live on device (GPU global mem)
// allocate global memory on the device, place result in "d_arr"
cudaMalloc((void **) &d_arr, sizeof(float) * 128);
// now copy data from host memory "h_arr" to device memory "d_arr"
cudaMemcpy((void *)d_arr, (void *)h_arr, sizeof(float) * 128, cudaMemcpyHostToDevice);
// launch the kernel (1 block of 128 threads)
use_global_memory_GPU<<<1, 128>>>(d_arr); // modifies the contents of array at d_arr
// copy the modified array back to the host, overwriting contents of h_arr
cudaMemcpy((void *)h_arr, (void *)d_arr, sizeof(float) * 128, cudaMemcpyDeviceToHost);
// ... do other stuff ...
/*
* Next, call a kernel that shows using shared memory
*/
// as before, pass in a pointer to data in global memory
use_shared_memory_GPU<<<1, 128>>>(d_arr);
// copy the modified array back to the host
cudaMemcpy((void *)h_arr, (void *)d_arr, sizeof(float) * 128, cudaMemcpyHostToDevice);
// ... do other stuff ...
return 0;
}CUDA同步操作
原子操作
🌟概念:对于有很多线程需要同时读取或写入相同的内存时,保证同一时间只有一个线程能进行的操作。原子操作(Atomic Operations)是一种特殊的操作,用于在多个线程同时访问和修改共享内存位置时确保数据的一致性和正确性。原子操作能够保证在执行期间不会被中断,因此可以防止竞态条件(Race Condition)的发生。
原子操作类型
整数原子操作:atomicAdd(),atomicSub(),atomicExch(),atomicMin(),atomicMax(),atomicInc(),atomicDec(),atomicCAS()
浮点数原子操作:atomicAdd()是唯一一个支持浮点数的原子操作。
原子操作案例
问题:让 10000 个线程增加 10 个数组元素(如果直接相加会出错)
__global__ void increment_naive(int *g)
{
// which thread is this?
int i = blockIdx.x * blockDim.x + threadIdx.x;
// each thread to increment consecutive elements, wrapping at ARRAY_SIZE
i = i % ARRAY_SIZE;
g[i] = g[i] + 1;
}
__global__ void increment_atomic(int *g)
{
// which thread is this?
int i = blockIdx.x * blockDim.x + threadIdx.x;
// each thread to increment consecutive elements, wrapping at ARRAY_SIZE
i = i % ARRAY_SIZE;
atomicAdd(& g[i], 1);
}同步函数⭐️⭐️⭐️(使用频繁)
🌟_syncthreads():__syncthreads() 是CUDA编程中的一个特殊函数,用于在线程块内部同步线程的执行。它的作用是保证线程块内所有线程都执行到统一位置,然后才会继续执行后续的操作。例如下面例子:
// (for clarity, hardcoding 128 threads/elements and omitting out-of-bounds checks)
__global__ void use_shared_memory_GPU(float *array)
{
// local variables, private to each thread
int i, index = threadIdx.x;
float average, sum = 0.0f;
// __shared__ variables are visible to all threads in the thread block
// and have the same lifetime as the thread block
__shared__ float sh_arr[128];
// copy data from "array" in global memory to sh_arr in shared memory.
// here, each thread is responsible for copying a single element.
sh_arr[index] = array[index];
__syncthreads(); // ensure all the writes to shared memory have completed
// now, sh_arr is fully populated. Let's find the average of all previous elements
for (i=0; i<index; i++) { sum += sh_arr[i]; }
average = sum / (index + 1.0f);
// if array[index] is greater than the average of array[0..index-1], replace with average.
