文章目录
一、前言
嵌入式音视频开发过程中涉及到的音视频相关概念有很多,本文对音频一些常见的术语和概念进行详细的介绍和总结。
二、概述
如何采集声音?
通过模数转换原理,声音模数转换是将声音信号从模拟形式转换为数字形式的过程。它是数字声音处理的基础,常用于语音识别、音频编码等应用中。
为什么音视频采集完之后,不能直接传输,要进行编码?
在音视频采集完之后,通常不会直接传输原始数据,而是要经过编码处理,主要原因有以下几个:
数据量过大: 原始音视频数据量非常庞大。例如,未经压缩的高清(1080p)视频,每秒的数据量可以达到数百MB,即使是未经压缩的音频数据也会占用较大的带宽。直接传输这些数据会占用过多的网络资源,甚至可能无法进行实时传输。
带宽限制: 大多数网络环境(尤其是互联网或无线传输环境)都存在带宽限制。将原始数据进行压缩编码可以大幅减少数据量,从而使得在有限的带宽内能够流畅地传输音视频数据。
存储空间: 原始音视频数据的存储需求极大,经过编码压缩后,可以显著减少所需的存储空间,使得数据更易于存储和管理。
传输可靠性和错误恢复: 编码协议中往往包含纠错和恢复机制,能够在传输中出现数据丢失或错误时进行恢复,确保接收到的音视频数据质量。这是原始数据所不具备的优势。
兼容性和标准化: 编码格式通常是标准化的,这意味着不同设备和平台之间可以互相兼容。例如,H.264是广泛应用的视频编码标准,不同的设备和软件都可以编码和解码这种格式的数据,提高了互操作性。
实时性要求: 为了满足实时传输的需求,编码算法可以进行优化,使数据传输和解码过程更为迅速,从而减少延时。这在实时通信(如视频通话、直播)中尤为重要。
安全性和版权保护: 编码过程中可以加入加密和数字版权管理(DRM)措施,保护数据的安全性和版权。这在商业应用和版权保护方面具有重要意义。
综合以上原因,对于大部分应用场景来说,通过编码压缩方式传输音视频数据既节省了传输带宽和存储空间,同时又能保证数据传输的效率和可靠性。因此音视频在采集完之后,通常都需要进行一定的编码处理,再进行传输。
三、音频相关概念
1、采样率(Sampling rate)
当我们想要数字化的记录声音时,需要将声音的模拟信号转换成数字信号,这个过程就是采样。采样率指的是在单位时间内(每一秒)采集的样本数量,通常用赫兹(Hz)表示。例如44100Hz,指的就是每秒采样数为44100,也常被简称为44.1KHz。
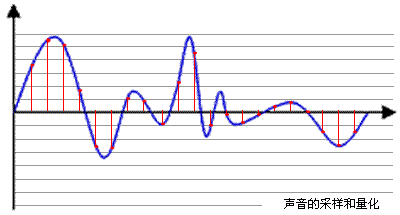
蓝色代表模拟音频信号,红色的点代表采样得到的量化数值。采样频率越高,红色的间隔就越密集。
具体来说,采样率越高,数字化的声音信号就越接近原始声音,所以采样率越高声音质量就越好,但是数字化文件的大小也会越大。常见的采样率有8kHz、16kHz、44.1kHz、48kHz等。语音通话、监控摄像头等,这些场景下,音频采样率一般只有8KHz,这个频率虽然听音乐是一种折磨,会一卡一卡的,但是对听清别人说话倒是一点问题没有。
2、位深度(Bit depth)
位深度,也叫位宽,采样精度,单位为Bit。上图中,每一个红色的采样点,都需要用一个数值来表示大小,这个数值的数据类型大小可以是:4bit、8bit、16bit、24bit等等,位数越多,则位深度越大,记录的样本数据精度就越高,表示得就越精细,声音质量自然就越好,当然,数据量也会成倍增大。
位深影响信号的信噪比和动态范围,也决定了文件的大小,理论上来说,位深越高,质量越好,同时其所生成的文件也越大。
笔者借用网络上看过的一个总结:声波,有频率和振幅,频率高低决定音调,振幅大小决定响度,采样率是对频率采样,位深是对振幅采样。
3、比特率(Bit rate)
