01. Flink 简介
1、Flink 是什么
Flink 官网地址:https://flink.apache.org
Flink 核心目标,是 数据流上的有状态计算。
Apache Flink是一个开源的流处理框架,用于实时数据流的处理和分析。它最初由柏林工业大学的研究人员开发,并在2014年成为Apache软件基金会的一个顶级项目。
Flink提供了以下主要功能:
- 流处理:Flink可以处理无界和有界的数据流,支持复杂的事件时间处理和状态管理。
- 批处理:Flink的批处理功能可以与流处理无缝集成,使得批处理任务可以像流处理任务一样高效。
- 事件驱动应用:Flink支持构建事件驱动的应用程序,可以处理来自各种源的事件,如消息队列、日志文件等。
- 容错性:Flink提供了强大的容错机制,能够在节点故障时保证数据处理的一致性和准确性。
- 可伸缩性:Flink设计为高度可伸缩,可以从单个应用扩展到数千个核心。
- 低延迟:Flink能够以毫秒级的延迟处理数据,适合需要实时响应的应用程序。
- 丰富的API和连接器:Flink提供了多种编程API(如DataStream API、Table API和SQL API)和连接器,可以方便地与各种数据源和存储系统进行集成。
- 支持多种编程语言:虽然Flink主要是用Java编写的,但它也支持Scala、Python等其他编程语言。
Flink广泛应用于金融、电信、电子商务等领域,用于实时数据分析、监控、事件处理等场景。
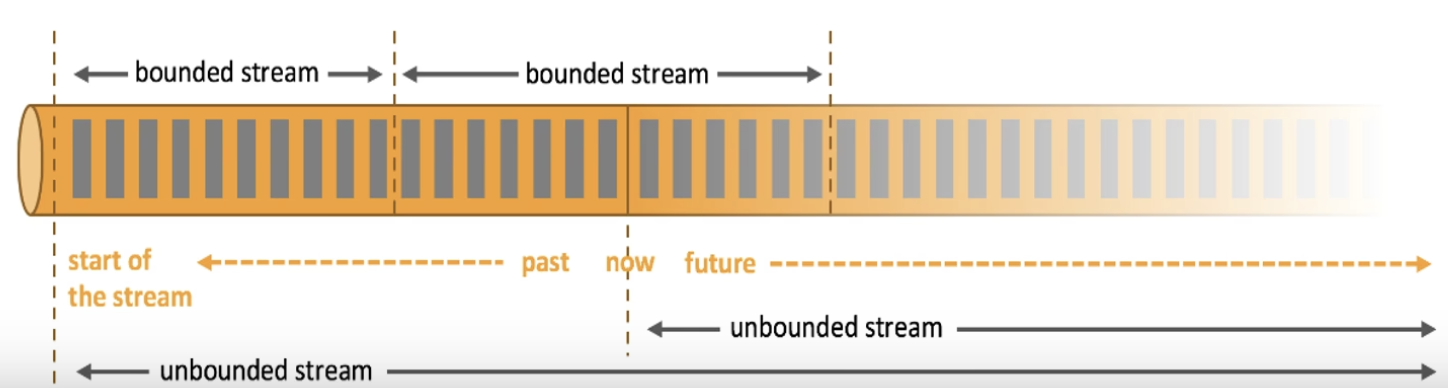
1.1 有界流和无界流
(1)有界流(Bounded Streams)
有界流指的是数据集大小有限,有明确的开始和结束。这类数据流通常对应于传统的批处理任务,它们可以被完全加载到内存中进行处理。有界流的例子包括:
- 一个数据库表中的所有记录。
- 一个固定大小的文件。
- 一个已知结束时间的日志文件。
有界流的处理通常遵循以下步骤:
- 加载数据:将所有数据加载到内存或分布式系统中。
- 处理数据:对数据进行排序、过滤、聚合等操作。
(2)无界流(Unbounded Streams)
无界流指的是数据源是持续不断的,没有明确的结束,数据可以无限地生成和流入系统。这类数据流对应于实时数据流处理任务,例如:
- 社交媒体上的实时帖子和评论。
- 实时股票交易数据。
- 物联网设备生成的传感器数据。
无界流的处理需要不同的策略:
- 持续处理:系统需要持续不断地接收和处理数据。
- 状态管理:由于数据是持续流入的,系统需要维护状态信息,以便正确处理事件。
- 容错和恢复:系统必须能够处理故障并从故障中恢复,保证数据不丢失。
- 事件时间处理:为了正确处理事件,系统需要能够处理基于事件时间的逻辑,而不仅仅是处理时间。
1.2 有状态流处理
Apache Flink是一个专为有状态的流处理而设计的分布式处理引擎,它提供了一系列的功能和优化来支持状态管理、容错性以及高效的状态操作。以下是Apache Flink有状态流处理的一些关键特性:
状态后端(State Backends):Flink提供了多种状态后端来存储和管理状态,包括本地状态后端、文件系统状态后端(如HDFS)、RocksDBStateBackend等。这些状态后端支持不同级别的持久性和性能。
状态一致性:Flink通过检查点(checkpointing)机制确保状态的一致性。检查点是Flink的容错机制,它会周期性地保存应用程序的状态快照到持久化存储中。
精确一次(Exactly-Once)语义:Flink通过检查点和恢复机制,实现了精确一次(Exactly-Once)状态更新语义,确保即使在发生故障的情况下,状态也不会丢失或重复更新。
有状态的时间窗口:Flink支持基于时间的窗口操作,如滚动窗口(tumbling windows)和滑动窗口(sliding windows)。这些窗口允许用户对数据流中的事件进行分组和聚合。
