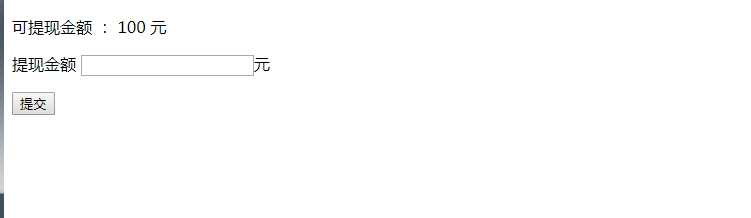文章目录
- 前言
- 一、论坛项目经典话术
- 二、请你介绍一下你最近的项目吧
- 三、你的公司的开发环境是怎么搭建的?
- 四、登录你们是怎么做的?
- 五、用户行为限流是怎么做的?
- 六、续约Token怎么设计的?
- 七、前后端交互是怎么配合的
- 八、你们前端是怎么部署的?
- 九、文章查询流程简单讲一下?
- 十、ThreadLocal在项目中有用到过吗?
- 十一、文章发布流程
- 十二、文章审核流程
- 十三、自媒体文章上下架实现流程讲一下
- 十四、文章搜索流程详细讲一下
- 十五、文章搜索历史是怎么实现的
- 十六、联想词功能你们是这么设计的
- 十七、用户行为数据你们是怎么采集的
- 十八、文章热度你们是怎么计算的
- 十九、你们项目中的持续集成是怎么实现的
- 二十、你们项目是如何部署的
- 二十一、项目部署后如何监控微服务的日志?
- 二十二、点赞、阅读、不喜欢功能如何实现?
- 二十三、文章评论如何实现?
- 二十四、用户评论时携带的IP是怎么查询的?
- 二十五、实名认证是怎么做的?
- 二十六、自媒体图文数据统计怎么做的?
- 二十七、头条项目功能盘点?
- 二十八、头条项目简历编写?
前言
自己学过的项目如何梳理、将每一个项目的核心业务梳理出来,整理成话术。以及发现项目汇总的技术亮点,详细讲解技术亮点的实现思路。
一、论坛项目经典话术
话术:将整个项目的各种业务、技术亮点,进行抽取,编成大白话,覆盖所有的核心业务、各种技术解决方案。真正做到,就算照着念,都可以给面试官讲明白。
解决面试问题:
- 你介绍一下你最近/最熟悉的一个项目经验吧
- XXX技术在这个项目中用到过是吧?
- XX业务遇到XX问题,你们是怎么解决的?
针对自己的项目经验
二、请你介绍一下你最近的项目吧
注意:一定要追求真实,一定要给一个真实背景。
项目三要素:项目介绍、岗位职责、业绩、技术亮点
2.1 话术1
我最近做的这个项目是融媒体项目,准确来讲是一个融媒体平台,项目是我们公司自研的,核心业务就是基于我们公司自好的面试官,有的媒体资源、社群、自媒体资源进行整合。基于我们研发的融媒体平台,构建了多款APP,分别针对不同的客户群体。公司业务规划走的就是融媒体矩阵,每个App项目分别针对不同的类目进行打造,各自做专业垂直类目的AP。说白了就是前端换了个皮肤,垂直类目有母婴、健康、旅游、以及各省市区域进行打造,只要运营需要,随时可以生产出很多APP。
项目的核心就是通过矩阵玩法,聚集不同类目下的用户,每一个项目都是一个垂直类目,吸引不同兴趣爱好的用户,说白了就是养一波铁粉,然后为后期打造私域营销、垂直类目精准客群推荐打好基础,后期公司计划就是走这个广告和垂直类目电商进行营利。
还有就是项目架构,我们首先是将整体系统拆分成多个分布式子系统,比如大数据计算和推荐、平台运营管理系统、还有就是我参与的这个融媒体平台项目。
我主要是负责融媒体平台端的一些功能开发,后台架构是用的微服务,便于业务的扩展和将来部署时动态的管理服务资源。
主要服务的话就是个人中心、文章服务、行为数据服务、任务调度微服务、评论服务、检索服务、自媒体管理服务、平台管理服务、图片管理服务、统一认证服务这些基本业务服务,大概有十几个,大部分服务模块相关的核心业务开发我都参与过,我们公司开发模式的话没有严格的划分具体负责哪些模块,都是根据月度下发的任务进行分配的。
然后业务层,就是每一个微服务的话,我们是用的SpringBoot、RabbitMQ、Elasticsearch这些技术MybatisPlus、Redis、MySOL、还是比较主流的;
我在项目中的话,主要是负责iava后端开发,算是我们小组的主力吧,项目也是做了有一年了,目前已经上线几个APR了主要独立负责的一些核心业务的话就是有用户推荐服务|ava端、个人中心、文章服务、任务调度微服务、评论服务、检索服务、统一认证服务这几个核心模块业务的设计与编码
这个项目我从项目立项那会就参与了,我刚进公司的时候这个项目刚开始做,所以这类型业务也是非常熟悉,当然我主要是做后端开发。
大概就是这个情况,面试官。
三、你的公司的开发环境是怎么搭建的?
