个人主页:丷从心·
系列专栏:大数据

海量数据分流技术
传统Hash
Hash(key) % max
一致性Hash(Consistent Hashing)
- 将哈希值映射到一个哈希环上
- 每个节点通过哈希函数映射到这个环上一个或多个点
- 数据项也通过哈希函数映射到环上的某个点,然后按照顺时针方向查找到第一个节点,这个节点就是该数据项存储的地方
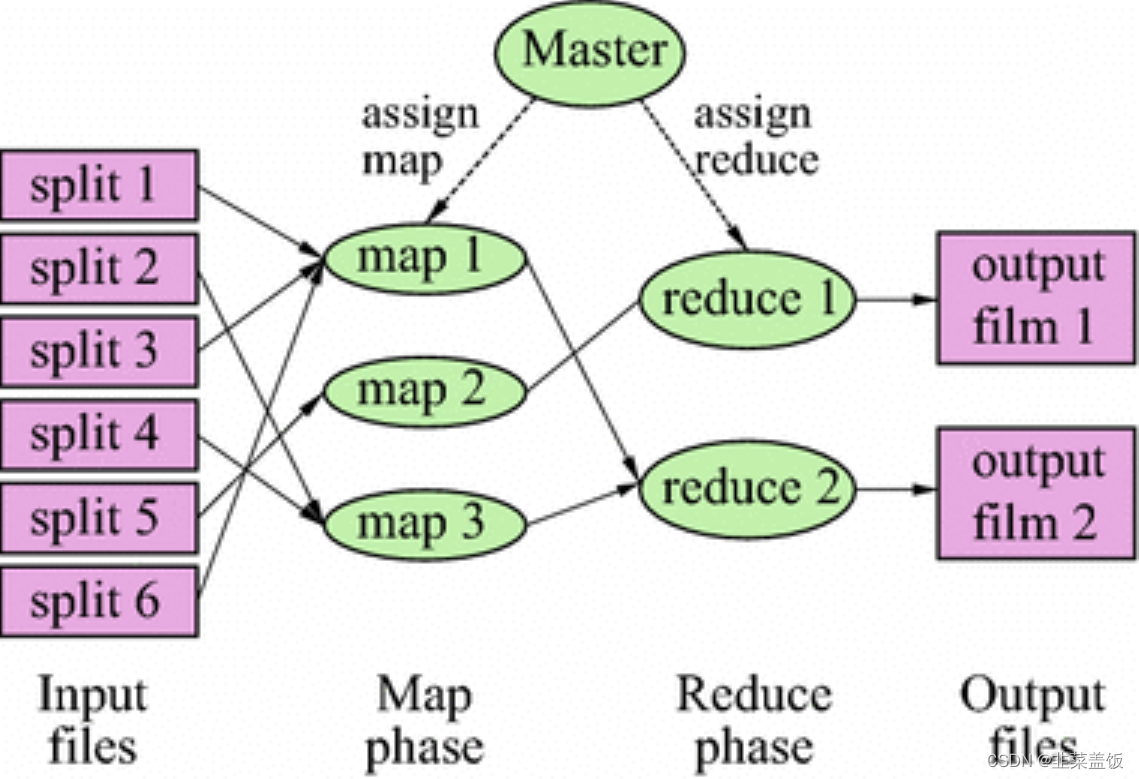
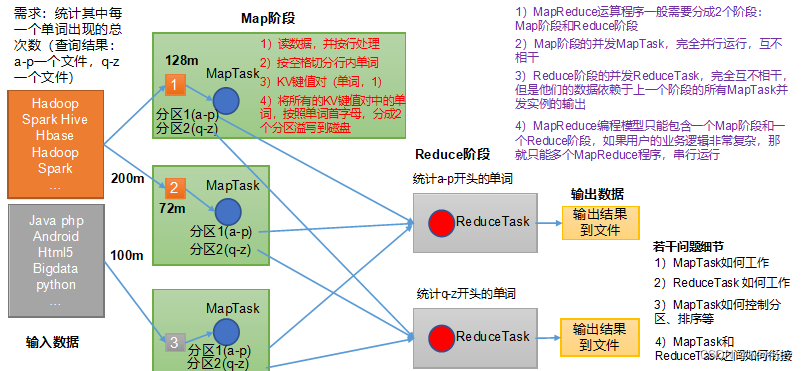
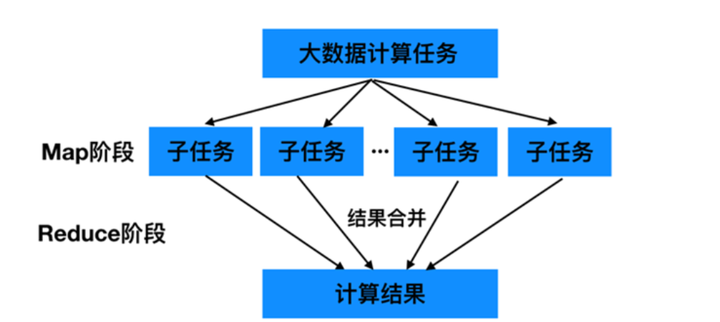
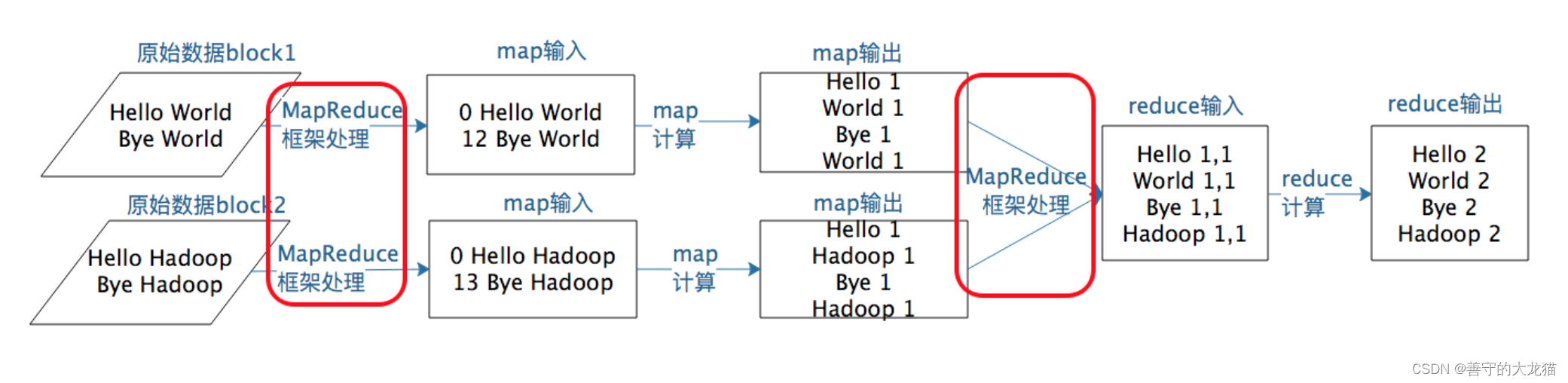
MapReduce执行流程