时间语义:Flink支持两种时间语义:事件时间(event time)和处理时间(processing time)。事件时间是指数据实际发生的时间,而处理时间是数据被Flink处理的时间。Flink允许用户基于事件时间来处理数据,这对于处理乱序数据和确保结果的正确性至关重要。
状态模式:Flink提供了不同的状态模式,如ValueState、ListState、ReducingState等,以支持不同类型的状态操作和访问模式。
状态演化:Flink允许开发者定义状态的演化逻辑,这意味着随着时间的推移,状态可以被更新和修改。
异步操作:Flink支持异步操作,这允许状态的更新和查询操作在不阻塞主处理线程的情况下进行,从而提高性能。
增量检查点:Flink支持增量检查点,这意味着只有状态发生变化的部分才会被保存,而不是整个状态的完整副本,这可以显著减少检查点的开销。
可扩展性:Flink的有状态流处理能力是高度可扩展的,可以从单节点扩展到数千个节点,以处理大规模的数据流。
API支持:Flink提供了DataStream API和Table API/SQL API,这些API都支持有状态的操作,使得开发者可以方便地构建有状态的流处理应用。
通过这些特性,Apache Flink能够支持复杂的有状态流处理应用,无论是需要处理有界数据集的批处理任务,还是需要处理无界数据流的实时分析和监控任务。
1.3 Flink 的发展历程
Apache Flink的发展历史可以追溯到2010年,最初作为一个研究项目在德国柏林工业大学启动。以下是Flink发展的主要里程碑:
Stratosphere项目:Flink最初被称为Stratosphere,这是一个研究项目,旨在开发下一代大数据分析平台。
Apache孵化器:2014年3月,Flink作为Stratosphere的一个分支,以版本v0.9的身份成为Apache孵化器项目。
Apache顶级项目:同年12月,Flink被接受为Apache的顶级项目,并在2015年发布了第一个版本v0.9.1。
流式处理支持:随着大数据和实时数据处理需求的增长,Flink在其后续版本中加入了对流式处理的支持,使用户可以使用相同的框架来处理批处理任务和实时流式任务。
功能扩展:Flink不断发展,引入了许多扩展功能,如复杂事件处理、图计算、机器学习等,使其成为一个全面且功能强大的大数据处理框架。
阿里巴巴的Blink:2015年,阿里巴巴开始尝试使用Flink,并基于此构建了Blink计算平台。Blink是Flink的一个改进版本,提供了更好的性能和更多的功能,广泛应用于流式数据处理、离线数据处理、DataLake计算等场景。
Blink开源:2019年1月,阿里云宣布将Blink开源给Apache Flink社区,之后Blink的代码被逐步合并到Flink的主分支上,成为Flink的一部分。
Flink 2.0:预计在Flink项目的第一个十周年(2024年)时,Flink社区将发布Flink-2.0,这将是一个新的里程碑,包括彻底的云原生存算分离架构,业界一流的批处理能力,以及完整的流批融合能力。
Apache Flink CDC:阿里云独立开源的Flink CDC实时数据集成项目也已经正式开启捐献工作,预计将正式成为Apache Flink官方子项目。
Apache Paimon:从Flink社区中孵化出来的新项目,定位为流批一体实时数据湖格式,解决Lakehouse数据实时化的问题。
这些发展里程碑展示了Flink从一个研究项目成长为业界领先的实时大数据处理框架的过程。随着不断的技术创新和社区贡献,Flink继续在实时数据处理和分析领域发挥着重要作用。
2、Flink 的特点
Apache Flink是一个强大的开源流处理框架,具有以下一些显著的特点:
- 实时流处理:Flink专为实时数据处理设计,能够以极低的延迟处理无界数据流。
- 高吞吐和低延迟:每秒处理数百万个事件,毫秒级延迟。
- 批流一体:Flink提供了统一的API,可以同时处理批处理作业和流处理作业,使得开发者能够使用相同的逻辑来处理不同类型的数据。