比特率俗称码率。顾名思义,比特率就是Bit的速率的意思,意思为单位时间内(每一秒)传输或处理的Bit的数量。比如一个单声道,用44.1KHz/16Bit的配置来说,它的比特率就为 44100*16*1=705600,单位是bit/s,因为通常计算出来的数字都比较大,大家就用kbit/s了,也就是705.6kbit/s(也有人用bps,或者kbps来当比特率的单位,意思是一样的,bps是比特/秒(bits per second)的缩写,表示每秒钟传输的比特数)。
何为比特数?就是比特率乘以时长即可。1Byte(字节)等于8个Bit。通常情况下,文件大小的算法是这样的,比如,所选择的采样率为44100,位深为16Bit,单轨道,时长为60s,则Bits(比特数)的值为44100*16*1*60=42336000,然后我们再将Bits(比特数)转换成Byte(字节),直接除以8等于5292000个Byte,有了Byte我们就可以将其转换成KB或者M(结果大约是5168KB,5M左右)。
计算公式:Bits(比特数) = 采样率 x 位深 x 通道数 x 时长
以上计算的是不压缩的原始音频数据。
4、声道(Audio channel)
声道,是指在不同空间位置录制或播放声音时采集或播放的独立音频信号。通俗的讲就是:声道数就是声源个数。比如:单声道(Mono),采集源只有一个;双声道也称为立体声(Stereo),采集源有两个,分别为左和右;多声道即环绕声(Surround Sound),采集源有多个。
每个声道的声音样本都会单独记录,一般双声道的采样数是单声道的两倍,多声道同理。在数字音频处理中,立体声(左右通道)的采样数据可以有不同的排列方式,具体取决于音频文件的格式和存储标准。这里是两种常见的排列方式:
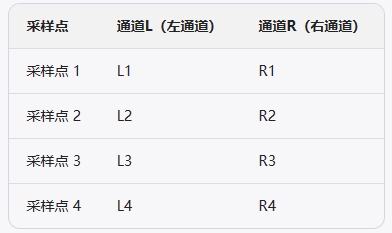
交错排列(Interleaved):
在交错排列方式中,左右通道的采样数据是交替存储的,每个通道的采样点依次排在一起。这是最常见的一种格式,广泛应用于WAV、AIFF等音频文件中。
例如,对于一个包含4个采样点的立体声样本,数据排列如下:
数据在内存中的实际排列方式为:L1, R1, L2, R2, L3, R3, L4, R4。
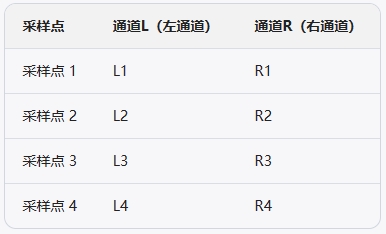
非交错排列或平面排列(Non-Interleaved or Planar):
在这种方式中,每个通道的数据是连续存储的,即所有左通道的数据存储在一起,然后是所有右通道的数据。某些专业音频处理软件和格式(如某些版本的FLAC)可能会使用这种方式。
使用相同的例子,数据排列如下:
数据在内存中的实际排列方式为:L1, L2, L3, L4, R1, R2, R3, R4。
以上两个排列方式各有优缺点,交错排列方式通常在播放和处理过程中更具效率,因为其数据连续性可以减少缓存缺失(cache miss)。而非交错排列方式可能在某些批处理或信号处理算法中略微简化操作,但在实时播放和任意读取时可能稍显复杂。
总的来说,交错排列(interleaved)是更为常见和普遍使用的方式,特别是在需要实时播放和处理的情况下。
声道越多,播放的音频效果越立体,但是存储的数据越大。
5、音频帧
理论上,音频并不需要音频帧的概念,因为音频采样数据和采样率已经可以把音频播放描述清楚了。
但是音视频文件播放时,为了保证音视频同步,程序需要根据每帧的播放时间戳进行有序播放。由于每个音频采样数据太小了,如果每个采样数据都记录播放时间戳的话,那么就得不偿失了。毕竟一个时间戳数据的大小比一个音频采样数据都大,所以就有了音频帧的概念。
音频帧的概念没有视频帧那么清晰,几乎所有视频编码格式都可以简单的认为一帧就是编码后的一幅图像。但音频帧跟编码格式相关,它是各个编码标准自己实现的。
音频帧实际上就是把一小段时间的音频采样数据打包起来,如每20ms的音频采样数据合并成一帧。这里的具体时间间隔是具体编码码格式决定的,一般不需要特别关心。

