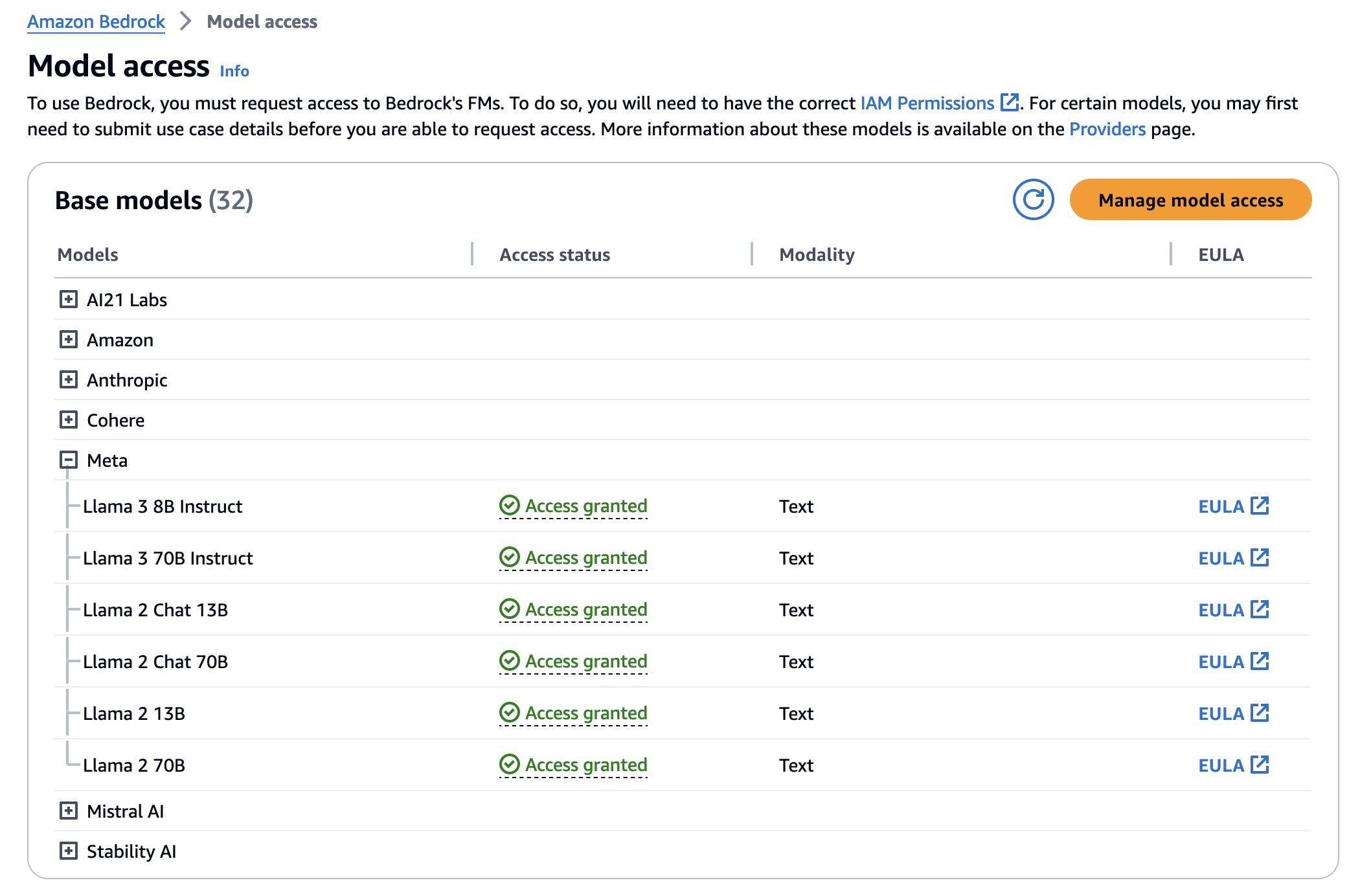
为什么要微调:
1. 模型不具备一些私人定制的知识
2。模型回答问题的套路你不满意。
对应衍生出来两种概念
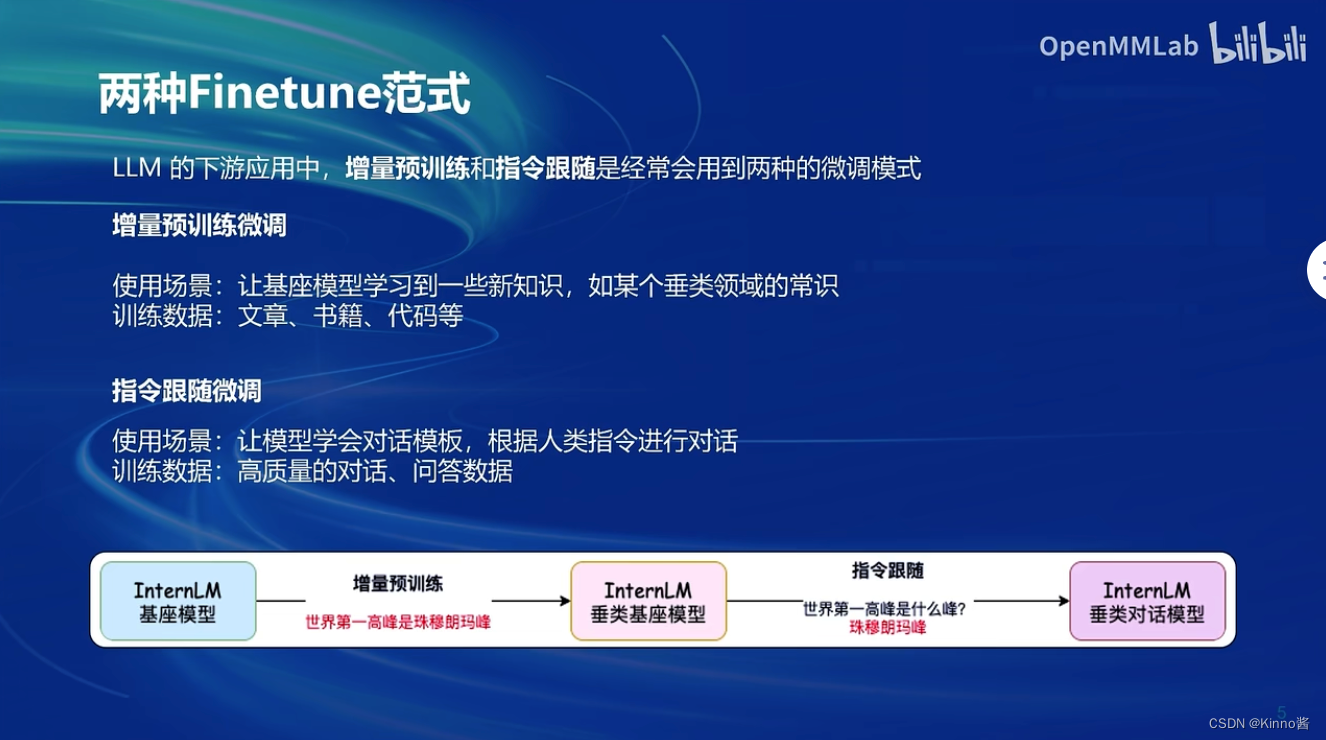
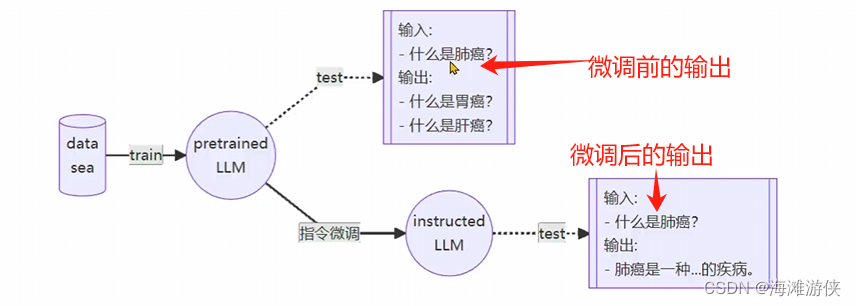
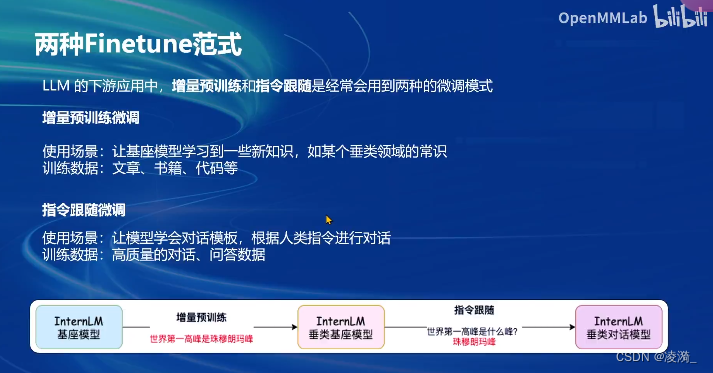
增量预训练微调:
- 使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识
