sudo tar -zxvf hadoop-1.1.2.tar.gz -C / #解压到/usr/local目录下
sudo mv hadoop-1.1.2 hadoop #重命名为hadoop
sudo chown -R python ./hadoop #修改文件权限
//java安装同上
给hadoop配置环境变量,将下面代码添加到.bashrc文件
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
//export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/home/python/Downloads/hadoop
export HADOOP_PREFIX=$HADOOP_HOME
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source .bashrc
hadoop version
首先将jdk1.7的路径添(export JAVA_HOME=/usr/lib/jvm/java )加到hadoop/conf/hadoop-env.sh文件
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
//export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
修改core-site.xml文件
修改配置文件 hdfs-site.xml
修改配置文件 mapred-site.xml
修改配置文件 yarn-site.xml
从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项
伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行
执行 NameNode 的格式化,需先停止hadoop服务
hadoop namenode -format
启动hadoop守护进程:
./hadoop/bin/start-all.sh
./hadoop/bin/stop-all.sh
跟踪进程
strace -fe open start-all.sh
启动namenode和datanode进程,并查看启动结果
./hadoop/bin/start-dfs.sh
datanode启动失败解决方案
1.删除版本重格式化
rm ./hadoop/tmp/dfs/data/current/VERSION
rm -rf ./hadoop/tmp/dfs/data
chown -R python ./hadoop
sudo chmod -R a+w ./hadoop
//需先停止hadoop服务
./hadoop/bin/hadoop namenode -format
2.将name/current下的VERSION中的clusterID复制到data/current下的VERSION中,覆盖掉原来的clusterID
//需先停止hadoop服务
./hadoop/bin/hadoop namenode -format
apt install openjdk-8-jdk-headless
jps
浏览器查看hadoop运行状态:
NameNode - http://localhost:50070/
JobTracker - http://localhost:50030/
复制本地文件到HDFS的input目录:
./hadoop/bin/hadoop fs –put /home/python/Downloads/hadoop/conf /home/python/Downloads/hadoop/tmp/input
运行hadoop提供的例子:
hadoop jar /home/python/Downloads/hadoop/hadoop-examples-1.1.2.jar grep /home/python/Downloads/hadoop/tmp/input output 'dfs[a-z.]+'
查看DFS文件
hadoop fs -ls output
复制DFS文件到本地,并在本地查看:
词频统计
./hadoop/bin/hadoop dfs -ls /
//HDFS中创建一个文件目录input
./hadoop/bin/hadoop dfs -mkdir /input
./hadoop/bin/hadoop dfs -ls /
将./hadoop/README.txt上传至input中
./hadoop/bin/hadoop fs -put /hadoop/README.txt /input
./hadoop/bin/hadoop jar ./hadoop/hadoop-examples-1.1.2.jar wordcount /input /output
./hadoop/bin/hadoop fs -cat /output/part-r-00000
·下面附一些HDFS常用命令:
hadoop fs -mkdir /tmp/input? ? ? ?在HDFS上新建文件夹?
hadoop fs -put input1.txt /tmp/input 把本地文件input1.txt传到HDFS的/tmp/input目录下?
hadoop fs -get input1.txt /tmp/input/input1.txt 把HDFS文件拉到本地?
hadoop fs -ls /tmp/output? ? ? ? ?列出HDFS的某目录?
hadoop fs -cat /tmp/ouput/output1.txt 查看HDFS上的文件?
hadoop fs -rmr /home/less/hadoop/tmp/output 删除HDFS上的目录?
hadoop dfsadmin -report 查看HDFS状态,比如有哪些datanode,每个datanode的情况?
hadoop dfsadmin -safemode leave 离开安全模式?