如果以PCM(未经编码的音频数据)来说,它根本不需要帧的概念,根据采样率和采样精度就可以播放了。比如采样率为44.1kHz,采样精度为16bit的音频,你可以算出bitrate(比特率)是44100*16 bps,每秒的音频数据是固定的44100*16/8字节。
对采样率为44.1kHz的AAC音频进行解码时,一帧的解码时间须控制在23.22毫秒内。通常是按1024个采样点一帧。
分析:
1、 AAC
AAC(高级音频编码)采用了一种称为MDCT(修正离散余弦变换)的技术来处理音频信号。MDCT在AAC中的一个帧长度为1024个采样点,是出于技术性能、压缩效率、音质以及标准化等多方面的考虑。
音频帧的播放时长 = 一个AAC帧对应的采样点个数 / 采样频率(单位为s)
一个AAC原始帧包含某段时间内1024个采样点相关数据。
44.1kHz采样率,表示每秒44100个采样点,则当前一帧的播放时长 = 1024*1000/44100 = 22.32ms。
48kHz采样率,则当前一帧的播放时长 = 1024*1000/48000 = 21.32ms。
22.05kHz采样率,则当前一帧的播放时长 = 1024 *1000/220500 = 46.43ms。
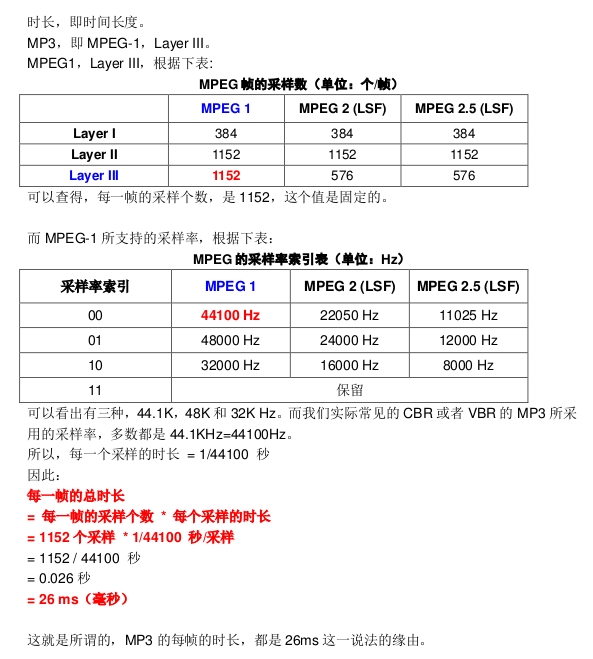
2、MP3
mp3每帧包含1152个采样点,则每帧播放时长 = 1152*1000/sample_rate(采样率)。
例如:sample_rate = 44100Hz时,计算出每帧播放时长 = 1152*1000/441000 = 26.122ms,这就是经常听到的mp3每帧播放时间固定为26ms的由来。
详细请看下图:
6、音频编码
音频编码是将原始的未压缩音频数据转换为压缩格式的一系列过程,目的是减少数据量,以便更高效地存储和传输。以下是常见的音频编码流程:
1、采样和量化(Sampling and Quantization)
采样:音频信号是连续的模拟信号,采样是将其在时间轴上以固定的间隔进行离散化,也就是每秒钟记录一定数量的音频样本,这个过程生成一系列离散的数据点。采样率通常以赫兹(Hz)为单位,例如44.1kHz表示每秒采样44100次。
量化:将这些离散的采样点的电压值转化为数字格式,通常是用二进制数表示。量化级别决定了每个采样点的精度,通常称为比特深度(bit depth),例如16位或24位越高的比特深度能表示的音频细节就越多。
2、预处理(Pre-processing)
过滤和去噪(Filtering and Denoising):优化音频信号的质量,对采样数据进行提前处理,包括去除噪音和不必要的频段。
分帧(Framing):将音频数据分割成小的帧(帧通常包含数百到数千个采样点),以便于后续处理。
3、变换和特征提取(Transformation and Feature Extraction)
变换(Transformation):通过数学变换(如快速傅里叶变换FFT或离散余弦变换DCT)将音频信号从时域转换到频域,这可以使得某些频率特性更容易被分析和处理。
4、压缩(Compression)
无损压缩(Lossless Compression):在不损失任何音频信息的前提下压缩数据,例如FLAC。如果需要保留音频的全部细节,可以选择无损压缩,但压缩率不高。
有损压缩(Lossy Compression):通过丢弃人耳不易察觉的音频信息来达到更高的压缩比例,例如MP3、AAC。这种方法有效减小文件大小,但会损失一些音质。
5、编码(Coding)
音频编码器(Audio Encoder):采用特定的编码算法将压缩后的音频数据转换为一种标准格式,这会涉及使用例如熵编码(Entropy Coding)(如哈夫曼编码)等技术,提高数据的压缩效率。
元数据添加(Adding Metadata):往编码数据中加入相关的元数据,如采样率、比特率、声道数等,以及文件的其他信息如标题、艺术家、专辑等。
