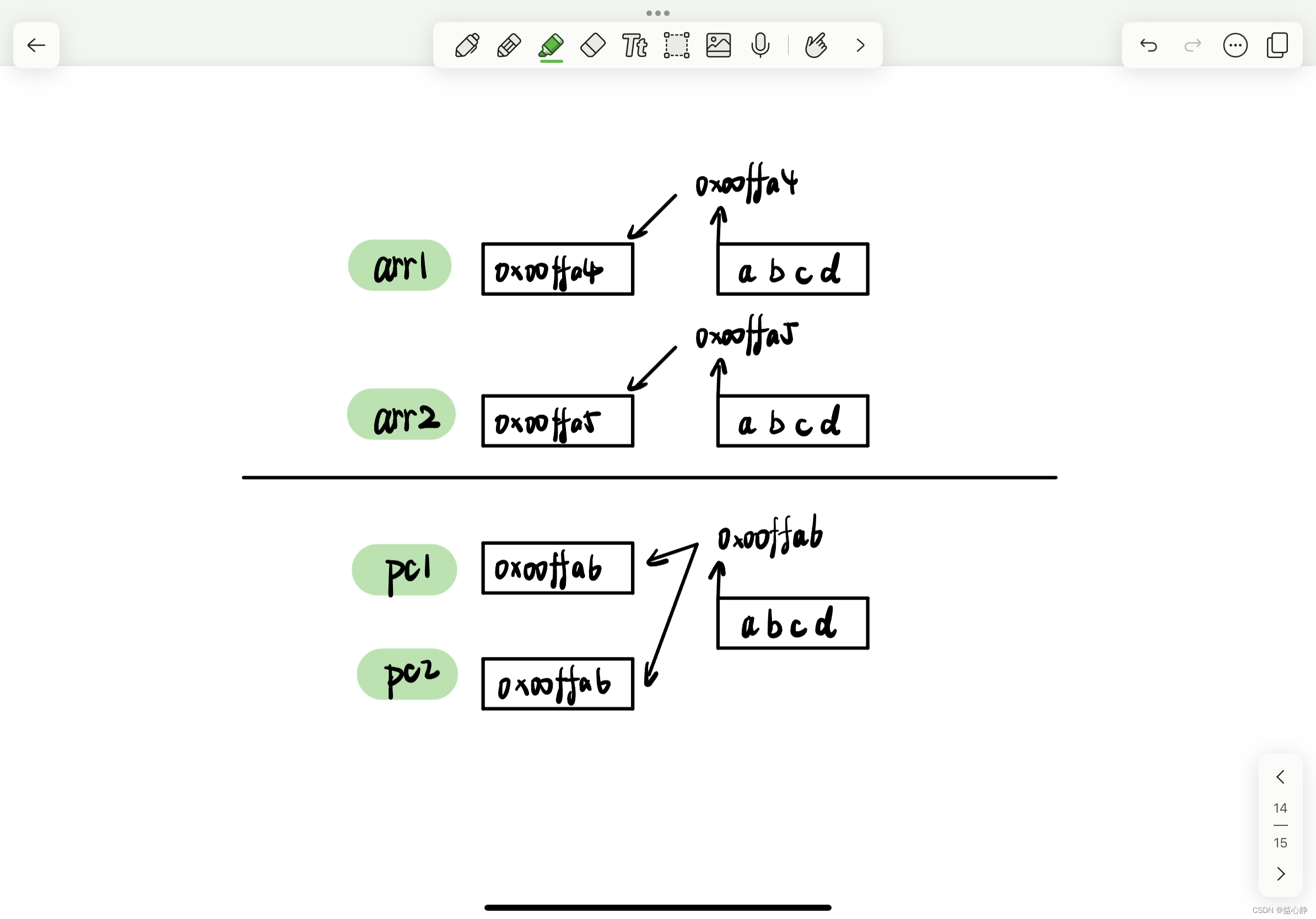
前言
工作时需要将模型转成onnx使用triton加载,记录将pytorch模型转成onnx的过程。
1.转化步骤
1-1.安装依赖库
pip install onnx
pip install onnxruntime1-2.导入模型
将训练的模型导入
from torch.utils.data import TensorDataset, DataLoader
from transformers import BertTokenizer, BertModel,AdamW
import torch.nn as nn
import torch
import pandas as pd
import json
import re
import requests
import json
import numpy as np
def encoder(max_length,text_list):
#将text_list embedding成bert模型可用的输入形式
#加载分词模型
vocab_path = "/ssd/dongzhenheng/Pretrain_Model/Roberta_Large/"
#tokenizer = RobertaTokenizer.from_pretrained(vocab_path)
tokenizer = BertTokenizer.from_pretrained(vocab_path)
input_dict = tokenizer.encode_plus(
text,
add_special_tokens=True, # 添加'[CLS]'和'[SEP]'
max_length=max_length,
truncation=True, # 截断或填充
padding='max_length', # 填充至最大长度
return_attention_mask=True, # 返回attention_mask
return_token_type_ids=True, # 返回token_type_ids
return_tensors='pt',
)
input_ids = input_dict['input_ids']
token_type_ids = input_dict['token_type_ids']
attention_mask = input_dict['attention_mask']
print(input_ids.dtype,token_type_ids.dtype,attention_mask.dtype)
input_ids = input_ids.to(torch.int32)
token_type_ids = token_type_ids.to(torch.int32)
attention_mask = attention_mask.to(torch.int32)
print(input_ids.dtype,token_type_ids.dtype,attention_mask.dtype)
return input_ids,token_type_ids,attention_maskclass JointBertClassificationModel(nn.Module):
def __init__(self):
super(JointBertClassificationModel, self).__init__()
#加载预训练模型
pretrained_weights = "/ssd/dongzhenheng/Pretrain_Model/Roberta_Large/"
self.bert = BertModel.from_pretrained(pretrained_weights)
#self.bert = ErnieForMaskedLM.from_pretrained(pretrained_weights)
for param in self.bert.parameters():
param.requires_grad = True
self.dropout = nn.Dropout(0.3)
#定义联合分类
self.pri_dense_1 = nn.Linear(1024, 89)
def forward(self, input_ids,token_type_ids,attention_mask):
#得到bert_output
bert_output = self.bert(input_ids=input_ids, token_type_ids= token_type_ids,attention_mask=attention_mask)
#获得预训练模型的输出
bert_cls_hidden_state = bert_output[1]
pri_cls_output_1 = self.pri_dense_1(bert_cls_hidden_state)
return pri_cls_output_1
class FeedBackBertClassificationModel(nn.Module):
def __init__(self):
super(FeedBackBertClassificationModel, self).__init__()