- 训练数据:文章、书籍、代码等等
指令跟随微调:
- 使用场景:让模型学会对话模板,根据人类指令进行对话
- 训练数据:高质量的对话、问答数据

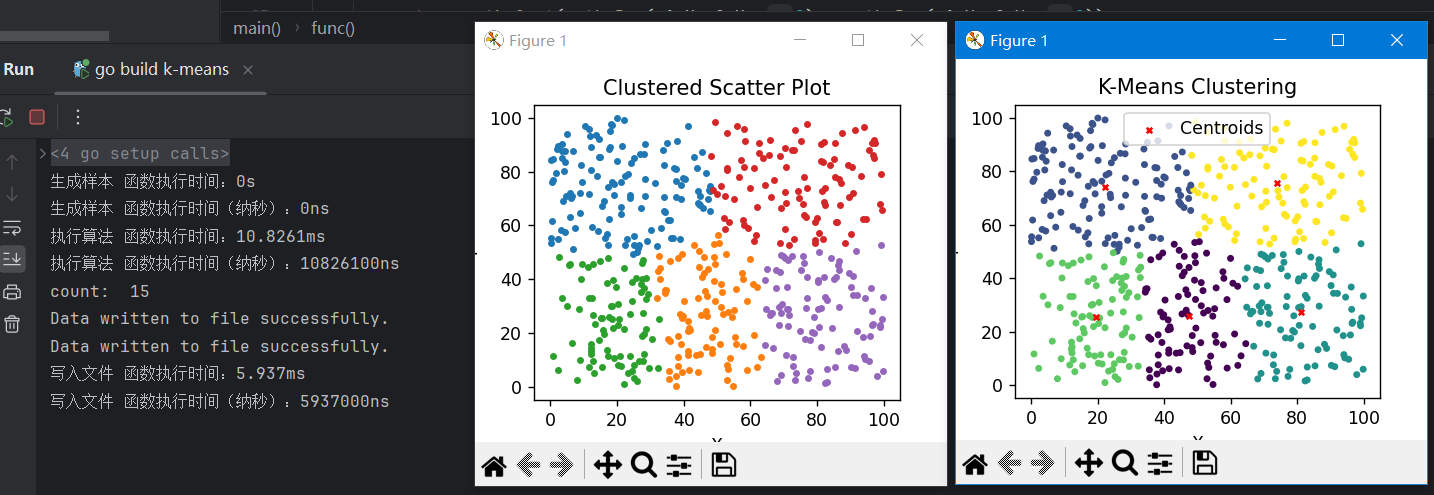
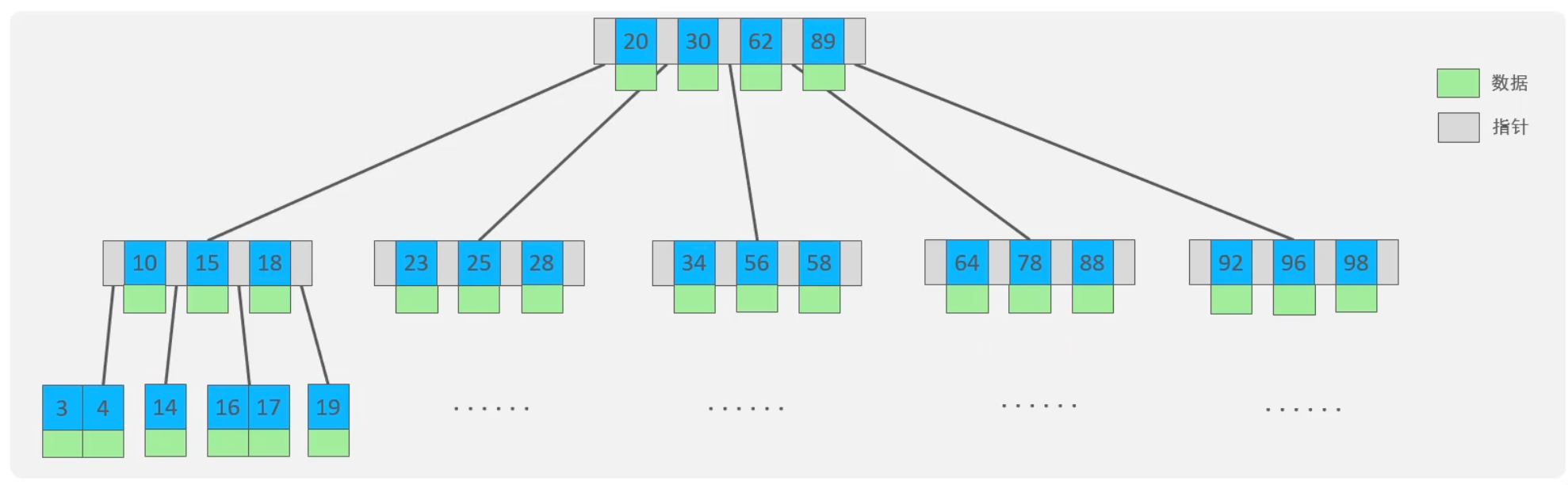
3. 数据的一生

LoRA和QLoRA
LoRA总结
之前的fine-tune的方法
Adapters
方法:在模型的每一层之间添加可训练的小规模的网络,冻结原始网络权重,以此来减少fine-tune所需要的参数量。
应用:适用于那些希望在保持预训练模型结构不变的同时,对模型进行特定任务调整的场景。
缺点:引入推理延时
Prefix Tuning
方法:在模型输入部分添加一些可训练的前缀向量,然后将这些向量和数据一起送入模型,改变模型对单独数据的推理结果。
应用:适用于需要对模型进行轻量级微调的场景,特别是当模型非常大,而可用于训练的资源有限时。
缺点:鲁棒性不够好,模型的结果严重依赖于前缀的质量(举一个不是很恰当的例子就是:网络本身就没这些只是,你非得加前缀让他说,这怎么能说出来?)