我们公司的项目环境有开发环境、测试环境和线上生产环境,测试环境和生产环境是运维搭建的。
然后开发环境是我(如果你包装3年以下就说你组长搭建)搭建的,我们公司内部有专门的开发机,就是一台高性能的服务器,然后我在上面使用 Docker 部署了一些项目开发环境用的东西,比如:Redis、MySQL、Nacos Server端、Sentinel Server端、SkyWalking Server端,还包括一些其他中间件,Elasticsearch、RabbitMQ、XXL-JOB 这些中间件,还有ELK日志平台,这些都是我部署的。
因为开发环境的这个服务器性能足够满足我们日常开发使用,所以就部署在一台服务器上。主要是能够快速的重置、重启就可以了。
至于公司内部项目管理工具、GitLab、公司内部知识库这些不是我搭建的,因为这些都是公司平台自有的。
开发的时候,我们就是连接公司内网的开发机,所有的连接方式、账号信息,我都是写好文档,在公司内部的 wiki 平台上发布了,用的时候,其他同事去参考就行了。如果回家后需要加班的话,我们就配上 VPN 连接公司内部服务器就行了。
四、登录你们是怎么做的?
平台方、媒体端、用户端登录方式是不一样的,平台端和媒体端是支持账号密码、手机验证码登录。
用户端是支持账号密码、手机验证码、微信登录、微博登录多种登录方式。
平台端和媒体端是必须登录后才能使用。
用户端的话,可以匿名访问,但如果要点赞、评论、收藏或者查看个人中心等行为的话,还是需要登录的,App 页面会自动跳出来登录界面。关于登录这块都是我做的,我给您挨个说一下吧
4.1 账号密码登录
我们首先设计了用户表,用户表中包含了用户的账号、密码、手机号、头像、注册时间、是否身份认证这些字段。
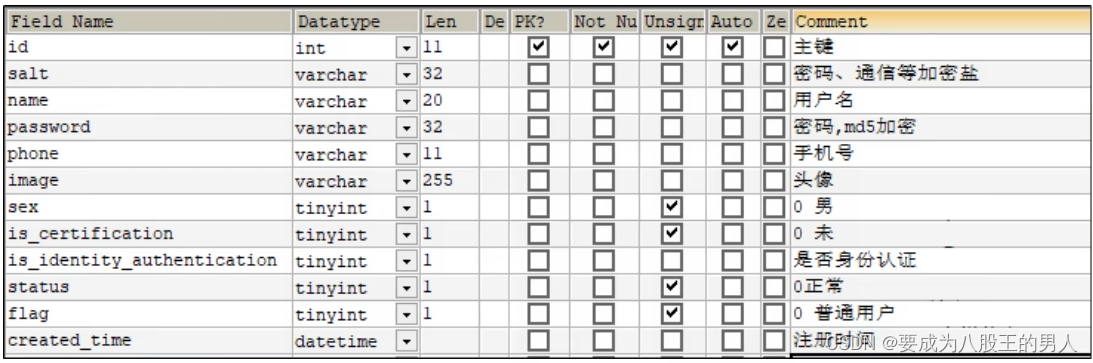
