| 资源地址 |
|---|
| Attention is all you need.pdf(0积分) - CSDN |
第一遍阅读(Abstract + Introduction + Conclusion)
Abstract中强调Transformer摒弃了循环和卷积网络结构,在English-to-German翻译任务中,BLEU得分为28.4, 在English-to-French的翻译任务中的BLEU得分为41.0,用8张GPU训练了3.5天,与各文献中的best models相比,这是非常小的训练成本。
Introduction中对RNN的一些工作做了总结,它说RNN结构本身,在序列长度变长时会产生限制,虽然有些工作通过factorization tricks因式分解和conditional computation对其进行运算效率上的提高,并且后者可以提高模型性能,但是,对于序列处理的最基本的局限性还是存在的。Attention机制已经在许多任务的序列建模和翻译任务中成为了重要的一部分,并且在大多数情况下,Attention机制都会与recurrent network一起使用。
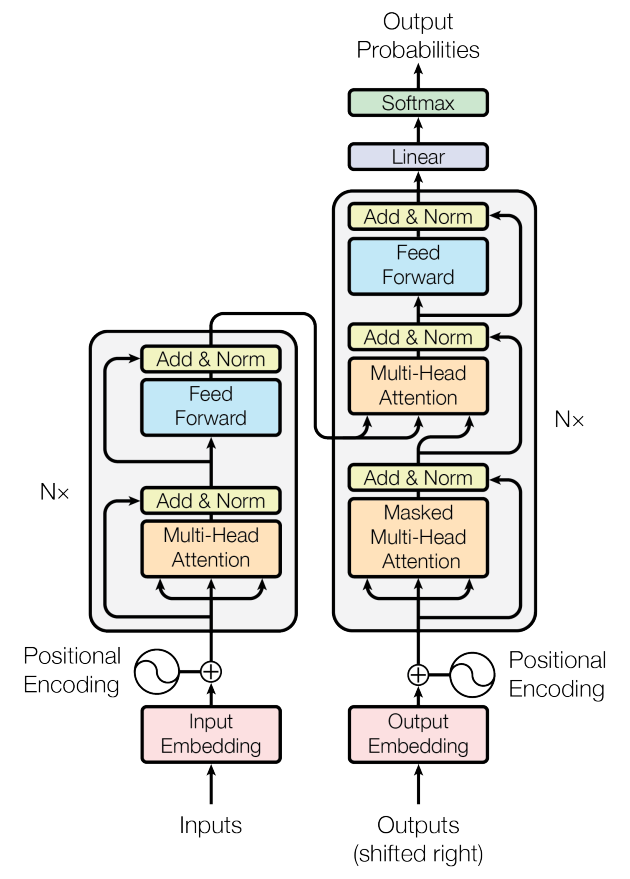
然后作者说,他们提出了一种抛弃recurrent结构,完全使用Attention机制去描述input与output之间的全局关系。Transformer允许更大的并行度,并且在8张P100的GPU上训练了25h后,就在翻译质量上达到了SOTA。
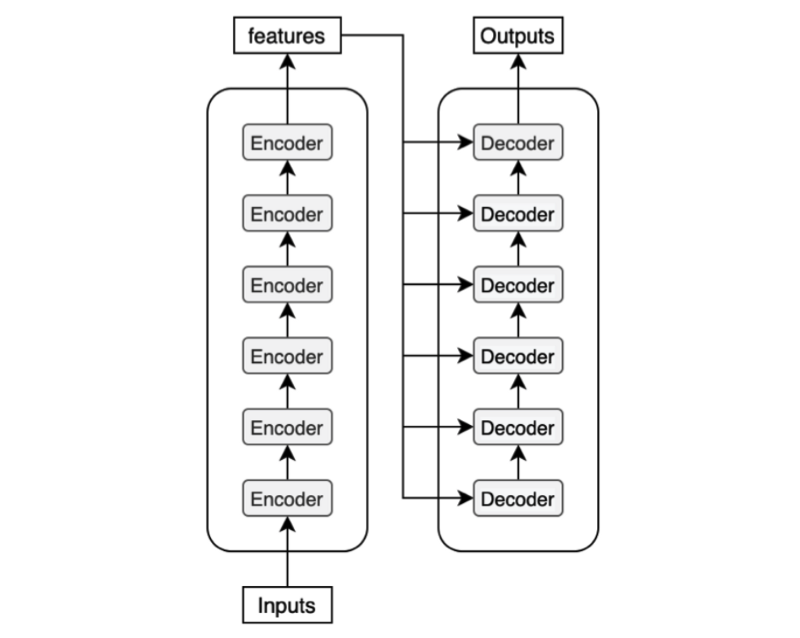
Conclusion说,Transformer将Encoder-Decoder中最常用的recurrent layers替换成了multi-headed self-attention多头自注意力模块。并且作者他们希望将Transformer推广到只要包括input与output特点的问题上去,而不是仅仅局限于text文本(所以将Transformer应用在图片、音视频中是他们展望的应有之意,而不是说Transformer在无意中完成了CV和NLP的跨界大一统,是作者他们原本就想这么做),并且他们还想探索local, restricted attention mechanisms局部的、受限制的注意力机制,让Generation更少一点sequential序列化也是他们的研究目标(我理解这里应该是说让Transformer不是一个词一个词的串行预测,而是可以多个词一起预测出来?或者说不是语句化的串行生成,而是跳跃式的段落篇章式生成?)
| 参考文章或视频资料 |
|---|
| 【【计算机博物志】自然语言处理的“古往”和“今来”】 - bilibili |
























![[LitCTF 2023] Web类题目分享](https://img-blog.csdnimg.cn/575beab224ec4b5fb28d11598aff26c9.png)
![C++多线程学习[四]:多线程的通信和同步、互斥锁、超时锁、共享锁](https://img-blog.csdnimg.cn/direct/b671cc8e11ad4d77b8b518408b4dd028.png)