简单来说LoRA就是通过引入两个低秩参数化更新矩阵来减少参数量,我的理解是把参数量降维(变少)
问题描述:
假设一个网络的所有参数W,维度是d * k,微调它的梯度∆W维度也是是d * k,也就是说W和∆W的参数量是一样的,这就给我们训练参数量太大的网络带来困难。同时,如果有不同的下游任务,则需要对每个下游任务都训练出一个这样的∆W,因此这种方式的fine-tune是非常昂贵的。
解决方案:
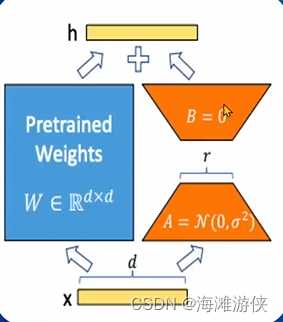
针对这个问题,文章提出将∆W进行低秩分解,分解成两个矩阵A(维度是d * r)、B(维度是r * k),其中r远远小于d和k的最小值,然后我们就可以计算∆W和AB的参数量:
应用:
需要对大模型所有参数进行微调,但不显著增加计算量的场景
优点:
训练成本降低,训练速度提升,针对不同任务只需训练针对不同任务的AB即可
缺点:
以精度换速度
QLoRA总结
在LoRA的基础上,添加了NF4的数据压缩(信息理论中最有的正太分布数据量化数据类型),进一步减少了显存和内存的消耗;然后添加一组可学习的LoRA权重,这些权重通过量化权重的反向传播梯度进行调整。
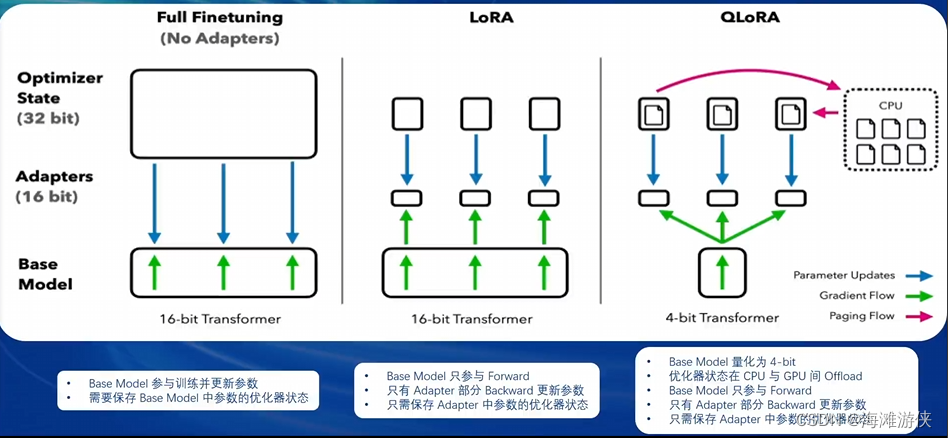
块状 k-bit 量化:既压缩了数据,又解决了异常值(我理解为噪声)对数据压缩的影响。我理解为:数据分布不是线性的,因此利用块量化(类似分治?)进行数据压缩。
优点:
使用NF4量化预训练权重,减少内存。计算梯度的时候再反量化?量化和反量化的或称会不会带来时间消耗?
双重量化:虽然NF4的数据的内存消耗很小,但是将量化常数也占用了内存。




![[InternLM训练营第二期<span style='color:red;'>笔记</span>]4. <span style='color:red;'>XTuner</span> 微调 LLM:1.8B、多模态、Agent](https://img-blog.csdnimg.cn/direct/57e34f733ca44480a76ca2d2a28ad5d8.png)