InputFormat
- M a p R e d u c e MapReduce MapReduce框架基础类之一,进行 D a t a S p l i t Data \ Split Data Split数据分割和 R e c o r d R e a d Record \ Read Record Read记录读取
- B l o c k Block Block是底层的文件块, M a p Map Map无法直接读取,需要将 B l o c k Block Block转换为内部可以识别的 R e c o r d Record Record
'\n'保证每条记录在数据切割时不被切散,实际上每个 S p l i t Split Split包含后一个 B l o c k Block Block中开头部分的数据,解决 R e c o r d Record Record跨 B l o c k Block Block问题- R e c o r d R e a d e r Record \ Reader Record Reader每读取一条 R e c o r d Record Record,就调用一次 M a p Map Map函数
Shuffle
- M a p Map Map任务的输出到 R e d u c e Reduce Reduce任务的输入之间的过程
Partitioner
- 决定数据由哪个 R e d u c e Reduce Reduce处理,从而分区
- P a r t i t i o n Partition Partition在一个环形内存缓冲区中进行,每个缓冲区大小默认 100 M 100 M 100M,溢写阈值为 100 M × 80 % = 80 M 100 M \times 80\% = 80 M 100M×80%=80M,缓冲区中的数据为 ( p a r t i t i o n , k e y , v a l u e ) (partition , key , value) (partition,key,value)三元组
Spill
- 在内存缓冲区达到阈值时, S p i l l Spill Spill溢写线程会锁住 80 M 80 M 80M的缓冲区,开始将数据写到本地磁盘上,然后释放内存
- 每次溢写都生成一个数据文件
- 数据溢写前会对 k e y key key进行快速排序以及 C o m b i n e Combine Combine
Combiner
- 将相同的 k e y key key的数据的 v a l u e value value进行合并
- 减少数据量,提高数据传输效率

MapReduce两个重要的进程
JobTracker
- 主进程,负责接收 C l i e n t Client Client作业提交,调度任务到从节点上运行
- 监控工作节点状态及任务进度
- 利用一个线程池来同时处理心跳和用户请求
TaskTracker
- 由 J o b T r a c k e r JobTracker JobTracker指派任务,实例化用户程序,在本地执行任务
- 通过周期性的心跳来通知 J o b T r a c k e r JobTracker JobTracker其当前的健康状态,每 3 3 3秒心跳一次,每一次心跳包含了可用的 M a p Map Map和 R e d u c e Reduce Reduce任务数目、占用的数目以及运行中的任务详细信息
MapReduce物理配置
查看系统资源限制
ulimit -a
设置合适的slot
mapred.tasktracker.map.tasks.maximum默认值为 2 2 2mapred.tasktracker.reduce.tasks.maximum默认值为 2 2 2
Hadoop Streaming
- M a p Map Map和 R e d u c e Reduce Reduce只需要从 s t d i n stdin stdin读和写到 s t d o u t stdout stdout
- S t r e a m i n g Streaming Streaming默认只能处理文本数据,如果对二进制数据进行处理,比较好的方法是将二进制的 k e y key key和 v a l u e value value进行 b a s e 64 base64 base64的编码转换,得到文本
Streaming选项
-cacheFile选项指定一个文件,需要上传到 H D F S HDFS HDFS-cacheArchive选项指定一个目录结构,需要上传到 H D F S HDFS HDFS-file选项将本地文件分发到计算节点上-jobconf选项-
mapred.job.priority表示作业优先级
-
mapred.job.map.capacity表示最多同时运行的 M a p Map Map任务数
-
mapred.job.reduce.capacity表示最多同时运行的 R e d u c e Reduce Reduce任务数
-
mapred.task.timeout表示任务未响应的最大时间

































![[AI开发配环境]jupyter notebook远程连接ssh](https://img-blog.csdnimg.cn/direct/c730f31cb4094af9829ce89ae5a4d033.png)