- 有状态的计算:Flink支持有状态的流处理,允许在流处理过程中维护状态信息,这对于事件驱动的复杂应用至关重要。
- 容错性:Flink通过检查点(Checkpointing)和保存点(Savepoints)机制提供了强大的容错能力,确保了状态的一致性和精确一次(Exactly-Once)语义。
- 可伸缩性:Flink设计为高度可伸缩,可以从单台机器扩展到数千个核心,支持大规模数据处理。
- 丰富的API:Flink提供了多种编程API,包括DataStream API、Table API和SQL API,支持Java、Scala、Python等多种编程语言。
- 多种状态后端:Flink支持多种状态后端,如RocksDB、FsStateBackend等,以适应不同的性能和持久性需求。
- 时间语义:Flink支持事件时间(Event Time)和处理时间(Processing Time)两种时间语义,允许开发者根据业务需求选择最合适的时间处理策略。
- 窗口操作:Flink提供了丰富的窗口操作,包括滚动窗口(Tumbling Windows)、滑动窗口(Sliding Windows)和会话窗口(Session Windows)等。
- 异步I/O:Flink支持异步非阻塞I/O操作,可以提高网络和磁盘I/O的性能。
- 轻量级快照:Flink的增量检查点(Incremental Checkpointing)机制可以减少检查点的开销,提高系统的吞吐量。
- 事件驱动的应用:Flink支持构建事件驱动的应用,可以处理来自各种源的事件,如消息队列、日志文件等。
- 可插拔的序列化框架:Flink支持多种序列化框架,如Apache Avro、Kryo、Protobuf等,允许开发者选择最适合自己需求的序列化方式。
- 连接器和集成:Flink提供了多种连接器,可以方便地与各种外部系统(如Kafka、HDFS、HBase等)进行集成。
- 机器学习库:FlinkML是Flink的一个机器学习库,提供了流数据上的机器学习算法。
- Flink Table Store:Flink Table Store是Flink的一个新特性,它提供了一种方式来存储和管理流处理中的状态,使得状态的存储和访问更加高效。
- 云原生支持:Flink支持云原生部署,可以很容易地在各种云平台上运行。
这些特点使得Flink成为一个功能全面、性能优越的流处理框架,适用于各种复杂的实时数据处理场景。
3、 Flink 和 SparkStreaming 对比
Apache Flink和Spark Streaming都是大数据处理框架,它们在实时流处理和批处理方面有着广泛的应用。以下是Flink和Spark Streaming的一些主要区别以及各自的优缺点:
3.1 Flink与Spark Streaming的区别:
运行角色:
- Spark Streaming:包括Master、Worker、Driver和Executor等角色。
- Flink:包括JobManager、TaskManager和Slot等角色。
编程模型:
- Spark Streaming:基于微批处理,将数据分成小批次进行处理。
- Flink:事件驱动,数据流逐条处理,提供真正的流处理能力。
任务调度原理:
- Spark Streaming:基于微批处理,每个批次都是一个Spark Core的任务。
- Flink:数据流由Source到Sink顺序执行,拓扑结构固定。
时间机制:
- Spark Streaming:主要支持处理时间,Structured Streaming支持处理时间和事件时间。
- Flink:支持事件时间、注入时间和处理时间三种时间机制。
Kafka动态分区检测:
- Spark Streaming:与Kafka 0.10版本结合支持动态分区检测。
- Flink:能够动态发现Kafka新增分区,但需要配置相关属性。
容错机制及处理语义:
