问题
DG连接问题
原理:JDBC:用Java代码连接数据库
Hive/SparkSQL:端口有区别
可以为同一个端口,只要不在同一台机器
项目:一台机器
HiveServer:10000
hiveserver.port = 10000SparkSQL:10001
start-thriftserver.sh --hiveserver.prot = 10001MySQL:hostname、port、username、password
Oracle:hostname、port、username、password、sid
CS模式设计问题
Thrift启动问题
CS模式:客户端服务端模式
Client:客户端
Hive:Beeline、Hue
SparkSQL
Server:服务端
Hive:Hiveserver2【负责解析SQL语句】
HiveServer作为Metastore的客户端
MetaStore作为HiveServer的服务端
SparkSQL:ThriftServer【负责解析SQL语句转换为SparkCore程序】
启动ThriftServer或者HiveServer
docker start hadoop
docker start hive
docker start spark问题:思路
现象:异常
Python:error:xxxxxx
Java:throw Exception:xxxxxxxxx
进程没有明显报错:找日志文件
日志文件:logs
查看日志:tail -100f logs/xxxxxxxx.log
分析错误
ArrayoutofIndex
NullException
ClassNotFound
数据仓库设计
建模:维度建模:【事实表、维度表】
分层:ODS、DW【DWD、DWM、DWS】、APP
本次项目中数仓的分层
ODS、DWD、DWB、DWS、ST、DM
数仓设计回顾
目标:了解数据仓库设计的核心知识点
路径
step1:分层
step2:建模
实施
分层
什么是分层?
本质:规范化数据的处理流程
实现:每一层在Hive中就是一个数据库
为什么要分层?
清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和解。
数据血缘追踪:简单来讲可以这样理解,我们最终给业务诚信的是一能直接使用的一张业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
把复杂问题简单化:一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。
屏蔽原始数据的异常对业务的影响:不必改一次业务就需要重新接入数据
怎么分层?
ODS:原始数据层/操作数据层,最接近与原始数据的层次,数据基本与原始数据
保持一致
DW:数据仓库层,实现数据的处理转换
DWD:实现ETL
DWM:轻度聚合
DWS:最终聚合
ADS/APP/DA:数据应用层
建模
什么是建模?
本质:决定了数据存储的方式,表的设计
为什么要建模?
大数据系统需要数据模型方法来帮助更好地组织和存储数据,以便在性能、成本、效率和质量之间取得最佳平衡。
性能:良好的数据模型能帮助我们快速查询所需要的数据,减少数据的I/O吞吐
成本:良好的数据模型能极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低大数据系统中的存储和计算成本
效率:良好的数据模型能极大地改善用户使用数据的体验,提高使用数据的效率
质量:良好的数据模型能改善数据统计口径的不一致性,减少数据计算错误的可能性
有哪些建模方法?
ER模型:从全企业的高度设计一个 3NF 【三范式】模型,用实体关系模型描述企业业务,满足业务需求的存储
维度模型:从分析决策的需求出发构建模型,为分析需求服务,重点关注用户如何更快速的完成需求分析,具有较好的大规模复杂查询的响应性能
Data Vault:ER 模型的衍生,基于主题概念将企业数据进行结构化组织,并引入了更进一步的范式处理来优化模型,以应对源系统变更的扩展性
Anchor:一个高度可扩展的模型,核心思想是所有的扩展知识添加而不是修改,因此将模型规范到 6NF,基本变成了 k-v 结构化模型
怎么构建维度模型步骤?
a.选择业务过程:你要做什么?
b.声明粒度:你的分析基于什么样的颗粒度?
c.确认环境的维度:你的整体有哪些维度?
d.确认用于度量的事实:你要基于这些维度构建哪些指标?
具体的实施流程是什么?