当前端提交请求时,请求体中以 JSON 形式提交账号、密码、验证码这几个参数。请求先到后端 gateway 网关,网关处判断登录请求时不需要校验 Token 的,所以直接放行请求被转发到 user 用户服务这里,流程也很简单,先针对参数进行校验,非空、是否合法如果参数有问题,则直接返回登录失败信息。如果参数没问题,就判断一下账号密码是否频繁登录,这里我是借助redis 的 zset数据结构设计了一个时间窗口限流算法实现的。
如果没有限流,就查询用户数据,用户是否存在,如果不存在就返回登录失败。如果存在,就校验密码,我们是使用加随机盐的一个工具类 BCrypt 实现的,它的安全度更高。如果密码校验通过,就封装用户数据,比如用户名、用户头像,封装到JWT Token 的载荷中,返回给前端就可以了。
以后前端就带着这个 Token 访问其他资源。当然了,我在网关处,针对 Token 进行校验,比如访问受限资源,需要判断是否有 Token,判断 Token 是否有效,如果 Token 没问题,就将请求放给后面的微服务。
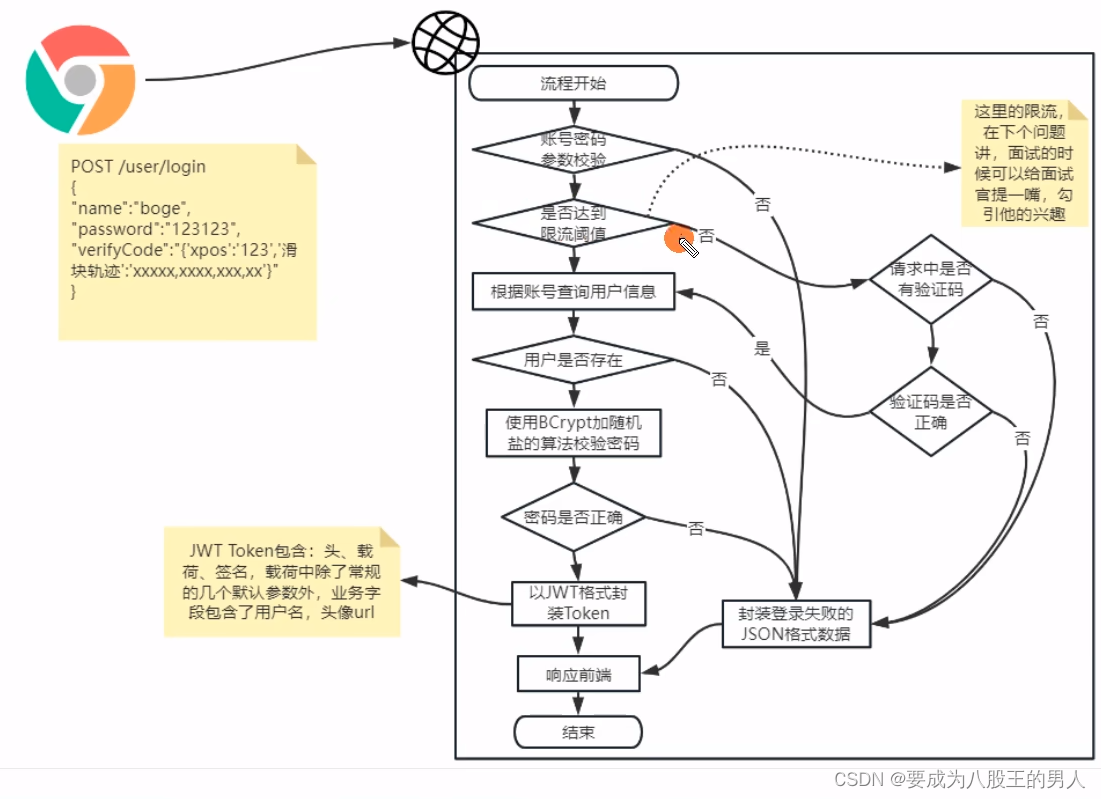
4.2 手机验证码发送
这个流程主要涉及的到3个接口,分别是:
- 手机验证码发送接口,在common通用服务中
- 滑块验证码接口,在common通用服务中
- 手机验证码登录流程,在user通用服务中
4.2.1 手机验证码发送
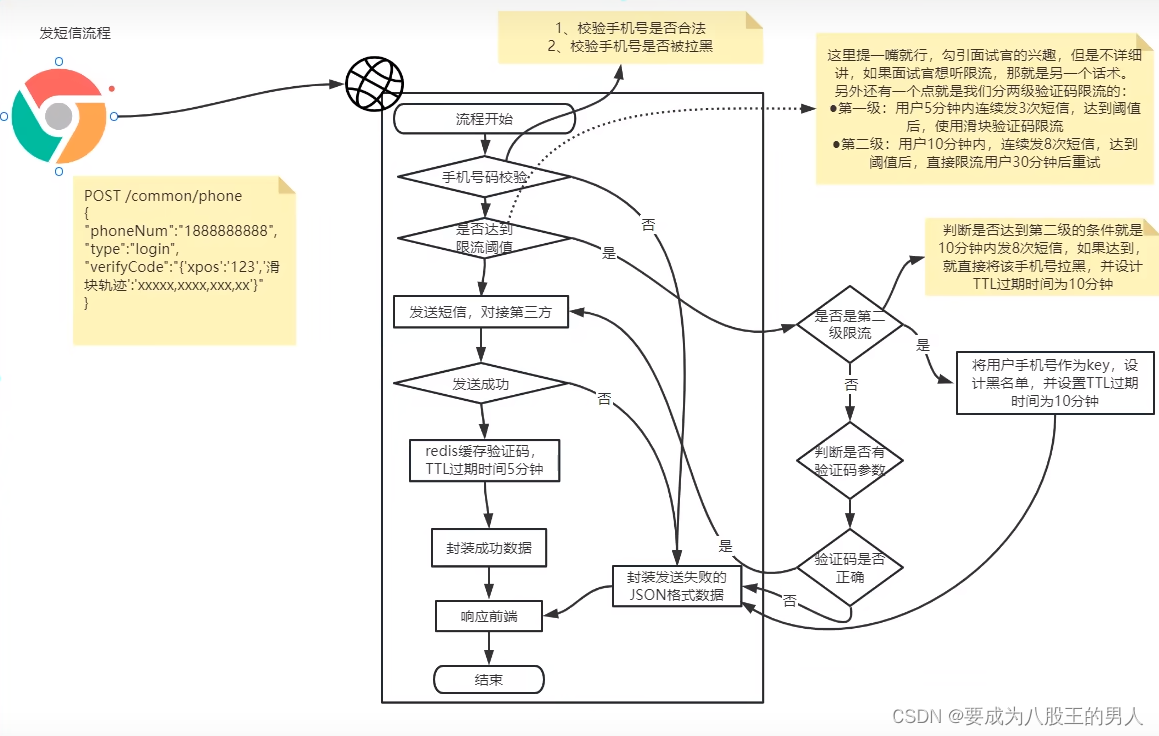
首先用户在页面填写手机号码,前端校验手机号没有问题,就会自动向后端【发送登录短信)接口发起请求。
我们是设计了一个 common 服务,就是封装了一些通用功能的服务,将发短信、OSS 对象存储这些通用功能都放到这个通用服务中实现。