6、封装(Packaging)
容器格式(Container Format):将编码后的音频数据和元数据存储在某种容器格式中。例如WAV、MP3、AAC等。
7、存储和传输(Storage and Transmission)
存储在本地或者通过网络传输。编码后的音频文件由于体积较小,因此能够高效地在各种平台和设备之间进行传输和共享。
总结
音频编码通过一系列复杂的处理步骤,大幅减少了音频数据量。这一过程涉及采样、量化、预处理、变换、压缩和编码等多个阶段,其目标是在音质和数据量之间取得平衡,以便更高效地存储和传输音频数据。无论是用于实时传输的有损编码,还是用于高保真存储的无损编码,不同的编码方式和技术满足了不同应用的需求。
音频编码标准
| 音频编码标准 | 描述 |
|---|---|
| PCM (Pulse Code Modulation) | 基本的脉冲编码调制方式,无损编码,采样率高,文件较大 |
| G711 (A-law 和 µ-law) | G.711是一种关键的音频编码标准,凭借其高语音质量、低延迟和广泛的兼容性,成为电话网络和VoIP服务中的重要组成部分,G.711并不是严格意义上的无损编码,G.711的语音质量通常被认为是接近于原始模拟信号的 |
| MP3 (MPEG-1 Audio Layer 3) | 有损压缩音频编码,流行的音频格式,文件小,保留较高音质 |
| AAC (Advanced Audio Coding) | 高级音频编码标准,有损压缩,音质优秀,常用于在线音频流媒体 |
| OGG Vorbis | 开源音频编码,有损压缩,提供高音质,文件相对小 |
| FLAC (Free Lossless Audio Codec) | 无损音频编码,保留原始音频质量,文件较大,用于音频编辑和存档 |
| Opus | 开放式、免专利的音频编码标准,支持广泛的比特率,适用于语音通话和音频流传输 |
| WMA (Windows Media Audio) | 微软开发的音频编码标准,有损压缩,适用于 Windows 平台 |
| AC3 (Dolby Digital) | 杜比数字音频编码标准,多用于 DVD、蓝光光盘等视频音频压缩 |
| DTS (Digital Theater Systems) | 数字影院系统音频编码标准,提供高质量环绕声音效果 |
| ALAC (Apple Lossless Audio Codec) | 苹果无损音频编码标准,保留音频原始质量,适用于苹果设备 |
7、音频解码
音频解码的流程总体上可以分为以下几个步骤:
1、接收编码数据: 通过网络下载、存储设备读取等方式获取到编码的音频文件。通常,这些文件使用各种压缩和编码技术对原始音频数据进行了处理,以减少文件大小并便于传输。
2、解析文件格式: 了解音频文件的格式(如MP3、AAC、FLAC等),并准确解析文件头,以获取编码信息、采样率、声道数、比特率等关键参数。
3、提取编码数据: 从音频文件中提取出实际的音频数据流,这部分数据是经过压缩和编码后的,需要还原成原始的未压缩音频数据。
4、解码音频数据: 使用相应的解码算法将压缩的音频数据还原成原始的PCM (Pulse Code Modulation) 数字音频信号。这一步骤需要了解具体的编码/解码算法,比如MP3的霍夫曼编码、AAC的MDCT转换等。
5、音频处理(可选): 根据需求,对解码后的音频数据进行处理,比如增益调整、均衡、混音等。
6、输出音频: 将解码并处理过的PCM音频数据传输到音频输出设备,比如扬声器、耳机等,或者存储为新的音频文件。
这是一个较为简化的描述,各种编码格式和解码器可能有些具体操作上的差异,但大致流程一致。
有建议或疑问,评论区沟通交流。
该专栏下一篇文章我们对嵌入式音视频开发中视频相关概念进行详解。