a.需求调研:业务调研和数据调研
业务调研:明确分析整个业务实现的过程
数据调研:数据的内容是什么
b.划分主题域:面向业务将业务划分主题
构建哪些主题域以及每个主题域中有哪些主题
服务域:工单主题、回访主题、物料主题
c.构建维度总线矩阵:明确每个业务主题对应的维度关系
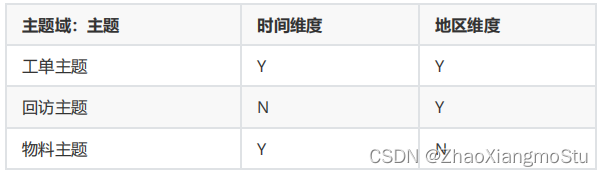
d.明确指标统计:明确所有原生指标与衍生指标
工单主题:安装工单个数、维修工单个数……
回访主题:用户满意个数、不满意个数、服务态度不满意个数、技术能力不满意个数
e.定义事实与维度规范
分层规范
开发规范
……
f.代码开发
事实表
表的分类
事务事实表:原始的事务事实的数据表,原始业务数据表
周期快照事实表:周期性对事务事实进行聚合的结果
累计快照事实表:随着时间的变化,事实是不定的,不断完善的过程
无事实事实表:特殊的事实表,里面没有事实,是多个维度的组合,用于求事实的差值
值的分类
可累加事实:在任何维度下指标的值都可以进行累加
半可累加事实:在一定维度下指标的值都可以进行累加
不可累加事实:在任何维度下指标的值都不可以进行累加
维度表
维度设计模型
雪花模型:维度表拥有子维度表,部分维度表关联在维度表中,间接的关联事实表
星型模型/星座模型:维度表没有子维度,直接关联在事实表上,星座模型中有多个事实
上卷与下钻
上卷:从小维度到一个大的维度,颗粒度从细到粗
下钻:从大维度到一个小的维度,颗粒度从粗到细
拉链表
功能:解决事实中渐变维度发生变化的问题,通过时间来标记维度的每一种状态,存储所有状态
实现
step1:先采集所有增量数据到更新表中
step2:将更新表的数据与老的拉链表的数据进行合并写入一张临时表
step3:将临时表的结果覆盖到拉链表中
掌握油站分析项目中的分层整体设计

ODS:原始数据层:最接近于原始数据的层次,直接采集写入层次:原始事务事实表
DWD:明细数据层:对ODS层的数据根据业务需求实现ETL以后的结果:ETL以后事务事实表
DWB:基础数据层:类似于以前讲解的DWM,轻度聚合
关联:将主题事实的表进行关联,所有与这个主题相关的字段合并到一张表
聚合:基于主题的事务事实构建基础指标
主题事务事实表
ST:数据应用层:类似于以前讲解的APP,存储每个主题基于维度分析聚合的结果:周期快照
事实表
供数据分析的报表
DM:数据集市:按照不同部门的数据需求,将暂时没有实际主题需求的数据存储
做部门数据归档,方便以后新的业务需求的迭代开发
DWS:维度数据层:类似于以前讲解的DIM:存储维度数据表
数据仓库设计方案
从上到下:在线教育:先明确需求和主题,然后基于主题的需求采集数据,处理数据
场景:数据应用比较少,需求比较简单
掌握油站分析的每层的具体功能
实施
ODS
数据内容:存储所有原始业务数据,基本与Oracle数据库中的业务数据保持一致
数据来源:使用Sqoop从Oracle中同步采集
存储设计:Hive分区表,avro文件格式存储,保留3个月
DWD
数据内容:存储所有业务数据的明细数据
数据来源:对ODS层的数据进行ETL扁平化处理得到
存储设计:Hive分区表,orc文件格式存储,保留所有数据
DWB
数据内容:存储所有事实与维度的基本关联、基本事实指标等数据
数据来源:对DWD层的数据进行清洗过滤、轻度聚合以后的数据
存储设计:Hive分区表,orc文件格式存储,保留所有数据
ST
数据内容:存储所有报表分析的事实数据
数据来源:基于DWB和DWS层,通过对不同维度的统计聚合得到所有报表事实的指标
DM
数据内容:存储不同部门所需要的不同主题的数据
数据来源:对DW层的数据进行聚合统计按照不同部门划分
DWS
数据内容:存储所有业务的维度数据:日期、地区、油站、呼叫中心、仓库等维度表
数据来源:对DWD的明细数据中抽取维度数据
存储设计:Hive普通表,orc文件 + Snappy压缩
特点:数量小、很少发生变化、全量采集
全量表与增量表数据采集需求
实施
全量表
所有维度数据表
场景:不会经常发生变化的数据表,例如维度数据表等
数据表:组织机构信息、地区信息、服务商信息、数据字典等
表名:参考文件《full_import_tables.txt》
增量表
所有事务事实的数据表
场景:经常发生变化的数据表,例如业务数据、用户行为数据等
数据表:工单数据信息、呼叫中心信息、物料仓储信息、报销费用信息等
表名:参考文件《incr_import_tables.txt》
Sqoop命令
连接Oracle语法
--connect jdbc:oracle:thin:@OracleServer:OraclePort:OracleSID 1docker exec -it sqoop bashsqoop import \
--connect jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin \
--username ciss \
--password 123456 \
--table CISS4.CISS_BASE_AREAS \
--target-dir /test/full_imp/ciss4.ciss_base_areas \
--fields-terminated-by "\t" \
-m 1YARN常用端口
NameNode:8020,50070
ResourceManager:8032,8088
JobHistoryServer:19888
Master:7077,8080
HistoryServer:18080
程序提交成功,但是不运行而且不报错,什么问题,怎么解决?
资源问题:APPMaster就没有启动
环境问题
NodeManager进程问题:进程存在,但不工作
机器资源不足导致YARN或者HDFS服务停止:磁盘超过90%,所有服务不再工作
解决:实现监控告警:80%,邮件告警
YARN中程序运行失败的原因遇到过哪些?