限流的条件是满足 5 分钟内发生3次发短信行为,就判定进行限流。如果没有达到限流阈值,我们直接调用三方的短信服务,发送短信。短信发送成功后,我就把短信验证码,缓存到 Redis 中,过期时间 TTL 设置为默认 5 分钟当然这些时间配置什么的,我们都使用统一的配置文件管理了,可以动态修改的。缓存在 Redis 中的 key 的格式为:USER:LOGIN:手机号值就是验证码的随机值。最后响应前端短信发送成功。
另外还有一个点就是限流的细节,我给您讲一下,我们分两级验证码限流的:第一级:用户5分钟内连续发3次短信,达到值后,使用滑块验证码限流,查询请求参数中是否携带滑块验证码参数,如果有,就查询redis 中的验证码,比对前端提交的这个参数是否正确,如果正确,就直接放过去。
第二级:用户 10 分钟内,连续发8次短信,达到值后,直接限流用户 10分钟后重试实现方式就是将用户拉黑,把用户的手机号设计为 key,比如:BLACK:LOGIN:手机号TTL 过期时间设置为 10 分钟,这样用户下次请求时,直接判断这个手机号是否在黑名单如果在的话直接就拒绝了。10 分钟后自然会过期,就又恢复正常发送短信了
4.2.2 手机验证码登录
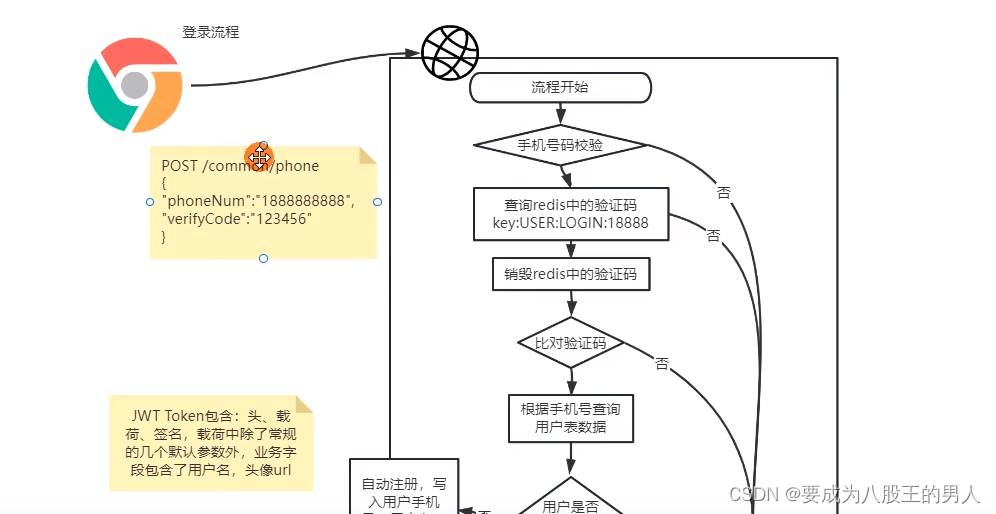
首先是前端提交登录登录表单,包含手机号、验证码。
后端接收到请求后,先校验一下手机号是否合法。
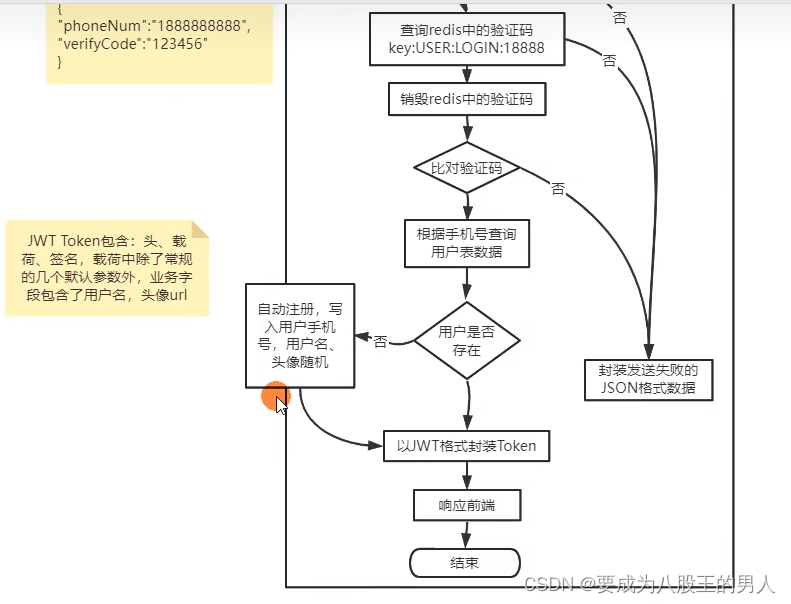
然后根据手机号,查询 Redis 中缓存的真实验证码,查询完毕后销毁掉 redis 中的验证码.比对验证码是否正确,如果验证码不存在,或者验证码错误,那就直接返回前端失败信息。如果验证码正确,就根据手机号查询用户表中用户数据,如果用户存在,就以JWT格式封装用户 Token,返回给前端。