- Spark Streaming:通过checkpoint和offset提交保证数据不丢失,但可能重复处理。
- Flink:使用两阶段提交协议保证精确一次处理语义。
背压机制:
- Spark Streaming:通过PID控制器调节消费速率。
- Flink:使用基于信用的流控机制,类似于TCP的流量控制。
3.2 优缺点:
Spark Streaming:
- 优点:
- 与Spark生态系统集成良好,共享批处理和SQL能力。
- 社区成熟,有大量的用户和丰富的资源。
- 易于理解和使用,特别是对于熟悉Spark的用户。
- 缺点:
- 基于微批处理,可能不如Flink在延迟和吞吐量上表现出色。
- 容错和状态管理不如Flink灵活。
- 优点:
Flink:
- 优点:
- 提供真正的流处理能力,低延迟和高吞吐量。
- 强大的状态管理和容错能力,支持精确一次处理语义。
- 支持事件时间处理和watermark机制,适合处理乱序事件。
- 缺点:
- 相对较新的项目,社区和生态系统可能不如Spark成熟。
- 学习曲线可能更陡峭,特别是对于状态管理和API的使用。
- 优点:
在选择Flink或Spark Streaming时,需要根据具体的业务需求、数据特性、性能要求以及团队的技术栈和熟悉度来决定。两者都是强大的工具,适用于不同的场景和需求。
3.3 总结
Spark 以批处理为根本:
- Spark数据模型:Spark 采用 RDD 模型,Spark Streaming的DStream 实际上也就是一组组小批数据RDD 的集合
- Spark运行时架构:Spark 是批计算,将 DAG 划分为不同的 stage,一个完成后才可以计算下一个。

Flink 以流处理为根本:
- Flink 数据模型:Flink 基本数据模型是流数据,以及事件(Event)序列。
- Flink 运行时架构:Flink 是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。
4、Flink 的应用场景
Apache Flink 作为一个强大的流处理框架,被广泛应用于各种场景,以下是一些主要的应用场景:
实时数据计算:Flink 能够处理实时数据流,如实时监控大屏、实时销售额和销量统计、服务器负载监控等。
实时数据仓库和ETL:Flink 支持实时ETL(Extract-Transform-Load),将业务系统的数据经过抽取、清洗转换后加载到数据仓库中,并支持实时数仓的建设。
事件驱动型应用:Flink 适用于构建事件驱动的应用,如从服务器上报的消息中提取信息进行分析、触发自定义规则进行报警、识别爬虫程序并进行IP限制等。
实时风控:在金融领域,Flink 可用于实时风控系统,快速识别欺诈行为并采取相应措施。
实时推荐:Flink 可以用于实时推荐系统,根据用户行为和偏好动态推荐内容。
搜索引擎的实时索引构建:Flink 可以用于搜索引擎,实现数据的实时索引构建和更新。
实时数仓:Flink 支持构建实时数据仓库,提供实时数据查询接口,满足企业对数据实时性的需求。
实时报表:Flink 可用于实时生成业务报表,帮助企业快速获取关键业务指标。
流批一体:Flink 支持批流一体的数据处理,可以同时处理批处理作业和流处理作业,提高资源利用率和开发效率。
状态管理:Flink 提供了强大的状态管理功能,适用于需要维护复杂状态信息的流处理应用。
运行在多种资源管理框架上:Flink 支持运行在 YARN、Mesos、Kubernetes 等多种资源管理框架上,具有良好的可伸缩性和灵活性。
大规模数据处理:Flink 能够扩展到数千核心,状态可以达到TB级别,同时保持高吞吐和低延迟的特性,适合大规模数据处理。
这些应用场景展示了 Flink 在实时数据处理和分析领域的强大能力,以及其在不同行业中的广泛应用。
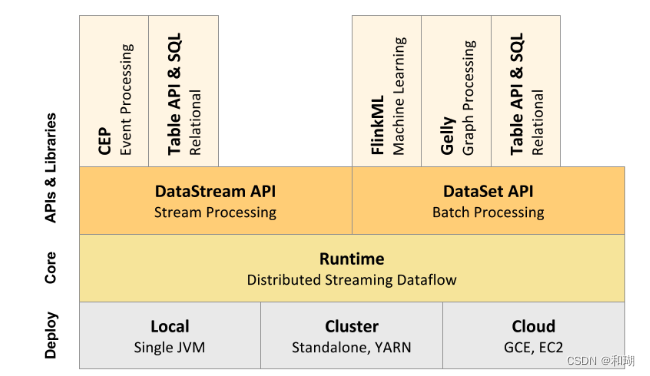
5、Flink 的分层api