代码逻辑问题
资源问题:Container
Application / Driver:管理进程
MapTask和ReduceTask / Executor:执行进程
解决问题:配置进程给定更多的资源
程序已提交YARN,但是无法运行,报错:Application is added to the scheduler and is not activated. User’s AM resource limit exceeded.
yarn.scheduler.capacity.maximum-am-resource-percent=0.8配置文件:${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml
属性功能:指定队列最大可使用的资源容量大小百分比,默认为0.2,指定越大,AM能使用的资源越多


程序提交,运行失败,报错:无法申请Container?
yarn.scheduler.minimum-allocation-mb=512配置文件:${HADOOP_HOME}/etc/hadoop/yarn-site.xml
属性功能:指定AM为每个Container申请的最小内存,默认为1G,申请不足1G,默认分配1G,值过大,会导致资源不足,程序失败,该值越小,能够运行的程序就越多
怎么提高YARN集群的并发度?
物理资源、YARN资源、Container资源、进程资源
YARN资源配置
yarn.nodemanager.resource.cpu-vcores=8
yarn.nodemanager.resource.memory-mb=8192Container资源
yarn.scheduler.minimum-allocation-vcores=1
yarn.scheduler.maximum-allocation-vcores=32
yarn.scheduler.minimum-allocation-mb=1024
yarn.scheduler.maximum-allocation-mb=8192MR Task资源
mapreduce.map.cpu.vcores=1
mapreduce.map.memory.mb=1024
mapreduce.reduce.cpu.vcores=1
mapreduce.reduce.memory.mb=1024Spark Executor资源
--driver-memory #分配给Driver的内存,默认分配1GB
--driver-cores #分配给Driver运行的CPU核数,默认分配1核
--executor-memory #分配给每个Executor的内存数,默认为1G,所有集群模式都
通用的选项
--executor-cores #分配给每个Executor的核心数,YARN集合和Standalone集
群通用的选项
--total-executor-cores NUM #Standalone模式下用于指定所有Executor所
用的总CPU核数
--num-executors NUM #YARN模式下用于指定Executor的个数,默认启动2个MR的Uber模式
Spark为什么要比MR要快
MR慢
只有Map和Reduce阶段,每个阶段的结果都必须写入磁盘
如果要实现Map1 -> Map2 -> Reduce1 -> Reduce2
MapReduce1:Map1
MapReduce2:Map2 -> Reduce1
MapReduce3:Reduce2
MapReduce程序处理是进程级别:MapTask进程、ReduceTask进程
问题:MR程序运行在YARN上时,有一些轻量级的作业要频繁的申请资源再运行,性能比较差怎么办?
Uber模式
功能:Uber模式下,程序只申请一个AM Container:所有Map Task和Reduce Task,均在这个Container中顺序执行

默认不开启
配置:${HADOOP_HOME}/etc/hadoop/mapred-site.xml
mapreduce.job.ubertask.enable=true
#必须满足以下条件
mapreduce.job.ubertask.maxmaps=9
mapreduce.job.ubertask.maxreduces=1
mapreduce.job.ubertask.maxbytes=128M
yarn.app.mapreduce.am.resource.cpu-vcores=1
yarn.app.mapreduce.am.resource.mb=1536M特点
Uber模式的进程为AM,所有资源的使用必须小于AM进程的资源
Uber模式条件不满足,不执行Uber模式
Uber模式,会禁用推测执行机制
Sqoop采集数据格式问题
现象
step1:查看Oracle中CISS_SERVICE_WORKORDER表的数据条数
select count(1) as cnt from CISS_SERVICE_WORKORDER;step2:采集CISS_SERVICE_WORKORDER的数据到HDFS上
sqoop import \
--connect jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin \
--username ciss \
--password 123456 \
--table CISS4.CISS_SERVICE_WORKORDER \
--delete-target-dir \
--target-dir /test/full_imp/ciss4.ciss_service_workorder \
--fields-terminated-by "\001" \
-m 1step3:Hive中建表查看数据条数
进入Hive容器
docker exec -it hive bash连接HiveServer
beeline -u jdbc:hive2://hive.bigdata.cn:10000 -n root -p 123456创建测试表
create external table test_text(
line string
)
location '/test/full_imp/ciss4.ciss_service_workorder';统计行数
select count(*) from test_text;问题:Sqoop采集完成后导致HDFS数据与Oracle数据量不符
原因
sqoop以文本格式导入数据时,默认的换行符是特殊字符
Oracle中的数据列中如果出现了\n、\r、\t等特殊字符,就会被划分为多行
