linux三剑客
前言:本文暂时整理linux中正则表达式、三剑客的基础知识。后续训练内容会不定期更新。
1. 正则表达式
此正则表达式的资料来自[B站-CodeSheep:r2coding.com],放在自己笔记里以供个人学习使用。感谢CodeSheep大佬的资料分享,受益良多。示例内容也请查看以上链接。
- 字符
| 表达式 |
描述 |
| [abc] |
字符集。匹配集合中所含的任一字符 |
| [^abc] |
否定字符集。匹配任何不在集合中的字符 |
| [a-z] |
字符范围。匹配指定范围内的任意字符 |
| . |
匹配除换行符以外的任何单个字符 |
| \ |
转义字符 |
| \w |
匹配任何字母数字,包括下划线(等价于[A-Za-z0-9_])。 |
| \W |
匹配任何非字母数字(等价于[^A-Za-z0-9_])。 |
| \d |
数字。匹配任何数字 |
| \D |
非数字。匹配任何非数字字符。 |
| \s |
空白。匹配任何空白字符,包括空格、制表符等 |
| \S |
非空白。匹配任何非空白字符。 |
- 分组与引用
| 表达式 |
描述 |
| (expression) |
分组。匹配括号里的整个表达式。 |
| (?:expression) |
非捕获分组。匹配括号里的整个字符串但不获取匹配结果,拿不到分组引用。 |
| \num |
对前面所匹配分组的引用。比如(\d)\1可以匹配两个相同的数字,(Code)(Sheep)\1\2则可以匹配CodeSheepCodeSheep。 |
- 锚点/边界
| 表达式 |
描述 |
| ^ |
匹配字符串或行开头。 |
| $ |
匹配字符串或行结尾。 |
| \b |
匹配单词边界。比如Sheep\b可以匹配CodeSheep末尾的Sheep,不能匹配CodeSheepCode中的Sheep |
| \B |
匹配非单词边界。比如Code\B可以匹配HelloCodeSheep中的Code,不能匹配HelloCode中的Code。 |
- 数量表示
| 表达式 |
描述 |
| ? |
匹配前面的表达式0个或1个。即表示可选项。 |
| + |
匹配前面的表达式至少1个。 |
| * |
匹配前面的表达式0个或多个。 |
| | |
或运算符。并集,可以匹配符号前后的表达式。 |
| {m} |
匹配前面的表达式m个。 |
| {m,} |
匹配前面的表达式最少m个。 |
| {m,n} |
匹配前面的表达式最少m个,最多n个。 |
- 预查断言
| 表达式 |
描述 |
| (?=) |
正向预查。比如Code(?=Sheep)能匹配CodeSheep中的Code,但不能匹配CodePig中的Code。 |
| (?!) |
正向否定预查。比如Code(?!Sheep)不能匹配CodeSheep中的Code,但能匹配CodePig中的Code。 |
| (?<=) |
反向预查。比如(?<=Code)Sheep能匹配CodeSheep中的Sheep,但不能匹配ReadSheep中的Sheep。 |
| (?<!) |
反向否定预查。比如(?<!Code)Sheep不能匹配CodeSheep中的Sheep,但能匹配ReadSheep中的Sheep。 |
- 特殊标志
| 表达式 |
描述 |
| /…/i |
忽略大小写。 |
| /…/g |
全局匹配。 |
| /…/m |
多行修饰符。用于多行匹配。 |
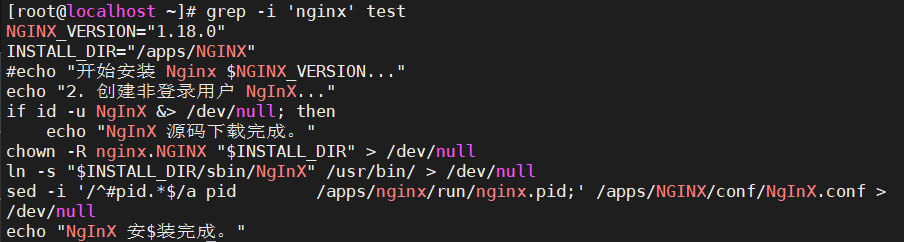
2. grep
Global search REgular expression and Print out the line <—> 全局搜索 REgular 表达式并打印出行
1. 语法:
grep [options] [pattern] file
命令 参数 匹配模式 文件数据
2. 参数:
-v 排除匹配结果
-n 显示匹配行与行号
-i 不区分大小写
-c 只统计匹配的行数
-E 使用egrep命令
-w 只匹配过滤的单词
-o 只输出匹配的内容
3. 匹配模式:
就是想要找的东西,可以是“普通的文字符号”,也可以是“正则表达式”
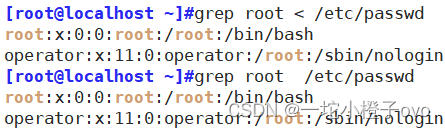
3. sed
Stream Editor <—> 流编辑器
1. 作用:sed是操作、过滤和转换文本内容的强大工具。
常用功能包括结合正则表达式对文本实现快速增删改查,其中查询的功能中最常用的两大功能是过滤(过滤指定的字符串)、取行(取出指定行)。
2. 语法:
sed [选项] [sed内置命令字符] [输入文件]
3. 选项:
-n 取消默认sed的输出,常与sed内置命令p一起使用
-i 直接将修改结果写入文本,不用-i,sed修改的是内存数据
-e 多次编辑,不需要管道符
-r 支持扩展的正则
4. 内置命令符
a append,对文本追加,在指定行后面添加一行/多行文本
d delete,删除匹配行
i insert,表示插入文本,在指定行前添加一行/多行
p print,打印匹配的内容,通常p与-n一起用
s/正则/替换内容/g 匹配正则内容,然后替换内容,g表示全局
5. sed匹配范围
空地址 全文处理
单地址 指定文件某一行
/pattern/ 被模式匹配到的每一行
范围匹配 "10,20"十到二十行;"10,+5"第十行向下5;"/pattern1/,/pattern2/"
步长 "1~2"表示1、3、5、7;"2~2"表示2、4、6、8
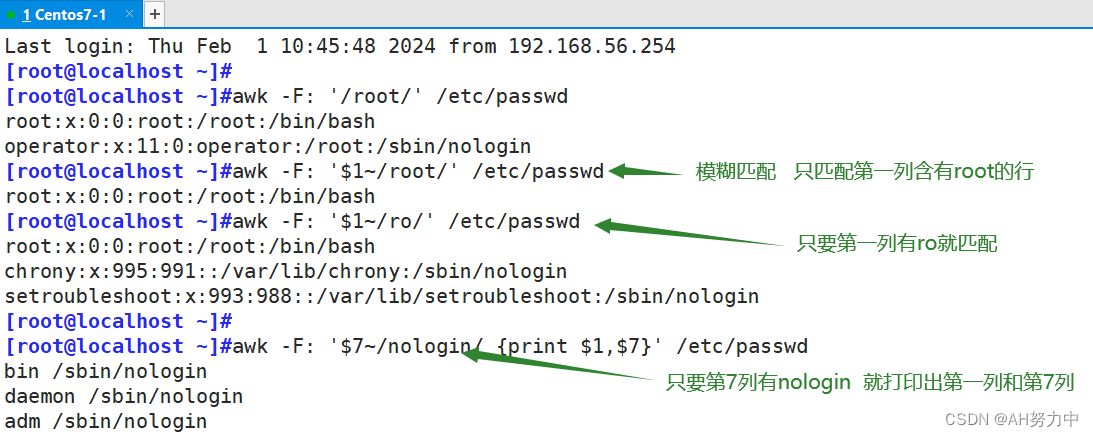
4. awk
1. 作用:awk有强大的文本格式化的能力,好比将一些文本数据格式化成专业的excel表的样式,awk更是一门编程语言,支持条件判断、数组、循环等功能
2. 语法:
awk [option] 'pattern[action]' file ...
参数 '模式 条件动作' 文件
3. awk的特征
- awk默认以空格为分隔符,且多个空格可识别为一个空格作为分隔符
- awk按行处理文件,一行处理完毕,处理下一行,根据用户指定的分割符去工作,没有指定则默认空格
- awk指定分隔符后,awk把每一行切割后的数据对应内置变量
- $0 表示整行
- $NF 表示当前分割后的最后一列
- 倒数第二列可以写成$(NF-1)
- awk,必须外层单引号,内层双引号,内置变量$1,$2都不得加双引号,否则会识别为文本,尽量不加引号
4. awk内置变量
$0 完整的输入记录
$n 指定分割符后,当前记录的第n个字段
NF(Number of fields) 分割后,当前行一共有多少个字段
NR(Number of records) 当前记录行,行数
FNR 各文件分别计数的行号
FS 输入字段分隔符,默认为空格
OFS 输出字段分隔符,默认为空白字符
RS 输入记录分隔符(输入换行符),指定输入时的换行符
ORS 输出记录分隔符(输出换行符),输出时用指定符号代替换行符
ARGC 命令行参数的个数
ARGV 数组,保存的是命令行所给定的各参数
5. 参数
-F 指定分割字段符
-v 定义或修改一个awk的内置变量
-f 从脚本文件中读取awk命令
6. 模式
awk默认是按行处理文本,如果不指定任何模式(条件),awk默认一行行处理;如果指定了模式,只有符合模式的才会被处理。
可用关系运算符:< <= == != >= > ~ !~
7. 正则表达式
awk使用正则表达式,必须把正则放在"//"双斜杠中,