如果用户不存在,也没关系,直接默认自动注册,写入用户的手机号,关于用户名和头像用默认值代替。
用户自己可以在个人中心中,修改用户名、头像、密码等数据。
五、用户行为限流是怎么做的?
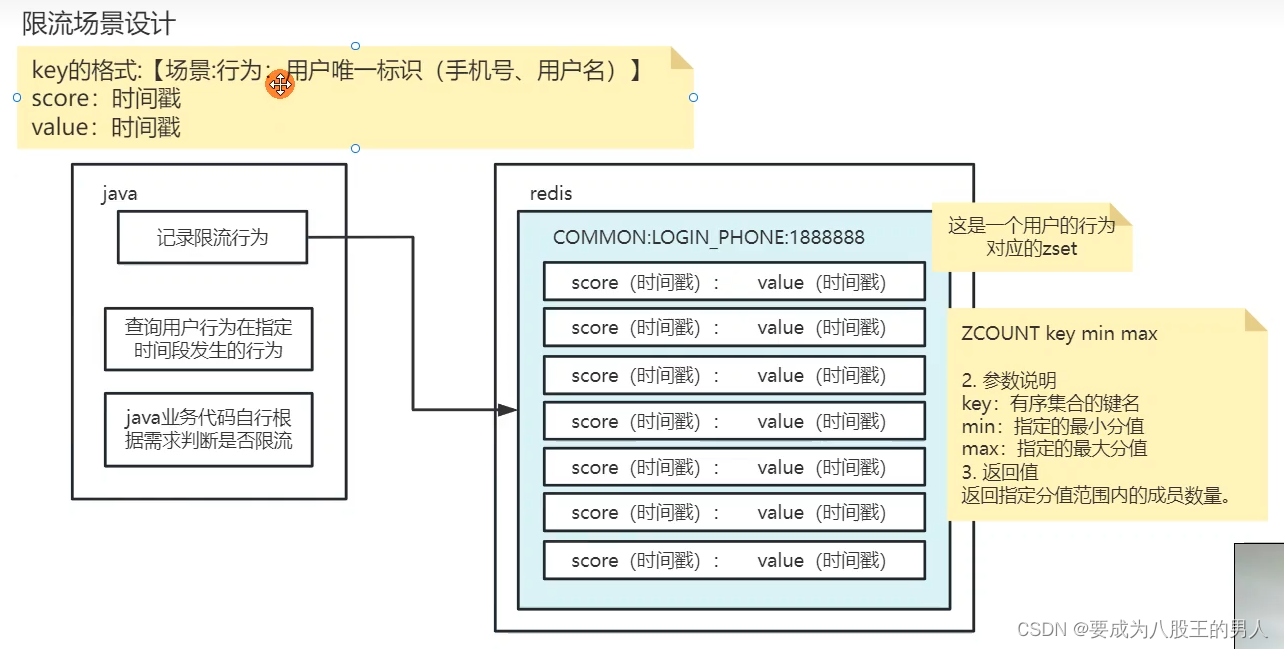
有的,这个必须做限流,我是利用redis 的 zset 结合时间窗口限流算法进行实现的。我们是这样考虑的,用户可能有很多行为,是无意义,或者非法的,比如:频繁发送短信、频繁修改个人信息、频繁的点赞、评论等等行为,都应该进行限流。所以我就针对这些频繁的行为进行限流,设计了一个通用的限流接口。思路上是使用时间窗口限流算法,具体实现我利用 redis 的 zset 进行实现。比如说,用户5分钟内只能发送3个验证码,或者 10分钟内只能发送8个验证码,于是我就将用户发短信的行为设计为 key,格式为【场景:行为:用户唯一标识(可以是手机号、用户名)】,score 分数值是时间戳,value值也是时间戳。
限流算法思路:

具体流程:
- 当用户每次发生限流行为,都会记录这个行为,以Redis zset的方式进行记录。
- 在业务处理流程中,使用java api进行查询判断,其实本质就是调用redis 的zcount命令,这个命令可以传入起始分值和结束分值。我就把当前时间戳作为结束分值,然后当前时间戳减去限流时间,比如说5分钟的毫秒值,求出来5分钟前的时间戳。于是根据这两个时间戳作为分值,范围查询 zset中出现的次数,就得到用户在5分钟内,这个行为一共触发了几次。
- 后续的业务,就是不同场景中,根据不同的需求,进行校验就行了,比如说5分钟限流3次,10 分钟限流8次,这就是后面的业务代码考虑的事情了。
六、续约Token怎么设计的?