hadoop dfsadmin -safemode enter 进入安全模式
ssh配置
root@ubuntu:~# ps -ef | grep ssh
如果未启动,可以通过下面命令启动:
root@ubuntu:~# /etc/init.d/ssh start
chmod go-w ~/
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
免密码配置ssh
root@ubuntu:~# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
## -P表示密码,-P '' 就表示空密码,也可以不用-P参数,这样就要三车回车,用-P就一次回车。
root@ubuntu:~# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
#关闭防火墙
iptables -F
验证没有密码是否能ssh到localhost
root@ubuntu:~# ssh localhost
#调试信息
sudo /usr/sbin/sshd -d
netstat -tan | grep LIST
fxcRqV8/Jn6nHr0a/xxoDB4qxVhRD3BS1uXKvtp1Zk4
::ls ~/.ssh/*下有密钥时先清空
ssh-keygen -t rsa
一路回车
sudo vim /etc/ssh/sshd_config
要确保下面这三个项目前面没有#
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile %h/.ssh/authorized_keys
重启一下ssh服务,这样ssh配置才能生效:
使用命令:service ssh restart
将id_rsa.pub公钥添加到本地的~/.ssh/authorized_keys文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
::ls ~/.ssh/*
ssh localhost
exit
如果出现了Agent admitted failure to sign using the key的错误提示,
则使用ssh-add ~/.ssh/id_rsa来解决 。
使用ssh-copy-id命令将公钥传送到远程主机上
ssh-copy-id remote-host
ssh ubuntu@10.29.78.177安装JDK
root@ubuntu:/usr/java# ./jdk-6u27-linux-i586.bin
root@ubuntu:/# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.6.0_27
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
java -versionhbase
sudo tar -zxvf ./Downloads/hbase-0.94.7-security.tar.gz -c ./Downloads/
sudo mv ./Downloads/hbase-0.94.7-security ./Downloads/hbase
sudo chown -R python ./Downloads/hbase
cd Downloads/hbase
conf目录下hbase-env.sh:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
HBase写入的本地路径:
hbase-site.xml
启动HBase
bin/start-hbase.sh
用shell来连接HBase
bin/hbase shell
关闭防火墙
service iptables stop
确认
service iptables status
建表操作演示
create 'table1','col1'
list
put 'table1','row1','col1:a','value1'
put 'table1','row3','col1:c','value3'
scan 'table1'
//用get查看单行数据
get 'table1','row1'
//用disable和drop删除表
disable 'table1'
bin/stop-hbase.sh
访问地址:http://localhost:60010/
hive
export HIVE_HOME=/home/python/Downloads/hive
export PATH=$HIVE_HOME/bin:$PATH
复制conf/hive-default.xml并重命名为hive-site.xml
复制MySQL驱动到<hive-install-dir>/lib/。我用的是:mysql-connector-java-5.1.7-bin.jar
运行Hive
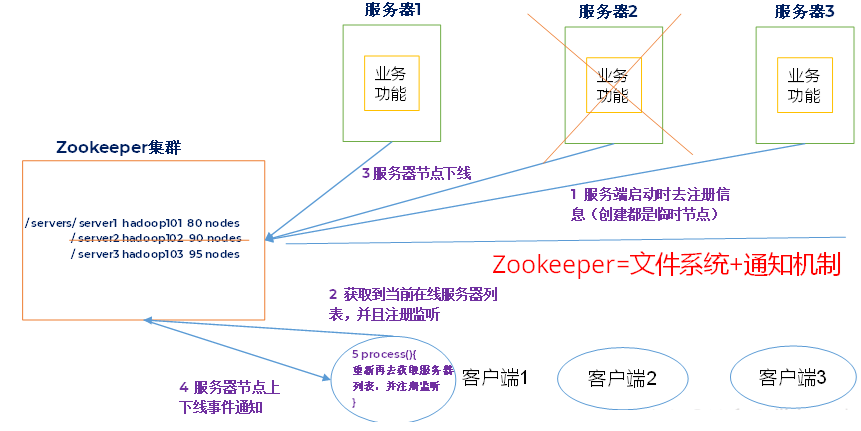
bin/hiveZookeeper
将conf/zoo_sample.cfg拷贝一份命名为zoo.cfg,也放在conf目录下
sudo mkdir /tmp/zookeeper
# 在 /tmp/zookeeper目录下创建myid文件,写id号,用来标识当前主机
/tmp/zookeeper下执行 echo "1" > myid
bin/zkServer.sh start
bin/zkServer.sh status
sudo java-cp zookeeper-3.4.5.jar:lib/slf4j-api-1.6.1.jar:lib/slf4j-log4j12-1.6.1.jar:lib/log4j-1.2.15.jar:conf\org.apache.zookeeper.server.quorum.QuorumPeerMain conf/zoo.cfg参考:
Hadoop伪分布式环境搭建_hadoop安装和伪分布式集群搭建的过程-CSDN博客
HBase单机环境搭建及入门_hbase可以单机运行-CSDN博客
GitHub - apache/spark: Apache Spark - A unified analytics engine for large-scale data processing
Spark在Windows下的环境搭建_windows spark-CSDN博客
ZooKeeper集群环境搭建实践_服务器应用_Linux公社-Linux系统门户网站
创作不易,小小的支持一下吧!