#加载预训练模型
pretrained_weights = "/ssd/dongzhenheng/Pretrain_Model/Roberta_Large/"
self.bert = BertModel.from_pretrained(pretrained_weights)
#self.bert = ErnieForMaskedLM.from_pretrained(pretrained_weights)
for param in self.bert.parameters():
param.requires_grad = True
self.dropout = nn.Dropout(0.3)
self.pri_dense_1 = nn.Linear(1024, 3)
def forward(self, input_ids,token_type_ids,attention_mask):
#得到bert_output
bert_output = self.bert(input_ids=input_ids, token_type_ids=token_type_ids,attention_mask=attention_mask)
#获得预训练模型的输出
bert_cls_hidden_state = bert_output[1]
pri_cls_output_1 = self.pri_dense_1(bert_cls_hidden_state)
#print(pri_cls_output_1.size())
return pri_cls_output_1
FeedBack_classifier_model_path = '/ssd/dongzhenheng/Work/Intelligent_customer_service/feed_back_model_large_1.pkl'
FeedBack_classifier_model = torch.load(FeedBack_classifier_model_path, map_location=torch.device('cpu'))
# 设置模型为评估模式
FeedBack_classifier_model.eval()1-3 转成onnx格式
# 导出模型
max_len = 100
text = '你好'
input_ids, token_type_ids, attention_mask = encoder(max_len,text)
torch.onnx.export(model = FeedBack_classifier_model, # 模型
args = (input_ids, token_type_ids, attention_mask), # 模型输入
path = "/home/zhenhengdong/WORk/Triton/Bug_Cls/Onnx_model/model_repository/Feedback_classifition_onnx/1/model.onnx", # 输出文件名
export_params=True, # 是否导出参数
opset_version=15, # ONNX版本
verbose=True,
do_constant_folding=True, # 是否执行常量折叠优化
input_names=["input_ids", "token_type_ids", "attention_mask"], # 输入名
output_names=["pri_cls_output"], # 输出名
dynamic_axes={"input_ids": {0: "batch_size"}, "token_type_ids": {0: "batch_size"}, "attention_mask": {0: "batch_size"}, "pri_cls_output": {0: "batch_size"}}) # 动态维度model :需要导出的pytorch模型
args:模型的输入参数,需要和模型接收到的参数一致。
path:输出的onnx模型的位置和名称。
export_params:输出模型是否可训练。default=True,表示导出trained model,否则untrained。opset_version :ONNX版本
verbose:是否打印模型转换信息。default=False。
input_names:输入节点名称。default=None。
output_names:输出节点名称。default=None。
do_constant_folding:是否使用常量折叠,默认即可。default=True。
dynamic_axes:模型的输入输出有时是可变的。



















![[Linux][网络][高级IO][三][IO多路转接][epoll]详细讲解](https://img-blog.csdnimg.cn/direct/acaf2c83be9e4ae7a8de8ed7c95463aa.png)



![PyCharm运行程序遇到‘[WinError 1455] 页面文件太小’的问题](https://img-blog.csdnimg.cn/direct/81558cf111554fdc8d1bc7c9f19f8b95.png)