K-均值聚类算法(K-means clustering algorithm)是一种经典的聚类分析方法,在机器学习中应用广泛。该算法的目标是将n个数据点划分为k个簇(Cluster),使得每个数据点都属于离它最近的簇中心所代表的簇,并且同一个簇中的数据点之间的相似度较高,不同簇中的数据点相似度较低。
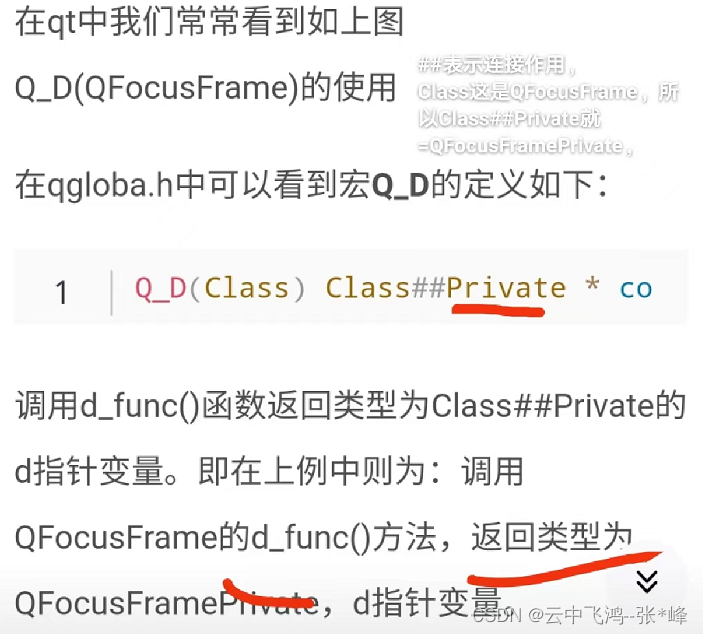
算法步骤
- 初始化:随机选择k个数据点作为初始簇中心。
- 分配数据点:对于每一个数据点,计算其与各个簇中心的距离,并将其分配到最近的簇中心所在的簇。
- 更新簇中心:重新计算每个簇的数据点的平均值,作为新的簇中心。
- 重复迭代:重复步骤2和3,直至满足停止条件,如簇中心的变化小于某个阈值,或者达到预设的迭代次数。
优点
- 简单易实现:算法思想简单,容易理解,并且能够通过较少的计算量快速实现。
- 适合大规模数据处理:K-均值算法能够处理大规模的数据集,且收敛速度快。
- 结果可解释性强:聚类结果可以清晰地展示数据的分布情况,每个簇中心代表了一类数据的特征。
缺点
- 对初始中心敏感:K-均值算法对初始选择的簇中心非常敏感,不同的初始中心可能会导致不同的聚类结果。
- 预设簇数k:在实际应用中,需要事先指定簇数k,但在很多情况下,k的值是未知的,需要通过其他方法估计。
- 可能收敛到局部最优:K-均值算法可能收敛到局部最优解,而不是全局最优解。
- 对噪声和离群点敏感:离群点可能会对簇中心的计算产生较大影响,导致聚类效果不佳。
- 假设簇形状为球形:K-均值算法假设簇的形状为球形,这在很多情况下并不适用,尤其是当簇的形状复杂或者大小差异很大时。
应用场景
尽管有上述缺点,K-均值聚类算法由于其简单高效的特点,在数据挖掘、图像处理、市场细分、城市规划等多个领域都有广泛的应用。在使用时,通常会结合领域知识和实际需求,通过多次实验来确定合适的簇数k和初始簇中心的选择方法,以获得最佳的聚类效果。