如果你今天的工作是从竞争对手的网站上抓取定价页面信息。你会怎么做?复制粘贴?手动输入数据?当然不行!他们绝对会花费你超级多的时间,而且你可能会犯一些错误。
需要指出的是,Python已经成为最流行的数据抓取编程语言之一,它到底有什么魅力呢?
什么是网页抓取?
网页抓取是从网站提取数据的过程。这可以手动完成,但最好使用一些自动化工具或脚本来高效准确地收集大量数据。从网页复制和粘贴实际上也是进行网页抓取。
为什么使用 Python 进行网页抓取?
Python 被认为是网页抓取的最佳选择之一,原因如下:
- 易于使用:由于清晰和直观,即使是初学者也可以使用 Python。
- 强大的库:Python 拥有丰富的库系统,例如 Beautiful Soup、Scrapy 和 Selenium,可简化网络抓取任务。
- 社区支持:Python 拥有庞大而活跃的社区,为故障排除和学习提供了丰富的资源和支持。
Python Web 抓取路线图
您准备好开始使用 Python 进行网页抓取了吗?在弄清楚基本步骤之前,请确保您知道会发生什么以及如何进行。
掌握网页抓取的基本步骤
网络抓取涉及一个系统的过程,包括四个主要任务:
1. 检查目标页面
在提取数据之前,您需要了解网站的布局和数据结构:
- 探索网站
- 分析 HTML 元素
- 识别关键数据
2. 检索 HTML 内容
要抓取一个网站,首先需要访问它的 HTML 内容:
- 使用 HTTP 客户端库
- 发出 HTTP GET 请求
- 验证 HTML 检索
3.从 HTML 中提取数据
获得 HTML 后,下一步就是提取所需的信息:
- 解析 HTML 内容
- 选择相关数据
- 编写提取逻辑
- 处理多个页面
4. 存储提取的数据
提取数据后,将其存储为可访问的格式至关重要:
- 转换数据格式
- 导出数据
提示:网站是动态的,因此请定期检查和更新您的抓取过程以保持数据是最新的。
网页抓取用例
Python 网页抓取可以应用于多种场景,包括:
- 竞争对手分析:通过收集网站数据监控竞争对手的产品、服务和营销策略。
- 价格比较:收集并比较不同电子商务平台的价格,以找到最优惠的价格。
- 社交媒体分析:从社交媒体平台检索数据,以分析特定标签、关键词或影响者的受欢迎程度和参与度。
- 潜在客户生成:从网站提取联系方式,创建有针对性的营销列表,同时考虑法律因素。
- 情感分析:收集新闻和社交媒体帖子以追踪某个主题或品牌的公众观点。
克服网络爬取挑战
网络抓取有其自身的一系列挑战:
- 多样化的网站结构:每个网站都有独特的布局,需要自定义的抓取脚本。
- 更改网页:网站可能会在未经通知的情况下更改其结构,因此需要调整您的抓取逻辑。
- 可扩展性问题:随着数据量的增加,请确保您的抓取工具使用分布式系统、并行抓取或优化代码保持高效。
此外,网站还采用了 IP 封锁、JavaScript 挑战和 CAPTCHA 等反机器人措施。这些措施可以通过轮换代理和无头浏览器等技术来规避。
陷入网络抓取困境?
绕过反机器人检测,简化网络抓取和自动化
免费试用 Nstbrowser!
网页抓取的替代方案
虽然网页抓取功能多样,但也有其他选择:
- API:一些网站提供 API 来请求和检索数据。API 很稳定,通常不受抓取保护,但它们提供的数据有限,而且并非所有网站都提供它们。
- 即用型数据集:在线购买数据集是另一种选择,尽管它们可能并不总是能满足您的特定需求。
尽管存在这些替代方案,网络抓取由于其灵活性和全面的数据访问能力仍然是一种流行的选择。
使用 Python 踏上您的网络抓取之旅,释放在线数据的巨大潜力!
如何使用 Python 和 Selenium 进行网页抓取?
步骤 1. 前提
首先,我们需要安装我们的shell:
pip install selenium requests json安装完成后请新建scraping.py文件并在文件中引入我们刚刚安装的库:
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By步骤2. 连接到Nstbrowser
为了进行准确的演示,我们将使用 Nstbrowser(一款完全免费的反检测浏览器)作为完成我们任务的工具:
def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'xxxxxxx' # your api-key
config = {
'once': True,
'headless': False, # headless
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # required
'name': 'custom browser',
'platform': 'windows', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '120',
'hardwareConcurrency': 4, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # support: 2, 4, 8
'proxy': '', # input format: schema://user:password@host:port eg: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # required
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
print('devtool url: ' + url)
port = get_debugger_port(url)
debugger_address = f'{host}:{port}'
print("debugger_address: " + debugger_address)连接到Nstbrowser之后,我们通过Nstbrowser返回给我们的调试器地址连接到Selenium:
def exec_selenium(debugger_address: str):
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", debugger_address)
# Replace with the corresponding version of WebDriver path.
chrome_driver_path = r'./chromedriver' # your chrome driver path
service = ChromeService(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service=service, options=options)步骤 3. 抓取网页
至此,我们已经成功通过 Selenium 启动了 Nstbrowser。现在开始抓取吧!
