少样本学习与零样本学习:理解与应用
在现代机器学习领域中,少样本学习(Few-Shot Learning)和零样本学习(Zero-Shot Learning)正变得越来越重要。这些技术能够在数据稀缺的情况下有效地进行学习和推理,从而突破传统机器学习对大规模标注数据的依赖。本文将详细介绍少样本学习和零样本学习的概念、原理、方法以及应用场景,帮助读者全面理解这两个领域的前沿技术。
一、少样本学习
1. 概念
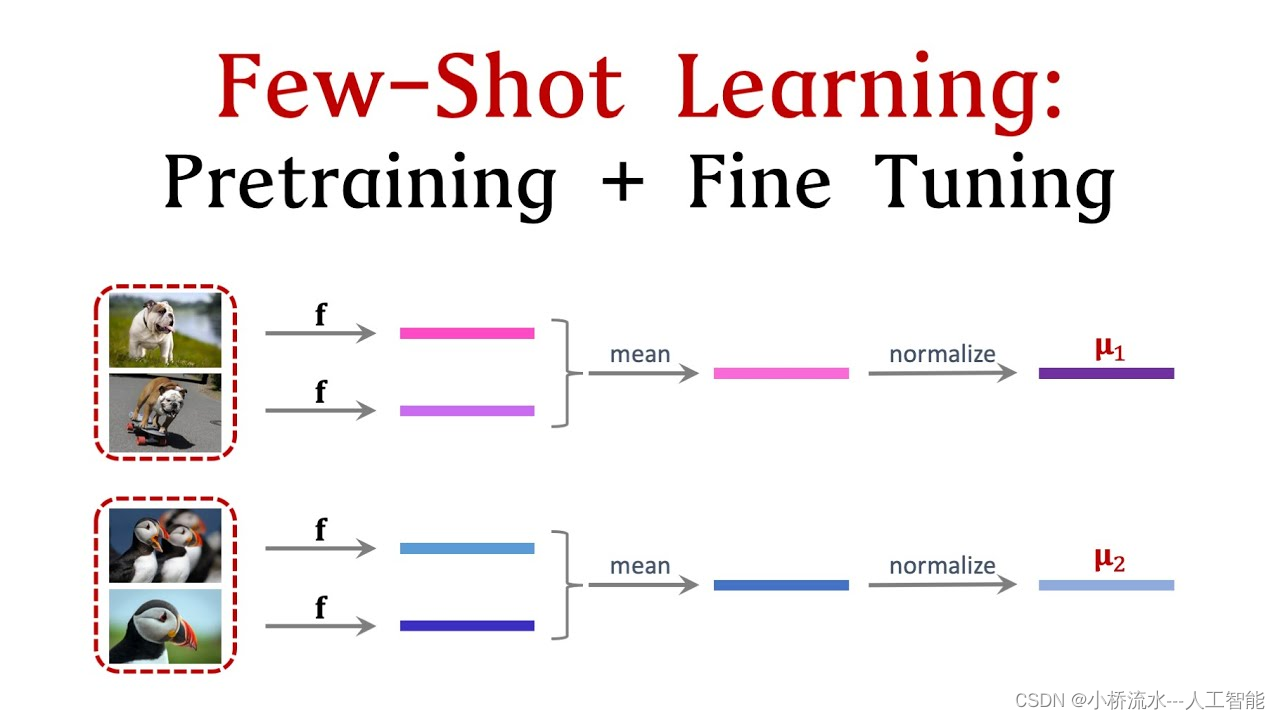
**少样本学习(Few-Shot Learning, FSL)**是指在仅有少量标注样本的情况下,训练模型以实现良好的泛化能力。传统机器学习模型通常依赖于大量的标注数据来进行训练,而少样本学习则在数据稀缺的情况下依然能够有效地进行学习。
2. 原理
少样本学习的核心思想是通过利用先验知识和迁移学习,从相似任务中获取有用的信息,从而在新任务上进行有效学习。常见的方法包括:
- 元学习(Meta-Learning):通过学习如何学习,模型在多个任务上进行训练,从而在少量新任务的数据上迅速适应。
- 数据增强(Data Augmentation):通过生成更多的合成数据,增加样本的多样性,提高模型的泛化能力。
- 特征提取(Feature Extraction):通过预训练模型提取特征,利用这些特征在新任务上进行分类。
3. 方法
少样本学习常用的方法包括:
- 基于原型网络(Prototypical Networks):通过计算样本与原型之间的距离来进行分类。
- 基于匹配网络(Matching Networks):通过注意力机制,计算样本与支持集之间的相似性进行分类。
- 基于度量学习(Metric Learning):通过学习一个度量空间,使得相似样本距离更近,不同样本距离更远。
4. 应用场景
少样本学习在许多实际应用中具有重要意义,包括但不限于:
- 医疗诊断:医学数据通常稀缺且标注昂贵,少样本学习可以在少量病例数据上进行有效学习。
- 机器人控制:在少量交互数据上,机器人可以通过少样本学习迅速适应新任务。
- 自然语言处理:少样本学习可以在少量文本数据上进行语义理解和生成。
二、零样本学习
1. 概念
**零样本学习(Zero-Shot Learning, ZSL)**是指在没有任何标注样本的情况下,训练模型实现对新类别的识别和分类。零样本学习通过利用先验知识,如语义信息或属性描述,实现对新类别的泛化能力。
2. 原理
