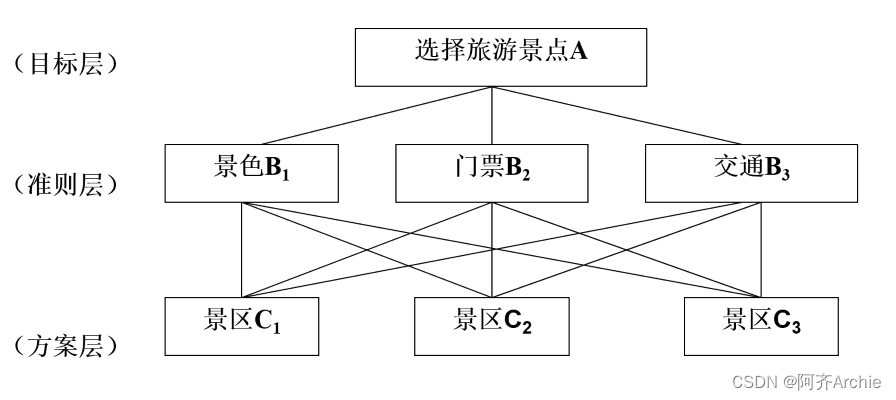
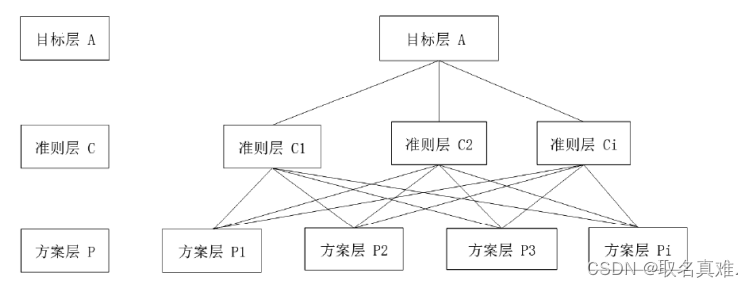
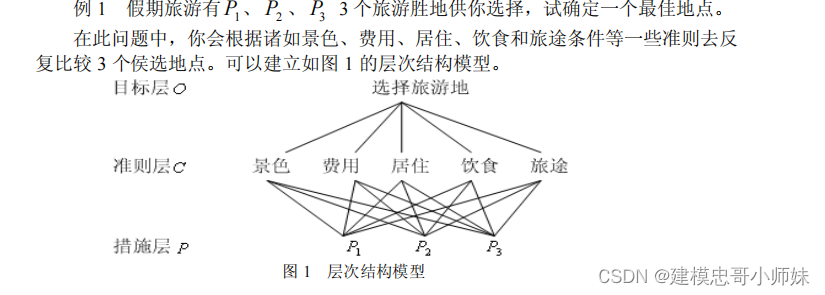
层次分析法(Analytic Hierarchy Process,简称AHP)是一种多准则决策分析方法,由美国运筹学家托马斯·L·萨蒂(Thomas L. Saaty)在20世纪70年代提出。这种方法主要用于解决复杂的决策问题,通过建立层次结构模型,将决策问题分解为多个层次和要素,然后通过成对比较的方式确定各要素的相对重要性,最后进行综合评价和决策。
层次分析法的基本步骤如下:
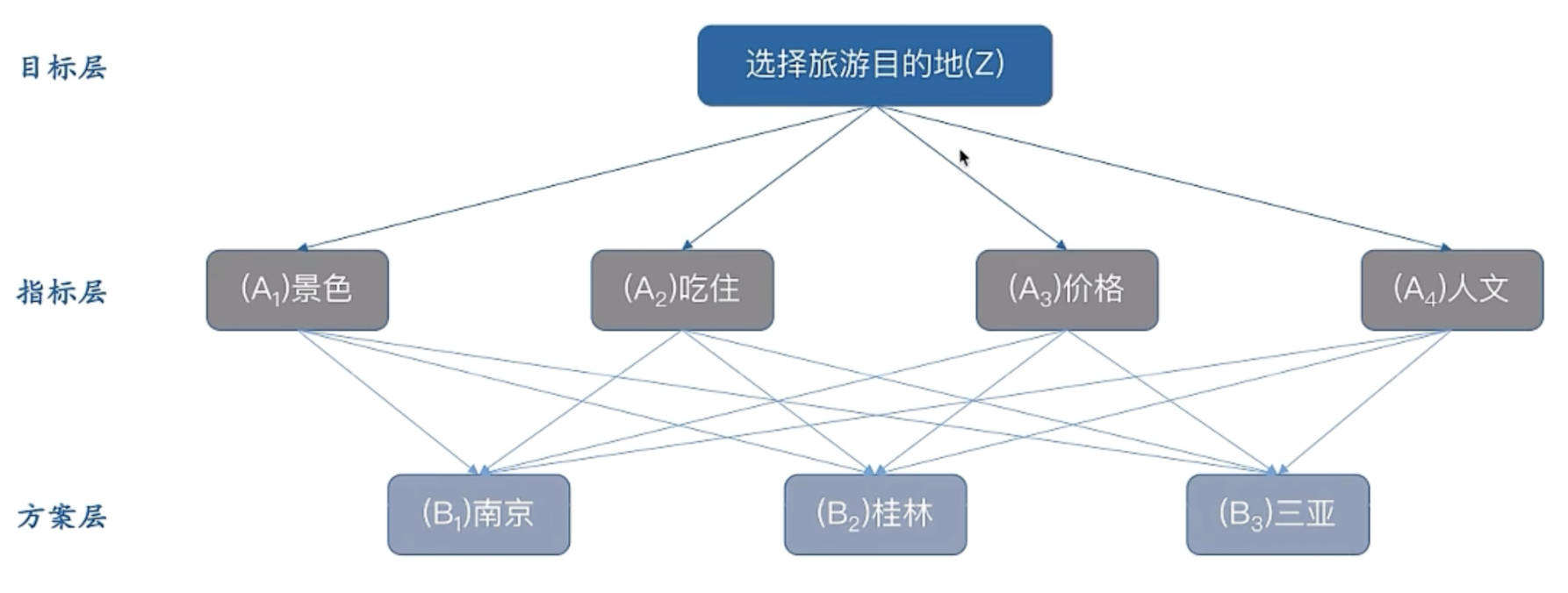
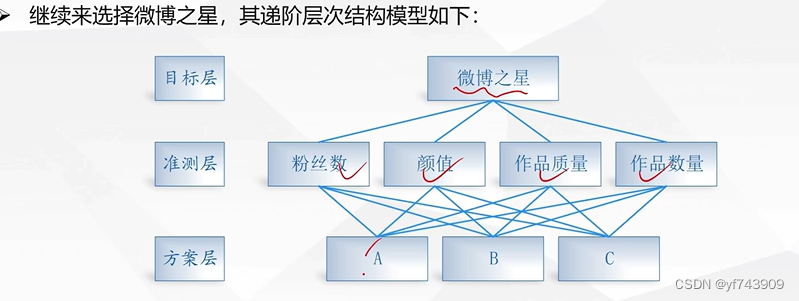
- 建立层次结构模型:将决策问题分解为目标层、准则层和方案层三个层次。目标层是决策的最终目的,准则层是影响决策的因素,方案层是具体的备选方案。
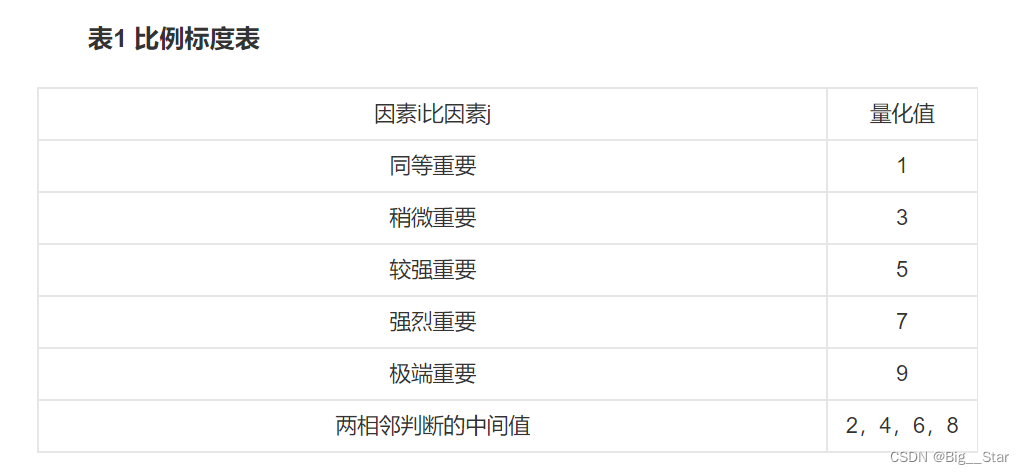
- 构造判断矩阵:在准则层和方案层,通过成对比较的方式,确定各要素之间的相对重要性。通常使用1-9标度来表示两要素的重要性,1表示两个要素同等重要,9表示一个要素比另一个要素重要得多。
- 计算权重:通过判断矩阵,计算出准则层或方案层各要素的权重。这通常涉及到特征值和特征向量的计算。
- 一致性检验:为了保证判断的合理性,需要对判断矩阵进行一致性检验。如果一致性比率(Consistency Ratio,
CR)小于0.1,则认为判断矩阵的一致性是可接受的。 - 合成总排序:将准则层的权重与方案层的权重进行合成,得到每个方案对目标层的总权重,即综合得分。
- 方案排序与选择:根据综合得分对方案进行排序,选择得分最高的方案作为最终决策。
- 优点:在于其结构化和系统化的决策过程,能够处理多准则和多目标的复杂问题。同时,通过成对比较,可以更直观地表达决策者对各要素重要性的判断。
- 局限:比如成对比较可能受到主观判断的影响,一致性检验可能过于严格等。在实际应用中,需要根据具体情况灵活运用。

基本原理
