⭐️我叫忆_恒心,一名喜欢书写博客的研究生👨🎓。
如果觉得本文能帮到您,麻烦点个赞👍呗!
近期会不断在专栏里进行更新讲解博客~~~
有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支持一下呗。👍⭐️❤️
📂Qt5.9专栏定期更新Qt的一些项目Demo
📂项目与比赛专栏定期更新比赛的一些心得,面试项目常被问到的知识点。
欢迎评论 💬点赞👍🏻 收藏 ⭐️加关注+
✍🏻文末可以进行资料和源码获取欧😄
自动化问答系统技术笔记
1. 引言

问答系统(Question Answering, QA)是一类能够自动回答用户提出的问题的系统。它们在自然语言处理(NLP)领域中发挥着重要作用,从简单的问答对到复杂的对话系统,广泛应用于搜索引擎、虚拟助手、客服系统等场景。本文将基于 Kaggle 上的“Question Answering Tutorial”笔记,详细介绍如何构建一个自动化问答系统。
2. 项目概述
构建一个高效的问答系统涉及多个步骤,包括数据预处理、模型选择与训练、模型优化和评估。我们将重点讨论使用 BERT 模型处理问答任务的实现步骤和关键技术。
3. 数据准备

数据是构建问答系统的基础。我们通常使用已标注的数据集进行训练和评估。本项目采用 SQuAD(Stanford Question Answering Dataset)作为数据来源,该数据集包含成千上万个由段落和相关问题组成的问答对。
数据加载和预处理:
import pandas as pd
import json
# 读取数据集
with open('path_to_squad_data.json', 'r') as file:
squad_data = json.load(file)
# 展示数据结构
print(squad_data['data'][0]['paragraphs'][0])
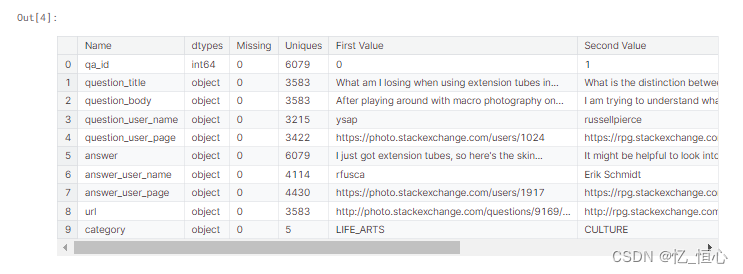
在读取数据后,我们需要进行数据清洗和格式化,确保数据适合输入模型。清洗步骤可能包括去除无效字符、标准化文本格式等。
4. 模型选择
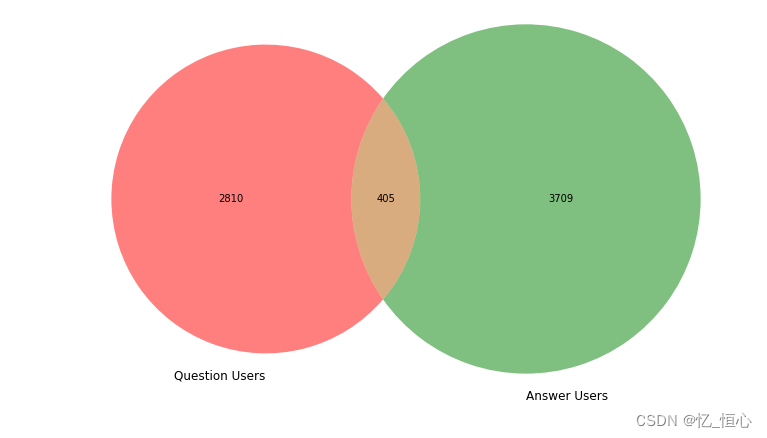
选择合适的模型对于问答系统的性能至关重要。近年来,BERT(Bidirectional Encoder Representations from Transformers)已成为处理问答任务的首选模型。BERT 通过预训练在大规模语料库上,然后微调特定任务,从而在多个 NLP 任务上表现优异。
模型加载与微调:
from transformers import BertTokenizer, BertForQuestionAnswering
import torch
# 加载预训练的BERT模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForQuestionAnswering.from_pretrained('bert-base-uncased')
# 输入样本数据进行编码
question, text = "What is AI?", "Artificial intelligence is a field of study..."