零样本学习的核心思想是通过利用辅助信息,如类别的语义描述或属性向量,将新类别映射到已知类别的特征空间中,从而实现分类。常见的方法包括:
- 基于属性的学习(Attribute-Based Learning):通过学习类别的属性描述,模型可以在没有标注样本的情况下进行分类。
- 基于语义嵌入(Semantic Embeddings):通过将类别名称或描述映射到向量空间,实现对新类别的识别。
- 基于生成模型(Generative Models):通过生成新类别的合成数据,进行分类任务。
3. 方法
零样本学习常用的方法包括:
- 属性嵌入(Attribute Embedding):通过学习类别的属性向量,将新类别映射到已知类别的特征空间中。
- 语义嵌入(Semantic Embedding):通过将类别的语义描述映射到向量空间,进行分类任务。
- 生成对抗网络(Generative Adversarial Networks, GANs):通过生成新类别的合成数据,进行分类任务。
4. 应用场景
零样本学习在许多实际应用中同样具有重要意义,包括但不限于:
- 图像识别:在没有新类别的标注样本的情况下,通过零样本学习实现新类别的识别。
- 文本分类:在没有新类别的标注文本的情况下,通过零样本学习实现新类别的分类。
- 推荐系统:在没有新用户或新物品的历史数据的情况下,通过零样本学习实现个性化推荐。
三、少样本学习与零样本学习的联系与区别
联系
少样本学习和零样本学习都旨在解决数据稀缺问题,通过利用先验知识和辅助信息,实现模型的泛化能力。两者都可以通过迁移学习和特征提取等技术,从已有数据中获取有用的信息,应用于新任务中。
区别
- 数据需求:少样本学习需要少量的标注样本,而零样本学习在新类别上不需要任何标注样本。
- 方法:少样本学习通常通过元学习、数据增强和度量学习等方法实现,而零样本学习通过属性嵌入、语义嵌入和生成模型等方法实现。
- 应用场景:少样本学习更适用于有少量标注数据的任务,而零样本学习更适用于完全没有标注数据的新类别识别任务。
结论
少样本学习和零样本学习是解决数据稀缺问题的重要技术,它们通过利用先验知识和辅助信息,实现模型的泛化能力。在实际应用中,这些技术在医疗诊断、机器人控制、自然语言处理、图像识别、文本分类和推荐系统等领域中具有广泛的应用前景。理解并掌握这些技术,将有助于应对数据稀缺带来的挑战,提升机器学习模型的性能和应用范围。