这个续约 token 在我们的项目中有设计过,恰好也是我做的。当时产品经理给到的需求是,要求用户可以保持一个长期登录或者自动登录的效果。避免用户状态频繁过期,频繁登录给用户带来不便我当时就使用双 Token 的方式进行设计的,这种方案提出来后是经过组长评估的,他也认为没问题,于是我就这么做了。
我给您说下我的大概实现思路吧。
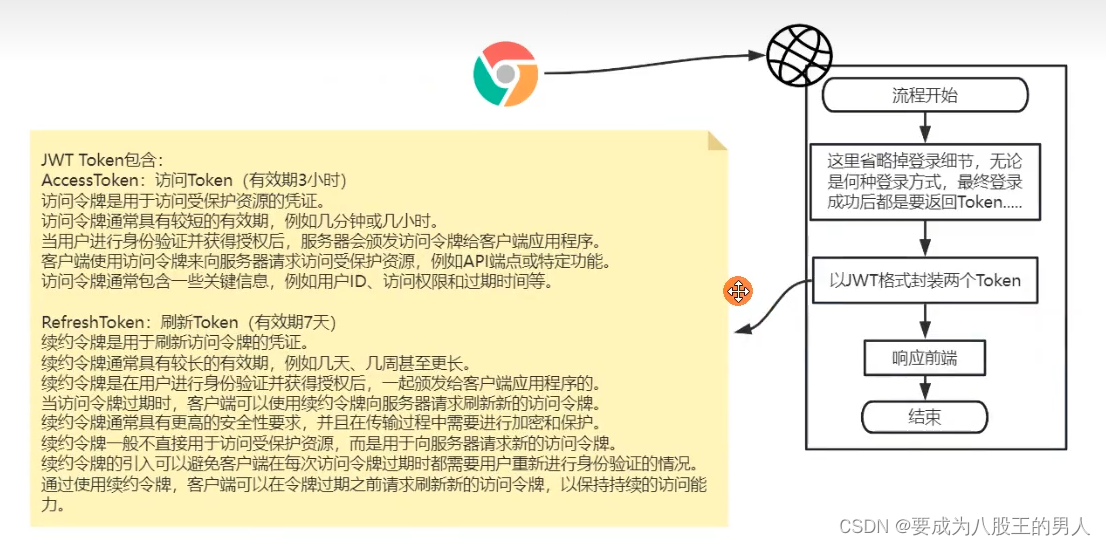
首先是登录,在登录的时候,无论何种方式认证,最后都是返回Token 给到前端。在返回 Token 的时候,是生成两个 Token:
- 一个是 AccessToken,我管他叫访问令牌,我处于安全考虑,比如防止令牌被恶意使用设置他的有效期为 3个小时,每次请求资源时携带这个令牌;
- 另一个是 RefreshToken,我管他叫刷新令牌,这个令牌不能用来访问资源,只能用来刷新访问令牌,就是每当访问令牌过期,前端携带这个RefreshToken 获取新的 AccessToken这个刷新 Token 的有效期我设置为7天,当然这个可以改,这是写在配置文件中的;
当 Token 返回给前端后,浏览器端用的是localStorage 保存的,App 端的话有他们自己的地保存方式,将这两个 Token 保存下来。
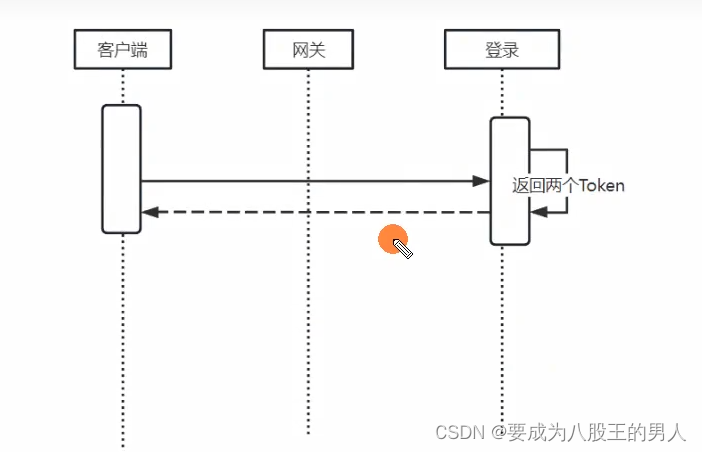
然后就是访问资源的时候,我们在网关处会进行校验,如果访问的是受限资源,那么网关写了一个全局过滤器,校验是否携带 AccessToken,以及这个 Token 是否过期如果正常,则直接放行。
如果校验异常,可能是 Token 过期,也可能是 Token 数据被篡改或损坏,于是返回拒绝。前端判断拒绝的状态码为 AccessToken 无效后,会重新发起一次请求,携带 RefreshToken 重新请求续约接口,这个续约接口是不需要网关拦截的,然后续约接口针对 RefreshToken 进行解密后,校验签名没有问题,没有被篡改,于是重新颁发新的AccessToken,返回给前端。前端重新携带 AccessToken 发起请求就行了这里面有个重要的地方就是,我针对令牌使用 RSA非对称加密进行加密,目的就是防止被篡改数据。