inputs = tokenizer.encode_plus(question, text, return_tensors='pt')
# 模型前向传递
outputs = model(**inputs)
5. 模型训练
在微调过程中,我们会使用训练数据来调整模型的参数,使其更适合特定的问答任务。微调通常包括定义损失函数、选择优化器和设置训练循环等。
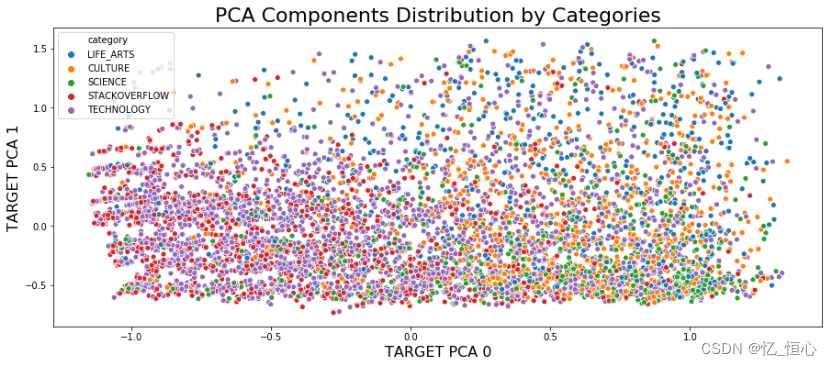
训练过程示例:
from transformers import AdamW
# 定义优化器
optimizer = AdamW(model.parameters(), lr=5e-5)
# 训练循环
for epoch in range(epochs):
model.train()
for batch in train_dataloader:
inputs = tokenizer.encode_plus(batch['question'], batch['text'], return_tensors='pt')
outputs = model(**inputs, start_positions=batch['start_position'], end_positions=batch['end_position'])
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
6. 模型评估
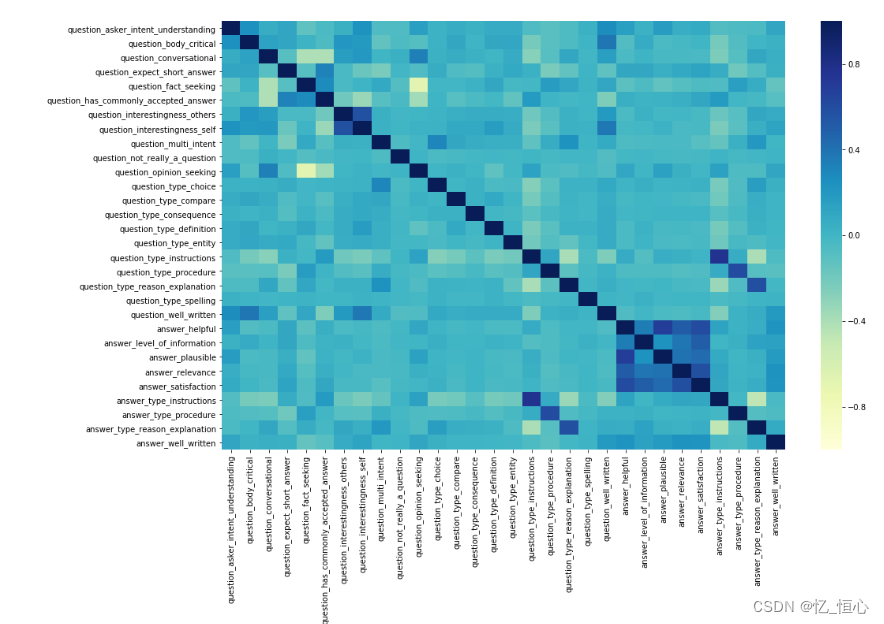
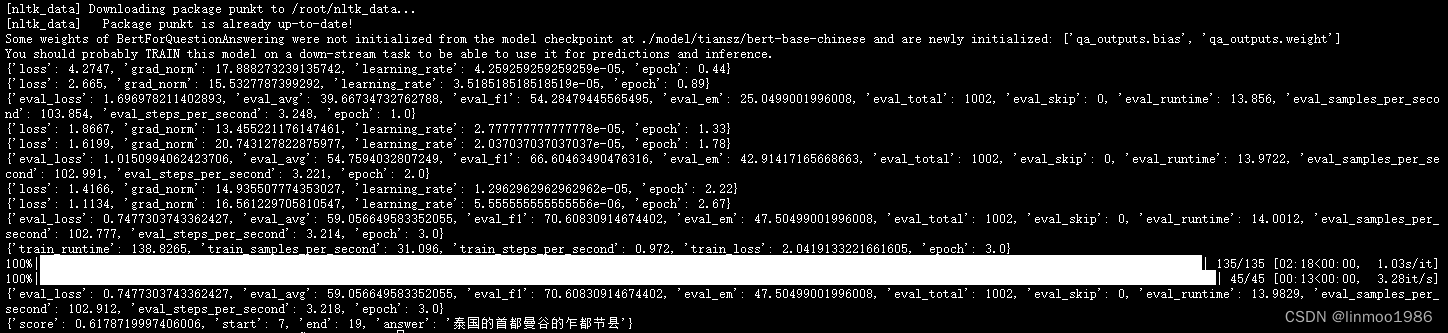
评估模型的性能是确保其能够有效回答问题的关键。我们通常使用准确率、召回率、F1值等指标来衡量模型的表现。此外,还可以通过生成示例答案来直观地检查模型的回答质量。
评估方法:
from sklearn.metrics import f1_score, accuracy_score
# 假设我们有预测的答案和真实的答案
predictions = ["Artificial intelligence is a field of study..."]
true_answers = ["Artificial intelligence is the simulation of human intelligence..."]
# 计算F1值
f1 = f1_score(true_answers, predictions, average='weighted')