// since array[] is in global memory, this change will be seen by the host (and potentially
// other thread blocks, if any)
if (array[index] > average) { array[index] = average; }
// the following code has NO EFFECT: it modifies shared memory, but
// the resulting modified data is never copied back to global memory
// and vanishes when the thread block completes
sh_arr[index] = 3.14;
}并行化高效策略(一)--归约Reduce
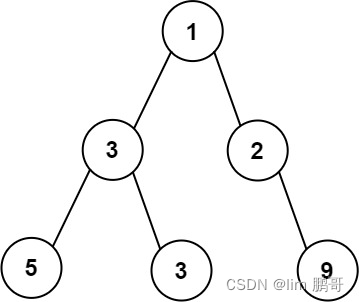
🌟归约Reduce:在CUDA中,归约操作的基本思想是将数组分成多个块(blocks),每个块中的线程通过合作来计算部分结果,然后再将这些部分结果汇总,直到得到最终结果。例如下图案例:
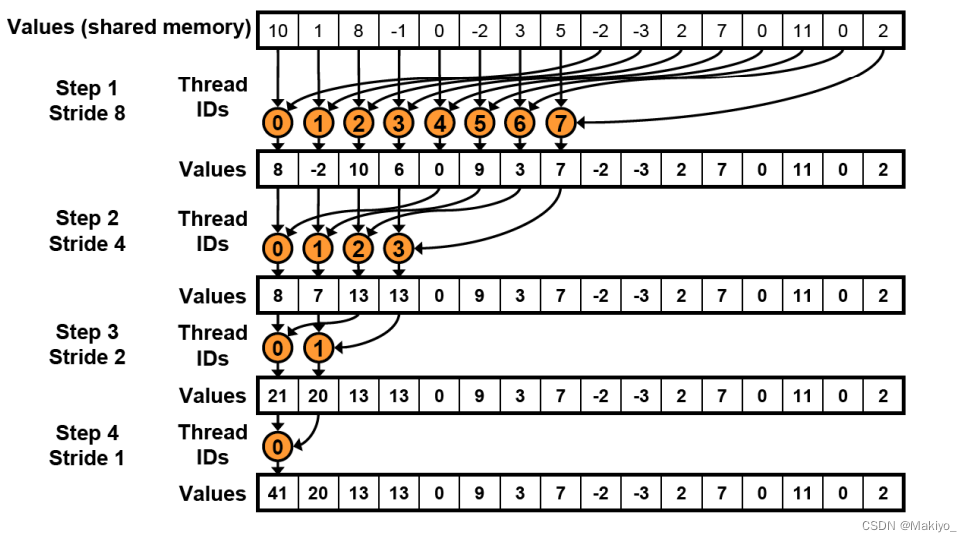
详解:归约有点类似二分思想。初始现在我们有16线程块,假设每个线程块内有16个线程,我们需要处理一个包含16*16个元素的数组。我们的思路是让每个线程块处理16个元素求和,这样16个线程块就可以获得16个和,再把这16个和相加即为该数组所有元素和。
先看一个线程块内16个数组元素求和,因为归约类似二分,是两两合一,不断循环,最后合并到只剩一个元素。因此我们第一轮合并后显然会剩下8个元素,那么第一轮合并我们可以选择步长为16/2=8,也就是让arr[0]和arr[8]合一,arr[1]和arr[9]合一,以此类推。第一轮过后我们会得到8个元素,所以第二轮我们应该会得到4个元素,因此我们第二轮合并选择步长为8/2=4,也就是让arr[0]和arr[4]合一,以此类推。最终一个线程块会得到一个元素,16个线程块会得到16个元素,再将这16个元素继续归约,最终即可求得所有数组元素之和。
⭐️通过采用归并操作,可以大幅优化计算。
//使用全局内存实现归约
_global__ void global_reduce_kernel(float * d_out, float * d_in)
{
int myId = threadIdx.x + blockDim.x * blockIdx.x;
int tid = threadIdx.x;
// do reduction in global mem
for (unsigned int s = blockDim.x / 2; s > 0; s >>= 1)
{
if (tid < s)
{
d_in[myId] += d_in[myId + s];