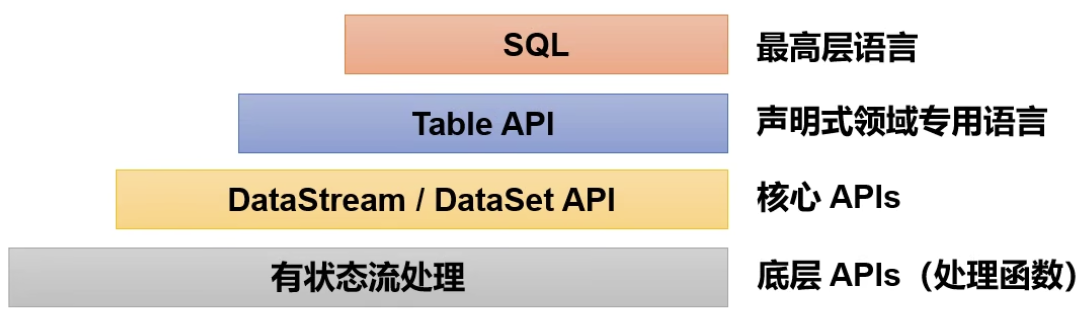
Apache Flink提供了分层的API,以适应不同层次的抽象需求,从而让开发者能够更加灵活和高效地编写流处理和批处理程序。以下是Flink的分层API的概述:
Stateful Stream Processing:位于最底层,是Flink核心API的底层实现。它提供了最基本的状态和时间管理功能,允许开发者编写有状态的流处理逻辑。这一层非常灵活,但同时也要求开发者自己管理状态的生命周期、容错和一致性等问题。
Core API:包括了
DataStreamAPI和DataSetAPI。DataStreamAPI用于构建流处理应用,而DataSetAPI用于批处理应用。这一层的API提供了常见的数据转换、分组、聚合、窗口和状态等操作,适合大多数流式和批式处理场景。Table API & SQL:构建在Table概念之上,Table可以与
DataStream或DataSet进行相互转换。Table API提供了一种声明式的数据流处理方式,允许使用类似于SQL的语句来表达复杂的数据处理逻辑。SQL构建在Table之上,不同的Table类型需要构建不同的Table环境。Streaming SQL不同于存储SQL,最终会转化为流式执行计划。ProcessFunction:是Flink提供的最具表达力的接口之一,可以处理单个事件或窗口内的多个事件。它提供了对时间和状态的细粒度控制,允许开发者在其中任意修改状态,并注册定时器以在未来某一时刻触发回调函数。
ProcessFunction非常适合实现基于单个事件的复杂业务逻辑。CEP (Complex Event Processing):Flink提供了一个用于复杂事件处理的库,允许开发者定义和识别事件模式,并基于这些模式触发特定的操作。
FlinkML (Machine Learning):是Flink的一个机器学习库,提供了流数据上的机器学习算法。
Gelly (Graph Processing):是Flink的图处理库,提供了图算法的实现,如迭代图算法等。
Flink的分层API设计允许开发者根据具体需求选择合适的抽象层次,从而在灵活性和开发效率之间取得平衡。通过这些API,Flink能够支持广泛的数据处理应用,包括实时分析、事件驱动应用、机器学习等。
![[<span style='color:red;'>Flink</span><span style='color:red;'>01</span>] 了解<span style='color:red;'>Flink</span>](https://img-blog.csdnimg.cn/img_convert/2986668a27ab8b3560e8d3595371f3a9.png)
![[<span style='color:red;'>Flink</span><span style='color:red;'>03</span>] <span style='color:red;'>Flink</span>安装](https://img-blog.csdnimg.cn/img_convert/b458d17dfc54eada02a4f9e51e92e9f8.png)
![[<span style='color:red;'>Flink</span><span style='color:red;'>04</span>] <span style='color:red;'>Flink</span>部署实践](https://img-blog.csdnimg.cn/direct/a872a60512d84b398452ec3704d89036.png)



























![[国产大模型简单使用介绍] 开源与免费API](https://img-blog.csdnimg.cn/img_convert/6b0671c29fd0501b7dcfb4aeb9863cb9.png)