Oracle数据

Sqoop遇到特殊字段就作为一行

Hive

解决
方案一:删除或者替换数据中的换行符
--hive-drop-import-delims:删除换行符
--hive-delims-replacement char:替换换行符
不建议使用:侵入了原始数据
方案二:使用特殊文件格式:AVRO格式
常见格式介绍

SparkCore缺点:RDD【数据】:没有Schema
SparkSQL优点:DataFrame【数据 + Schema】
Schema:列的信息【名称、类型】
Avro格式特点
优点
二进制数据存储,性能好、效率高
使用JSON描述模式,支持场景更丰富
Schema和数据统一存储,消息自描述
模式定义允许定义数据的排序
缺点
只支持Avro自己的序列化格式
少量列的读取性能比较差,压缩比较低
场景:基于行的大规模结构化数据写入、列的读取非常多或者Schema变更操作比较频繁的场景
Sqoop使用Avro格式
选项
--as-avrodatafile Imports
# data to Avro datafiles注意:如果使用了MR的Uber模式,必须在程序中加上以下参数避免类冲突问题
-Dmapreduce.job.user.classpath.first=true使用
sqoop import \
-Dmapreduce.job.user.classpath.first=true \
--connect jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin \
--username ciss \
--password 123456 \
--table CISS4.CISS_SERVICE_WORKORDER \
--delete-target-dir \
--target-dir /test/full_imp/ciss4.ciss_service_workorder \
--as-avrodatafile \
--fields-terminated-by "\001" \
-m 1Sqoop增量采集方案
Append
要求:必须有一列自增的值,按照自增的int值进行判断
特点:只能导入增加的数据,无法导入更新的数据
场景:数据只会发生新增,不会发生更新的场景
代码
sqoop import \
--connect jdbc:mysql://node3:3306/sqoopTest \
--username root \
--password 123456 \
--table tb_tohdfs \
--target-dir /sqoop/import/test02 \
--fields-terminated-by '\t' \
--check-column id \
--incremental append \
--last-value 0 \
-m 1Lastmodified
要求:必须包含动态时间变化这一列,按照数据变化的时间进行判断
特点:既导入新增的数据也导入更新的数据
场景:一般无法满足要求,所以不用
代码
sqoop import \
--connect jdbc:mysql://node3:3306/sqoopTest \
--username root \
--password 123456 \
--table tb_lastmode \
--target-dir /sqoop/import/test03 \
--fields-terminated-by '\t' \
--incremental lastmodified \
--check-column lastmode \
--last-value '2021-06-06 16:09:32' \
-m 1特殊方式
要求:每次运行的输出目录不能相同
特点:自己实现增量的数据过滤,可以实现新增和更新数据的采集
场景:一般用于自定义增量采集每天的分区数据到Hive
代码
sqoop import \
--connect jdbc:mysql://node3:3306/db_order \
--username root \
--password-file file:///export/data/sqoop.passwd \
--query "select * from tb_order where
substring(create_time,1,10) = '2021-09-14' or
substring(update_time,1,10) = '2021-09-14' and \$CONDITIONS " \
--delete-target-dir \
--target-dir /nginx/logs/tb_order/daystr=2021-09-14 \
--fields-terminated-by '\t' \
-m 1实现自动化脚本开发
脚本目标:实现自动化将多张Oracle中的数据表全量或者增量采集同步到HDFS中
实现流程
a. 获取表名
b. 构建Sqoop命令
c. 执行Sqoop命令
d. 验证结果
脚本选型
Shell:Linux原生Shell脚本,命令功能全面丰富,主要用于实现自动化Linux指令,适合
于Linux中简单的自动化任务开发
Python:多平台可移植兼容脚本,自身库功能强大,主要用于爬虫、数据科学分析计算
等,适合于复杂逻辑的处理计算场景
场景:一般100行以内的代码建议用Shell,超过100行的代码建议用Python
采集脚本选用:Shell
单个测试
创建一个文件,存放要采集的表的名称
#创建测试目录
mkdir -p /opt/datas/shell
cd /opt/datas/shell/
#创建存放表名的文件
vim test_full_table.txtciss4.ciss_base_areas
ciss4.ciss_base_baseinfo
ciss4.ciss_base_csp
ciss4.ciss_base_customer
ciss4.ciss_base_device
创建脚本
vim test_full_import_table.sh构建采集的Sqoop命令
sqoop import \
-Dmapreduce.job.user.classpath.first=true \
--connect jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin \
--username ciss \
--password 123456 \
--table CISS4.CISS_SERVICE_WORKORDER \