}
__syncthreads(); // make sure all adds at one stage are done!
}
// only thread 0 writes result for this block back to global mem
if (tid == 0)
{
d_out[blockIdx.x] = d_in[myId];
}
}
//使用共享内存实现归约
__global__ void shmem_reduce_kernel(float * d_out, const float * d_in)
{
// sdata is allocated in the kernel call: 3rd arg to <<<b, t, shmem>>>
extern __shared__ float sdata[];
int myId = threadIdx.x + blockDim.x * blockIdx.x;
int tid = threadIdx.x;
// load shared mem from global mem
sdata[tid] = d_in[myId];
__syncthreads(); // make sure entire block is loaded!
// do reduction in shared mem
for (unsigned int s = blockDim.x / 2; s > 0; s >>= 1)
{
if (tid < s)
{
sdata[tid] += sdata[tid + s];
}
__syncthreads(); // make sure all adds at one stage are done!
}
// only thread 0 writes result for this block back to global mem
if (tid == 0)
{
d_out[blockIdx.x] = sdata[0];
}
}并行化高效策略(二)--扫描scan
🌟扫描Scan:在CUDA编程中,扫描操作可以帮助将一个数组转换成它的前缀和数组,或者执行其他类似的累积计算。扫描操作的核心思想是将一个数组中的每个元素与其前面所有元素的和或其他累积运算结果关联起来。在串行算法中,这通常是通过迭代计算来完成的,但在并行计算中,我们希望能够利用多个线程并行处理数组的不同部分,以提高计算效率。
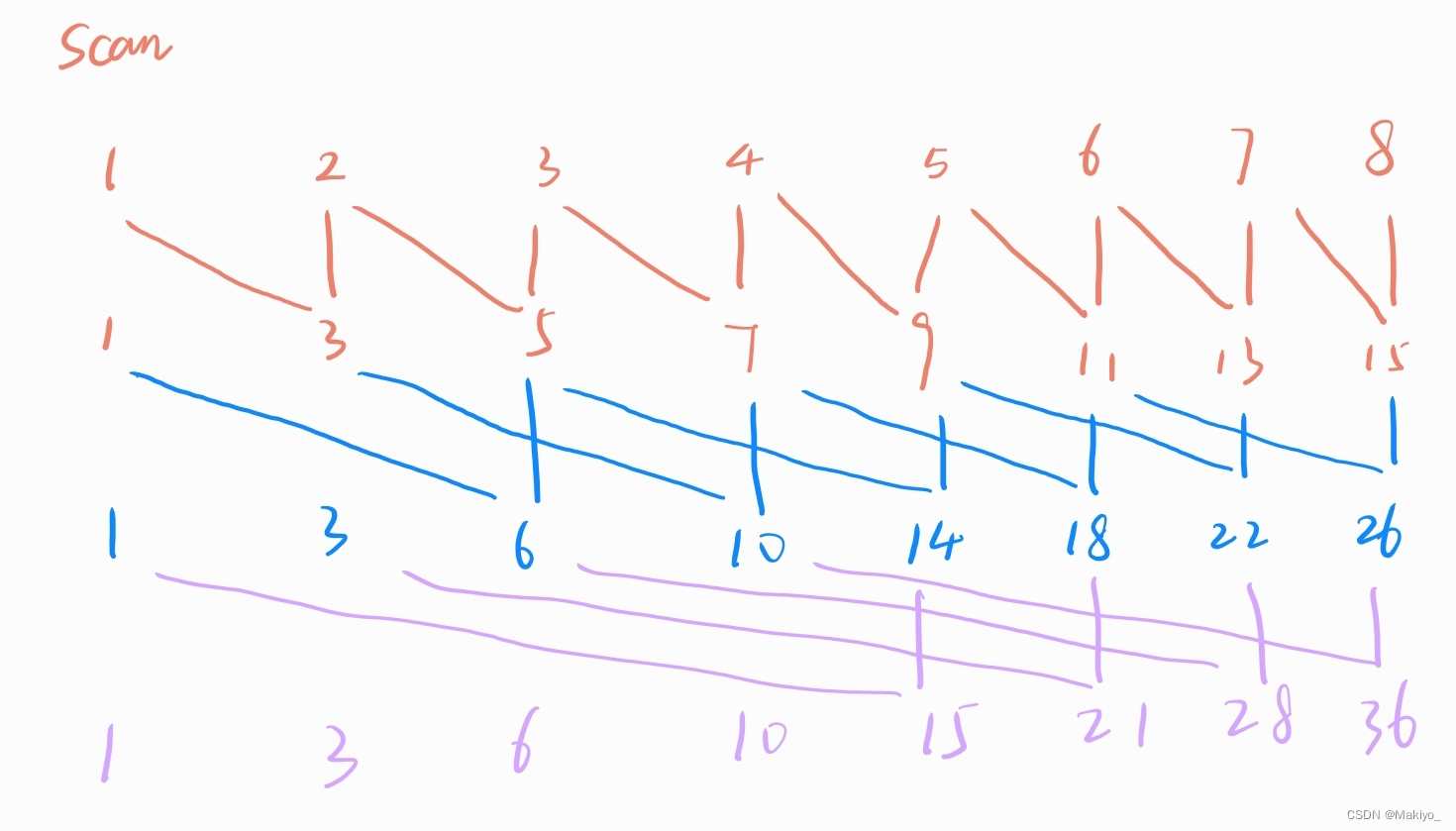
详解:假设初试时有一个8元素数组,我们的迭代次数满足2^n=k(数组元素个数,不足则向上取整),在该例子中,从左向右扫描,使用当前idx元素与idx-2^temp(temp = 2^(当前迭代次数-1))元素相加,当idx小于2^temp时,即退出循环。
#include<stdio.h>
//在全局内存上实现
__global__ void global_scan(float* d_out,float* d_in){
int idx = threadIdx.x;
float out = 0.00f;
d_out[idx] = d_in[idx];
__syncthreads();
for(int interpre=1;interpre<sizeof(d_in);interpre*=2){
if(idx-interpre>=0){