层次分析法根据问题的性质和要达到的总目标,将问题分解为不同的组成因素,并按照因素间的相互关联影响以及隶属关系将因素按不同层次聚集组合,形成一个多层次的分析结构模型,从而最终使问题归结为最低层(供决策的方案、措施等)相对于最高层(总目标)的相对重要权值的确定或相对优劣次序的排定。

小型案例
假设你是一位项目经理,需要从四个备选方案中选择一个最佳方案来改进公司的产品质量。这四个方案分别是:A、B、C和D。


判断矩阵的含义


应用场景
- 项目管理:在项目选择、资源分配、风险评估和项目优先级确定等方面使用AHP来做出决策。
- 供应链管理:评估供应商选择、物流优化、库存管理和供应链风险管理。
- 人力资源管理:在招聘过程中,评估候选人的不同资质和经验,或者在员工绩效评估和晋升决策中使用。
- 财务分析:用于投资决策、资产评估、财务风险管理和预算分配。
- 政策制定:在公共政策制定过程中,评估不同政策选项的优劣和影响。
- 城市规划:在城市规划和发展决策中,考虑环境、经济和社会因素。
- 教育领域:用于课程开发、教育政策制定、学校评价和教师评估。
- 医疗保健:在医疗设备选择、治疗方案评估、医院管理等方面应用。
- 环境管理:评估环境影响、环境风险和可持续发展策略。
- 研发管理:在新产品开发、技术选择和研发资源分配中使用。
- 市场研究:分析市场趋势、消费者行为和竞争对手策略。
- 信息技术:在IT项目选择、系统开发和网络安全评估中使用。
- 交通规划:评估交通基础设施投资、交通模式选择和交通管理策略。
- 能源管理:在能源选择、可再生能源项目评估和能源政策制定中应用。
- 危机管理:在紧急情况和灾难响应中,评估不同应对策略的优先级。
相关术语
初始化随机一致性指数(Random Index,简称RI)是一个预先定义的数值,用来衡量一个随机构建的判断矩阵的一致性水平。RI值是针对不同大小的判断矩阵预先计算好的,它反映了如果判断矩阵的元素是随机生成的,那么一致性指数(Consistency Index,简称CI)的期望值。
RI值是固定的数值,对于常见的矩阵大小,一些典型的RI值如下:
- 对于3x3的判断矩阵,RI值通常是0.58。
- 对于4x4的判断矩阵,RI值通常是0.90。
- 对于5x5的判断矩阵,RI值通常是1.12,依此类推。

实现代码
import numpy as np
class AHP:
"""
相关信息的传入和准备
"""
def __init__(self, array):
## 记录矩阵相关信息
self.array = array