- 访问我们的目标网站,例如:IMDb Top 250 Movies
driver.get("https://www.imdb.com/chart/top")- 运行我们刚刚写的代码:
python scraping.py如您所见,我们成功启动了 Nstbrowser 并访问了目标网站。
- 打开Devtool可以看到我们想要爬取的具体信息,没错,显然都是具有相同dom结构的元素。
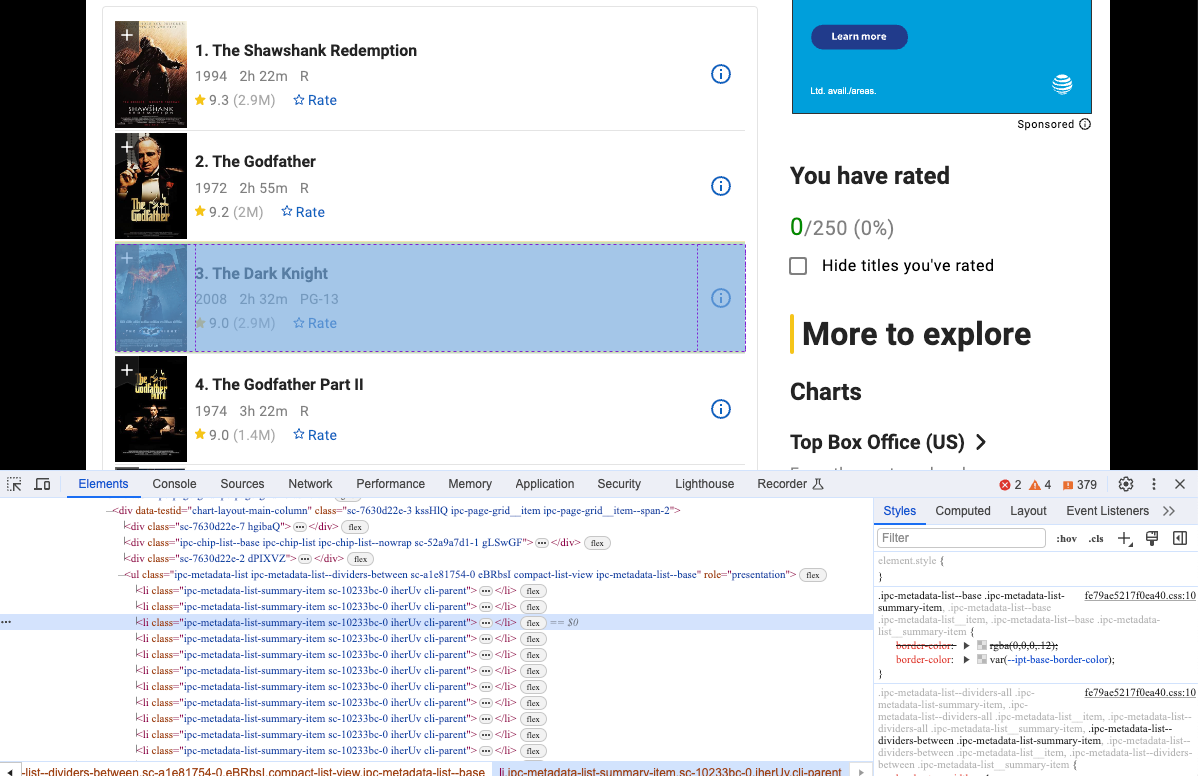
我们可以使用Selenium来获取这种dom结构,并分析其内容:
movies = driver.find_elements(By.CSS_SELECTOR, "li.cli-parent")
for row in movies:
title = row.find_element(By.CLASS_NAME, 'ipc-title-link-wrapper') # get title
year = row.find_element(By.CSS_SELECTOR, 'span.cli-title-metadata-item') # get created year
rate = row.find_element(By.CLASS_NAME, 'ipc-rating-star') # get rate
move_item = {
"title": title.text,
"year": year.text,
"rate": rate.text
}
print(move_item)- 再次运行我们的代码,可以看到终端已经输出了我们想要获取的信息。
当然,在终端输出这些信息并不是我们的目的,接下来我们需要将爬取到的数据保存起来。
我们使用 JSON 库将检索到的数据保存到 JSON 文件:
movies = driver.find_elements(By.CSS_SELECTOR, "li.cli-parent")
movies_info = []
for row in movies:
title = row.find_element(By.CLASS_NAME, 'ipc-title-link-wrapper')
year = row.find_element(By.CSS_SELECTOR, 'span.cli-title-metadata-item')
rate = row.find_element(By.CLASS_NAME, 'ipc-rating-star')
move_item = {
"title": title.text,
"year": year.text,
"rate": rate.text
}
movies_info.append(move_item)
# create the json file
json_file = open("movies.json", "w")
# convert movies_info to JSON
json.dump(movies_info, json_file)
# release the file resources
json_file.close()- 运行代码,打开文件,可以看到 scraping.py 旁边多了一个 movies.json,这意味着我们成功使用 Selenium 连接 Nstbrowser,并抓取到了目标网站的数据!
总结
如何使用 Python 和 Selenium 进行网页抓取?本详细教程涵盖了您正在寻找的所有内容。为了全面了解,我们讨论了 Python 用于网页抓取的概念和优势。然后,以免费的反检测浏览器 - Nstbrowser 为例,介绍具体步骤。我相信您现在已经学到了很多有关 Python 网页抓取的知识!是时候操作您的项目并收集数据了。