out = d_out[idx]+d_out[idx-interpre];
}
__syncthreads();
if(idx-interpre>=0){
d_out[idx] = out;
out = 0.00f;
}
}
}
//在共享内存上实现
__global__ void shared_scan(float* d_out, float* d_in, int n) {
extern __shared__ float sdata[];
int idx = threadIdx.x;
float out = 0.00f;
if (idx < n) {
sdata[idx] = d_in[idx];
}
__syncthreads();
for (int interpre = 1; interpre < n; interpre *= 2) {
if (idx - interpre >= 0 && idx < n) {
out = sdata[idx] + sdata[idx - interpre];
}
__syncthreads();
if (idx - interpre >= 0 && idx < n) {
sdata[idx] = out;
out = 0.00f;
}
__syncthreads();
}
if (idx < n) {
d_out[idx] = sdata[idx];
}
}
int main(){
const int array_size = 8;
const int array_bytes = array_size * sizeof(float);
//generate the input array on host
float h_in[array_size];
for (int i = 0; i < array_size; i++)
{
/* code */
h_in[i] = float(i+1);
}
//define the output array on host
float h_out[array_size];
// declare GPU memory pointers
float* d_in;
float* d_out;
//allocate GPU Memory
cudaMalloc((void**)&d_in,array_bytes);
cudaMalloc((void**)&d_out,array_bytes);
//transfer the array to GPU
cudaMemcpy(d_in,h_in,array_bytes,cudaMemcpyHostToDevice);
//launch the kernel
shared_scan<<<1,array_size,array_bytes>>>(d_out,d_in,array_size);
//copy back the result array to GPU
cudaMemcpy(h_out,d_out,array_bytes,cudaMemcpyDeviceToHost);
//print result array
for (int i = 0; i < array_size; i++)
{
/* code */
printf("%f\n",h_out[i]);
}
//free GPU memory allocation
cudaFree(d_in);
cudaFree(d_out);
return 0;
}