--delete-target-dir \
--target-dir /test/full_imp/ciss4.ciss_service_workorder \
--as-avrodatafile \
--fields-terminated-by "\001" \
-m 1封装脚本
#!/bin/bash
#export path
source /etc/profile
#export the tbname files
TB_NAME=/opt/datas/shell/test_full_table.txt
#export the import opt
IMP_OPT="sqoop import -
Dmapreduce.job.user.classpath.first=true"
#export the jdbc opt
JDBC_OPT="--connect
jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin --username
ciss --password 123456"
#read tbname and exec sqoop
while read tbname
do
${IMP_OPT} ${JDBC_OPT} --table ${tbname^^} --delete-target-dir --target-dir /test/full_imp/${tbname^^} --as-avrodatafile --fields-terminated-by "\001" -m 1
done < ${TB_NAME}添加执行权限
chmod u+x test_full_import_table.sh测试执行
sh -x test_full_import_table.sh检查结果
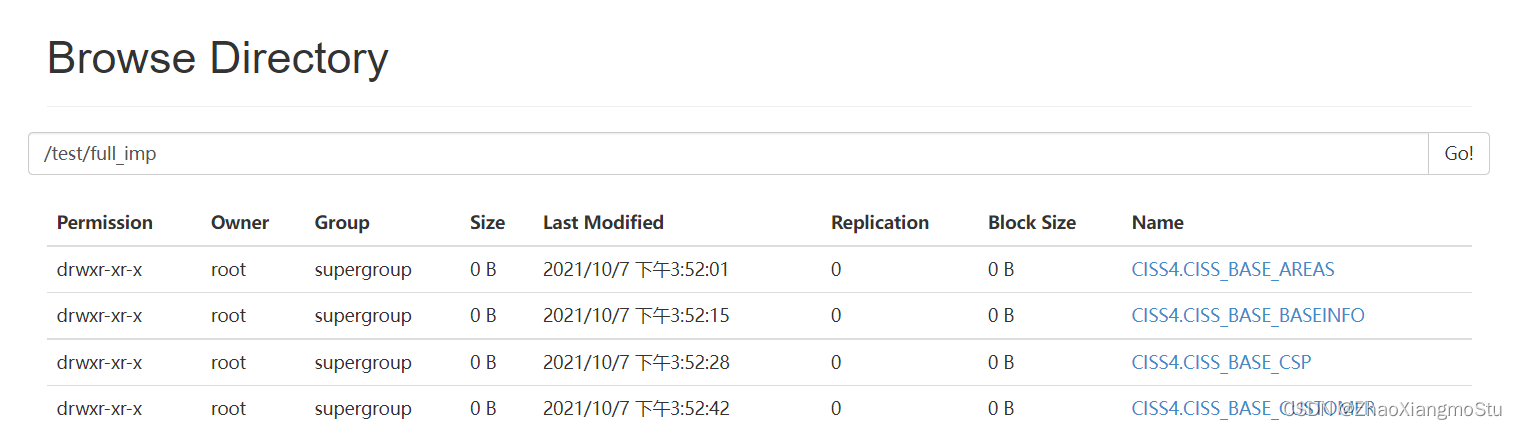
实现全量采集脚本的运行
实施
全量目标:将所有需要将实现全量采集的表进行全量采集存储到HDFS上
Oracle表:组织机构信息、地区信息、服务商信息、数据字典等
HDFS路径
/data/dw/ods/one_make/full_imp/表名/日期
增量目标:将所有需要将实现全量采集的表进行增量采集存储到HDFS上
工单数据信息、呼叫中心信息、物料仓储信息、报销费用信息等
HDFS路径
/data/dw/ods/one_make/incr_imp/表名/日期
导入全量表
#!/usr/bin/env bash
# /bin/bash
biz_date=20210101
biz_fmt_date=2021-01-01
dw_parent_dir=/data/dw/ods/one_make/full_imp
workhome=/opt/sqoop/one_make
full_imp_tables=${workhome}/full_import_tables.txt
mkdir ${workhome}/log
orcl_srv=oracle.bigdata.cn
orcl_port=1521
orcl_sid=helowin
orcl_user=ciss
orcl_pwd=123456
sqoop_import_params="sqoop import -Dmapreduce.job.user.classpath.first=true --outdir ${workhome}/java_code --as-avrodatafile"
sqoop_jdbc_params="--connect jdbc:oracle:thin:@${orcl_srv}:${orcl_port}:${orcl_sid} --username ${orcl_user} --password ${orcl_pwd}"
# load hadoop/sqoop env
source /etc/profile
while read p; do
# parallel execution import
${sqoop_import_params} ${sqoop_jdbc_params} --target-dir ${dw_parent_dir}/${p}/${biz_date} --table ${p^^} -m 1 &
cur_time=`date "+%F %T"`
echo "${cur_time}: ${sqoop_import_params} ${sqoop_jdbc_params} --target-dir ${dw_parent_dir}/${p}/${biz_date} --table ${p} -m 1 &" >> ${workhome}/log/${biz_fmt_date}_full_imp.log
sleep 30
done < ${full_imp_tables}运行脚本
全量采集
cd /opt/sqoop/one_make
sh -x full_import_tables.sh脚本中特殊的一些参数
--outdir:Sqoop解析出来的MR的Java程序等输出文件输出的文件
导入增量表
#!/usr/bin/env bash
# 编写SHELL脚本的时候要特别小心,特别是编写SQL的条件,如果中间加了空格,就会导致命令执行失败
# /bin/bash
biz_date=20210101
biz_fmt_date=2021-01-01
dw_parent_dir=/data/dw/ods/one_make/incr_imp
workhome=/opt/sqoop/one_make
incr_imp_tables=${workhome}/incr_import_tables.txt
orcl_srv=oracle.bigdata.cn
orcl_port=1521
orcl_sid=helowin
orcl_user=ciss
orcl_pwd=123456
mkdir ${workhome}/log
sqoop_condition_params="--where \"'${biz_fmt_date}'=to_char(CREATE_TIME,'yyyy-mm-dd')\""
sqoop_import_params="sqoop import -Dmapreduce.job.user.classpath.first=true --outdir ${workhome}/java_code --as-avrodatafile"
sqoop_jdbc_params="--connect jdbc:oracle:thin:@${orcl_srv}:${orcl_port}:${orcl_sid} --username ${orcl_user} --password ${orcl_pwd}"