这就是我设计的实现方案。

七、前后端交互是怎么配合的
我们是使用 Swagger、Knife4j快速生成后端的接口文档,然后给到前端,和前端进行配合的。
这个 Knife4j就是一个整合了 Swagger和 OpenApi 的工具。开发接口的时候,我们是使用 Swagger 提供了一波注解,标注在不同的类、方法、属性上面快速的生成在线文档。
然后 Knife4j进行了增强,不仅页面美化了,而且还可以在线调试,还支持导出离线的接口文档。
我当初就是在开发环境启用了 Knife4j,只有在开发环境中,前端能够访问到我们的接口,然后也可以直接导出离线版,发给前进行对接。另外我自己本地测试的时候,包括和前端进行面对面沟通的时候,我是习惯使用postman 进行测试,Knife4j提供的那个测试页面功能太少,没有 Postman 专业。包括我们项目的每一个接口,都是在 PostMan 中创建了团队,进行维护的。无论是前端还是后端,都可以直接在它的接口列表中直接调出来以前写好的接口,进行接口测试的。
八、你们前端是怎么部署的?
我们前端的话分为 App 端和 PC 端。
App 端是直接打包成应用的。
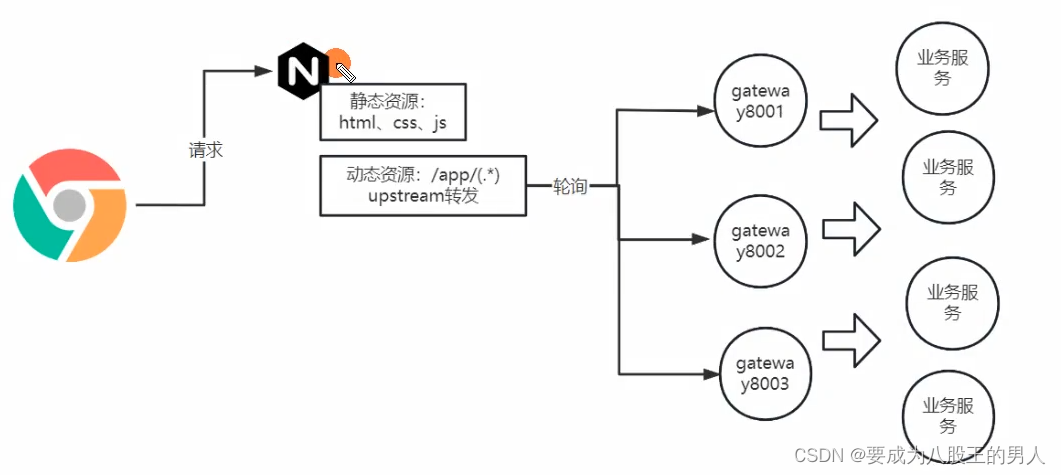
PC 端是需要将前端资源部署在服务器中的,我们是采用 nginx 作为前端项目的部署服务器。前端我们架构是使用 vue 写的,前端写完后会使用 webpack 进行编译构建,把 vue 文件转为编译后的js、css、html 之类的静态资源。然后把这些静态资源打包发布到 nginx 服务器。部署方式也很简单,将静态资源更新到 nginx的 html 目录下,然后修改 nginx配置文件,将root 目录指定到项目路径,这样前端请求域名根路径下的静态资源时,直接在nginx 端进行响应了
另外我们还配置了关于后端的 api 访问路由,凡是以 app 路径开头的资源,,全都转发到后端的网关微服务上,转发的策略用的是轮询。
九、文章查询流程简单讲一下?