print(f'F1 Score: {f1}')
7. 模型优化
在初步训练和评估之后,可能需要进一步优化模型,以提高其在问答任务上的表现。优化策略可以包括调整超参数、使用更大的训练数据集、增加模型的复杂度等。
优化技巧:
- 超参数调整:尝试不同的学习率、批次大小和训练轮数。
- 数据增强:通过数据扩充和增强技术,增加训练数据的多样性。
- 模型集成:结合多个模型的优势,通过集成学习提高性能。
8. 部署与应用
一旦模型经过训练和优化,就可以将其部署到实际应用中,如嵌入到网页、手机应用或客服系统中。部署时需要考虑模型的响应时间、资源消耗和扩展性等因素。
模型部署示例:
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json(force=True)
question, text = data['question'], data['text']
inputs = tokenizer.encode_plus(question, text, return_tensors='pt')
outputs = model(**inputs)
answer_start = torch.argmax(outputs.start_logits)
answer_end = torch.argmax(outputs.end_logits)
answer = tokenizer.decode(inputs.input_ids[0][answer_start:answer_end+1])
return jsonify({'answer': answer})
if __name__ == '__main__':
app.run(debug=True)
9. 总结
构建一个自动化问答系统是一个复杂但极具挑战的任务。通过有效的数据准备、模型选择与微调、模型评估与优化,可以构建出高效的问答系统。在实际应用中,持续的性能监控和改进也是必不可少的。
问答系统的未来发展潜力巨大,随着深度学习技术的进步,我们可以期待更多更智能的系统出现,为人们提供更为便捷和精确的信息服务。
往期优秀文章推荐:
- 研究生入门工具——让你事半功倍的SCI、EI论文写作神器
- 磕磕绊绊的双非硕秋招之路小结
- 研一学习笔记-小白NLP入门学习笔记
- C++ LinuxWebServer 2万7千字的面经长文(上)
- C++Qt5.9学习笔记-事件1.5W字总结
资料、源码获取以及更多粉丝福利,可以关注下方进行获取欧