# load hadoop/sqoop env
source /etc/profile
while read p; do
# clean old directory in HDFS
hdfs dfs -rm -r ${dw_parent_dir}/${p}/${biz_date}
# parallel execution import
${sqoop_import_params} ${sqoop_jdbc_params} --target-dir ${dw_parent_dir}/${p}/${biz_date} --table ${p^^} ${sqoop_condition_params} -m 1 &
cur_time=`date "+%F %T"`
echo "${cur_time}: ${sqoop_import_params} ${sqoop_jdbc_params} --target-dir ${dw_parent_dir}/${p}/${biz_date} --table ${p} ${sqoop_condition_params} -m 1 &" >> ${workhome}/log/${biz_fmt_date}_incr_imp.log
sleep 30
done < ${incr_imp_tables}增量采集
cd /opt/sqoop/one_make
sh -x incr_import_tables.sh特殊问题
因oracle表特殊字段类型,导致sqoop导数据任务失败
oracle字段类型为: clob或date等特殊类型
解决方案:在sqoop命令中添加参数,指定特殊类型字段列(SERIAL_NUM)的数据类型为string
—map-column-java SERIAL_NUM=String
查看结果
/data/dw/ods/one_make/full_imp:44张表
/data/dw/ods/one_make/incr_imp:57张表
Schema备份及上传
目标:了解如何实现采集数据备份
实施
需求:将每张表的Schema进行上传到HDFS上,归档并且备份
Avro文件本地存储
workhome=/opt/sqoop/one_make
--outdir ${workhome}/java_codeAvro文件HDFS存储
hdfs_schema_dir=/data/dw/ods/one_make/avsc
hdfs dfs -put ${workhome}/java_code/*.avsc ${hdfs_schema_dir}Avro文件本地打包
local_schema_backup_filename=schema_${biz_date}.tar.gz
tar -czf ${local_schema_backup_filename} ./java_code/*.avscAvro文件HDFS备份
hdfs_schema_backup_filename=${hdfs_schema_dir}/avro_schema_${biz_date
}.tar.gz
hdfs dfs -put ${local_schema_backup_filename}
${hdfs_schema_backup_filename}上传avro schema sh代码
#!/usr/bin/env bash
# 上传
# /bin/bash
workhome=/opt/sqoop/one_make
hdfs_schema_dir=/data/dw/ods/one_make/avsc
biz_date=20210101
biz_fmt_date=2021-01-01
local_schema_backup_filename=schema_${biz_date}.tar.gz
hdfs_schema_backup_filename=${hdfs_schema_dir}/avro_schema_${biz_date}.tar.gz
log_file=${workhome}/log/upload_avro_schema_${biz_fmt_date}.log
# 打印日志
log() {
cur_time=`date "+%F %T"`
echo "${cur_time} $*" >> ${log_file}
}
source /etc/profile
cd ${workhome}
# hadoop fs [generic options] [-test -[defsz] <path>]
# -test -[defsz] <path> :
# Answer various questions about <path>, with result via exit status.
# -d return 0 if <path> is a directory.
# -e return 0 if <path> exists.
# -f return 0 if <path> is a file.
# -s return 0 if file <path> is greater than zero bytes in size.
# -z return 0 if file <path> is zero bytes in size, else return 1.
log "Check if the HDFS Avro schema directory ${hdfs_schema_dir}..."
hdfs dfs -test -e ${hdfs_schema_dir} > /dev/null
if [ $? != 0 ]; then
log "Path: ${hdfs_schema_dir} is not exists. Create a new one."
log "hdfs dfs -mkdir -p ${hdfs_schema_dir}"
hdfs dfs -mkdir -p ${hdfs_schema_dir}
fi
log "Check if the file ${hdfs_schema_dir}/CISS4_CISS_BASE_AREAS.avsc has uploaded to the HFDS..."
hdfs dfs -test -e ${hdfs_schema_dir}/CISS4_CISS_BASE_AREAS.avsc.avsc > /dev/null
if [ $? != 0 ]; then
log "Upload all the .avsc schema file."