## 记录矩阵大小
self.n = array.shape[0]
# 初始化RI值,用于一致性检验
self.RI_list = [0, 0, 0.52, 0.89, 1.12, 1.26, 1.36, 1.41, 1.46, 1.49, 1.52, 1.54, 1.56, 1.58,
1.59]
# 矩阵的特征值和特征向量
self.eig_val, self.eig_vector = np.linalg.eig(self.array)
# 矩阵的最大特征值
self.max_eig_val = np.max(self.eig_val)
# 矩阵最大特征值对应的特征向量
self.max_eig_vector = self.eig_vector[:, np.argmax(self.eig_val)].real
# 矩阵的一致性指标CI
self.CI_val = (self.max_eig_val - self.n) / (self.n - 1)
# 矩阵的一致性比例CR
self.CR_val = self.CI_val / (self.RI_list[self.n - 1])
"""
一致性判断
"""
def test_consist(self):
# 打印矩阵的一致性指标CI和一致性比例CR
print("判断矩阵的CI值为:" + str(self.CI_val))
print("判断矩阵的CR值为:" + str(self.CR_val))
# 进行一致性检验判断
if self.n == 2: # 当只有两个子因素的情况
print("仅包含两个子因素,不存在一致性问题")
else:
if self.CR_val < 0.1: # CR值小于0.1,可以通过一致性检验
print("判断矩阵的CR值为" + str(self.CR_val) + ",通过一致性检验")
return True
else: # CR值大于0.1, 一致性检验不通过
print("判断矩阵的CR值为" + str(self.CR_val) + "未通过一致性检验")
return False
"""
算术平均法求权重
"""
def cal_weight_by_arithmetic_method(self):
# 求矩阵的每列的和
col_sum = np.sum(self.array, axis=0)