文章查询我们是支持首页查询、频道栏目查询,另外还提供了关键字检索功能先说一下这个表结构吧,有3张表存储文章信息:文章基本信息表、文章配置表、文章内容表,他们之间都是一对一的映射关系。然后还有一个大数据推荐接口被我们调用。
ap_article 文章基本信息表

ap_artcle_config 文章配置表

ap_article_content 文章内容表
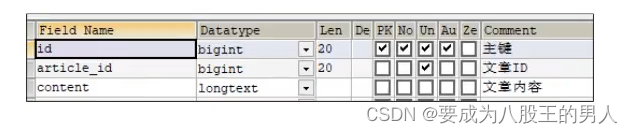
当初我在设计这三张表的时候,本质他们都是文章相关的字段,本应该在一张表里,但是考虑到后续随着数据量的增多,可能会单表带来很大的压力,所以进行了垂直分割。我按照查询的业务维度进行拆分的,比如:基本信息一张表,配置信息一张表,文章内容一张表进行分离。
先说首页查询吧,首页查询其实是推荐查询,推荐的依据主要是:
- 用户自己在个人中心配置过的感兴趣标签。
- 大数据系统根据用户行为数据分析得到的用户画像,这个是不断更新的;
- 系统本身的推荐,如:管理员设置的批量推荐、广告推荐、以及随机的热点资讯;
用户在 App 中每次上拉表示刷新一波推荐内容,请求到达后端后,后端是直接远程调大数据提供的推荐接口,返回推荐给用户的 30 条资讯文章信息 id。然后拼接这 30 条文章信息,返回给前端,前端以每页展示 10 条的方式进行分页展示然后就是当用户下拉到第三页的时候,前端再向后端发起请求,再调用大数据推荐接口获取后30 条推荐的文章数据返回给前端。
这个查询就是按照频道,时间进行查询数据库中的数据的。
如果用户切换了频道栏目,频道可以自定义,比如:新闻、国际、军事、娱乐、民生、两岸等,那么查询的时候就不再是按照推荐算法查询,而是按照发布时间进行查询。比如:用户在手机 App 中,下拉页面,就会刷新一波最新的资讯,这个资讯时间是依据上次刷新的时间,进行查询的,查询上次刷新之后的最新资讯。如果说没有更新的,那么会返回已经是最新的列表。
如果用户进行下拉,就会按照时间进行反向分页查找,比如先返回最近发布的10条数据,当浏览到底部的时候,自自动去查询更早的 10 条数据,在后端说白了其实就是按照时间字段进行条件筛选以及分页查询实现的。
另外就是我在完成这块业务的时候有两个技术上的小亮点。一个是采用 Freemark 将文章内容静态化,就是按照预制的模版,生成为静态的 HTML资源因为文章内容数据不会经常改动,但如果每次请求都要重新查询 DB,以及重新渲染模版数据的话,会造成计算资源浪费以及延长了响应时间。所以我们进行页面静态化,就是把文章的内容数据,按照预先定义好的模版,填充到模版中,生成静态资源的HTML文件。这样在后期无论是返回给 PC 还是返回到 App,都是直接返回准备好的静态资源。
另外就是我在完成这块业务的时候有两个技术上的小亮点。一个是采用 Freemark 将文章内容静态化,就是按照预制的模版,生成为静态的 HTML 资源,因为文章内容数据不会经常改动,但如果每次请求都要重新查询 DB,以及重新渲染模版数据的话,会造成计算资源浪费以及延长了响应时间。所以我们进行页面静态化,这样在后期无论是返回给 PC 还是返回到 App,都是直接返回准备好的静态资源。另一个就是将这个渲染好的静态资源,直接上传到公司内部搭建的分布式文件系统中,是使用minl0 搭建的,将来用户点击文章标题,进入到文章详情页时,就直接从 MinlO 中获取提前渲染好的页面数据就好了,不用再查询 DB。
还有就是关于文章的检索,这个我们是搭建了 Elasticsearch 进行实现的,用 Elasticsearch 的主要原因是,MySQL 本身查询的话,是基于物理自盘,所以查询效率比较低,而且遇到关键字模糊查询,会导致索引失效。另外就是 Elasticsearch 它自己的优势很明显,比如支持分词检索,并且也提供了一套完整的语法,支持各种查询方式。
所以我们使用 Elasticsearch 进行实现的。
十、ThreadLocal在项目中有用到过吗?
有的,我们是使用 ThreadLocal保存用户的状态信息,这样就可以随时随地获取到用户信息了。实际项目流程是这样设计的:
首先请求先到网关,我在网关设计了一个全局过滤器,当它拦截下来请求后,将请求进行解析,从请求头中拿到用户的访问 Token,这个 Token 经过解密后,转为 JWT格式的 Token,并校验签名是否正确,如果没有问题就获取到用户账号,并且将账号信息写到请求头中,转发给后面的业务服务。