log "hdfs dfs -put ${workhome}/java_code/*.avsc ${hdfs_schema_dir}"
hdfs dfs -put ${workhome}/java_code/*.avsc ${hdfs_schema_dir}
fi
# backup
log "Check if the backup tar.gz file has generated in the local server..."
if [ ! -e ${local_schema_backup_filename} ]; then
log "package and compress the schema files"
log "tar -czf ${local_schema_backup_filename} ./java_code/*.avsc"
tar -czf ${local_schema_backup_filename} ./java_code/*.avsc
fi
log "Check if the backup tar.gz file has upload to the HDFS..."
hdfs dfs -test -e ${hdfs_schema_backup_filename} > /dev/null
if [ $? != 0 ]; then
log "upload the schema package file to HDFS"
log "hdfs dfs -put ${local_schema_backup_filename} ${hdfs_schema_backup_filename}"
hdfs dfs -put ${local_schema_backup_filename} ${hdfs_schema_backup_filename}
fi运行测试
cd /opt/sqoop/one_make/
./upload_avro_schema.sh验证结果
/data/dw/ods/one_make/avsc/
*.avsc
schema_20210101.tar.gz使用Python脚本如何实现
导入全量表
#!/usr/bin/env python
# @Time : 2021/7/14 15:34
# @desc :
__coding__ = "utf-8"
__author__ = "itcast"
import os
import subprocess
import datetime
import time
import logging
biz_date = '20210101'
biz_fmt_date = '2021-01-01'
dw_parent_dir = '/data/dw/ods/one_make/full_imp'
workhome = '/opt/sqoop/one_make'
full_imp_tables = workhome + '/full_import_tables.txt'
if os.path.exists(workhome + '/log'):
os.system('make ' + workhome + '/log')
orcl_srv = 'oracle.bigdata.cn'
orcl_port = '1521'
orcl_sid = 'helowin'
orcl_user = 'ciss'
orcl_pwd = '123456'
sqoop_import_params = 'sqoop import -Dmapreduce.job.user.classpath.first=true --outdir %s/java_code --as-avrodatafile' % workhome
sqoop_jdbc_params = '--connect jdbc:oracle:thin:@%s:%s:%s --username %s --password %s' % (orcl_srv, orcl_port, orcl_sid, orcl_user, orcl_pwd)
# load hadoop/sqoop env
subprocess.call("source /etc/profile", shell=True)
print('executing...')
# read file
fr = open(full_imp_tables)
for line in fr.readlines():
tblName = line.rstrip('\n')
# parallel execution import
# ${sqoop_import_params} ${sqoop_jdbc_params} --target-dir ${dw_parent_dir}/${p}/${biz_date} --table ${p^^} -m 1 &
# sqoopImportCommand = f''' {sqoop_import_params} {sqoop_jdbc_params} --target-dir {dw_parent_dir}/{tblName}/{biz_date} --table {tblName.upper()} -m 1 &'''
sqoopImportCommand = '''
%s %s --target-dir %s/%s/%s --table %s -m 1 &
''' % (sqoop_import_params, sqoop_jdbc_params, dw_parent_dir, tblName, biz_date, tblName.upper())
# parallel execution import
subprocess.call(sqoopImportCommand, shell=True)
# cur_time=`date "+%F %T"`
# cur_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
logging.basicConfig(level=logging.INFO, # 控制台打印的日志级别
filename='%s/log/%s_full_imp.log' % (workhome, biz_fmt_date),
# 模式,有w和a,w就是写模式,每次都会重新写日志,覆盖之前的日志; a是追加模式,默认如果不写的话,就是追加模式
filemode='a',
# 日志格式
format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s')
# logging.info(cur_time + ' : ' + sqoopImportCommand)
logging.info(sqoopImportCommand)
time.sleep(15)
导入增量表
#!/usr/bin/env python
# @Time : 2021/7/20 15:19
# @desc :
__coding__ = "utf-8"
__author__ = "itcast"
import os
import subprocess
import datetime
import time
import logging
biz_date = '20210101'
biz_fmt_date = '2021-01-01'
dw_parent_dir = '/data/dw/ods/one_make/incr_imp'
workhome = '/opt/sqoop/one_make'
incr_imp_tables = workhome + '/incr_import_tables.txt'
if os.path.exists(workhome + '/log'):
os.system('make ' + workhome + '/log')
orcl_srv = 'oracle.bigdata.cn'
orcl_port = '1521'
orcl_sid = 'helowin'
orcl_user = 'ciss'
orcl_pwd = '123456'
sqoop_import_params = 'sqoop import -Dmapreduce.job.user.classpath.first=true --outdir %s/java_code --as-avrodatafile' % workhome
sqoop_jdbc_params = '--connect jdbc:oracle:thin:@%s:%s:%s --username %s --password %s' % (orcl_srv, orcl_port, orcl_sid, orcl_user, orcl_pwd)
# load hadoop/sqoop env
subprocess.call("source /etc/profile", shell=True)
print('executing...')