# 将判断矩阵按照列归一化
array_normed = self.array / col_sum
# 计算权重向量
array_weight = np.sum(array_normed, axis=1) / self.n
# 打印权重向量
print("算术平均法计算得到的权重向量为:\n", array_weight)
# 返回权重向量的值
return array_weight
"""
几何平均法求权重
"""
def cal_weight__by_geometric_method(self):
# 求矩阵的每列的积
col_product = np.product(self.array, axis=0)
# 将得到的积向量的每个分量进行开n次方
array_power = np.power(col_product, 1 / self.n)
# 将列向量归一化
array_weight = array_power / np.sum(array_power)
# 打印权重向量
print("几何平均法计算得到的权重向量为:\n", array_weight)
# 返回权重向量的值
return array_weight
"""
特征值法求权重
"""
def cal_weight__by_eigenvalue_method(self):
# 将矩阵最大特征值对应的特征向量进行归一化处理就得到了权重
array_weight = self.max_eig_vector / np.sum(self.max_eig_vector)
# 打印权重向量
print("特征值法计算得到的权重向量为:\n", array_weight)
# 返回权重向量的值
return array_weight
if __name__ == "__main__":
# 给出判断矩阵
b = np.array([[1, 1 / 3, 1 / 8], [3, 1, 1 / 3], [8, 3, 1]])
# 算术平均法求权重
weight1 = AHP(b).cal_weight_by_arithmetic_method()
# 几何平均法求权重
weight2 = AHP(b).cal_weight__by_geometric_method()
# 特征值法求权重
weight3 = AHP(b).cal_weight__by_eigenvalue_method()