# read file
fr = open(incr_imp_tables)
for line in fr.readlines():
tblName = line.rstrip('\n')
# clean old directory in HDFS
hdfs_command = 'hdfs dfs -rm -r %s/%s/%s' % (dw_parent_dir, tblName, biz_date)
# parallel execution import
# ${sqoop_import_params} ${sqoop_jdbc_params} --target-dir ${dw_parent_dir}/${p}/${biz_date} --table ${p^^} -m 1 &
# sqoopImportCommand = f''' {sqoop_import_params} {sqoop_jdbc_params} --target-dir {dw_parent_dir}/{tblName}/{biz_date} --table {tblName.upper()} -m 1 &'''
sqoopImportCommand = '''
%s %s --target-dir %s/%s/%s --table %s -m 1 &
''' % (sqoop_import_params, sqoop_jdbc_params, dw_parent_dir, tblName, biz_date, tblName.upper())
# parallel execution import
subprocess.call(sqoopImportCommand, shell=True)
# cur_time=`date "+%F %T"`
# cur_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
logging.basicConfig(level=logging.INFO,
filename='%s/log/%s_full_imp.log' % (workhome, biz_fmt_date),
filemode='a',
format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s')
# logging.info(cur_time + ' : ' + sqoopImportCommand)
logging.info(sqoopImportCommand)
time.sleep(15)
导入avro schema
#!/usr/bin/env python
# @Time : 2021/7/20 15:46
# @desc :
__coding__ = "utf-8"
__author__ = "itcast"
# import pyhdfs
import logging
import os
workhome = '/opt/sqoop/one_make'
hdfs_schema_dir = '/data/dw/ods/one_make/avsc'
biz_date = '20210101'
biz_fmt_date = '2021-01-01'
local_schema_backup_filename = 'schema_%s.tar.gz' % biz_date
hdfs_schema_backup_filename = '%s/avro_schema_%s.tar.gz' % (hdfs_schema_dir, biz_date)
log_file = '%s/log/upload_avro_schema_%s.log' % (workhome, biz_fmt_date)
# append log to file
logging.basicConfig(level=logging.INFO,
filename=log_file,
filemode='a',
format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s')
os.system('source /etc/profile')
os.system('cd %s' % workhome)
# hadoop fs [generic options] [-test -[defsz] <path>]
# -test -[defsz] <path> :
# Answer various questions about <path>, with result via exit status.
# -d return 0 if <path> is a directory.
# -e return 0 if <path> exists.
# -f return 0 if <path> is a file.
# -s return 0 if file <path> is greater than zero bytes in size.
# -z return 0 if file <path> is zero bytes in size, else return 1.
logging.info('Check if the HDFS Avro schema directory %s...', hdfs_schema_dir)
# hdfs = pyhdfs.HdfsClient(hosts="node1,9000", user_name="hdfs")
# print(hdfs.listdir('/'))
# hdfs dfs -test -e ${hdfs_schema_dir} > /dev/null
commStatus = os.system('hdfs dfs -test -e %s > /dev/null' % hdfs_schema_dir)
if commStatus is not 0:
logging.info('Path: %s is not exists. Create a new one.', hdfs_schema_dir)
logging.info('hdfs dfs -mkdir -p %s', hdfs_schema_dir)
os.system('hdfs dfs -mkdir -p %s' % hdfs_schema_dir)
logging.info('Check if the file %s/CISS4_CISS_BASE_AREAS.avsc has uploaded to the HFDS...', hdfs_schema_dir)
commStatus = os.system('hdfs dfs -test -e %s/CISS4_CISS_BASE_AREAS.avsc > /dev/null' % hdfs_schema_dir)
if commStatus is not 0:
logging.info('Upload all the .avsc schema file.')
logging.info('hdfs dfs -put %s/java_code/*.avsc %s', workhome, hdfs_schema_dir)
os.system('hdfs dfs -put %s/java_code/*.avsc %s' % (workhome, hdfs_schema_dir))
# backup
logging.info('Check if the backup tar.gz file has generated in the local server...')
commStatus = os.system('[ -e %s ]' % local_schema_backup_filename)
if commStatus is not 0:
logging.info('package and compress the schema files')
logging.info('tar -czf %s ./java_code/*.avsc', local_schema_backup_filename)
os.system('tar -czf %s ./java_code/*.avsc' % local_schema_backup_filename)
logging.info('Check if the backup tar.gz file has upload to the HDFS...')
commStatus = os.system('hdfs dfs -test -e %s > /dev/null' % hdfs_schema_backup_filename)
if commStatus is not 0:
logging.info('upload the schema package file to HDFS')
logging.info('hdfs dfs -put %s %s', local_schema_backup_filename, hdfs_schema_backup_filename)
os.system('hdfs dfs -put %s %s' %(local_schema_backup_filename, hdfs_schema_backup_filename))