参考学习教程【XTuner 大模型单卡低成本微调实战】
理论
Finetune简介
大语言模型
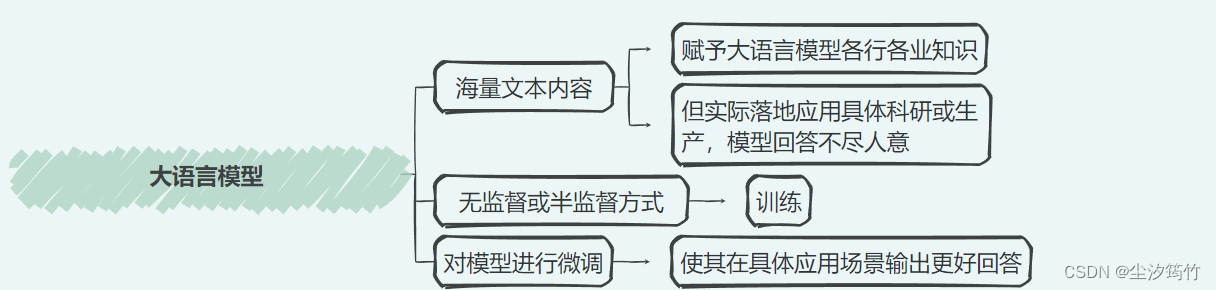
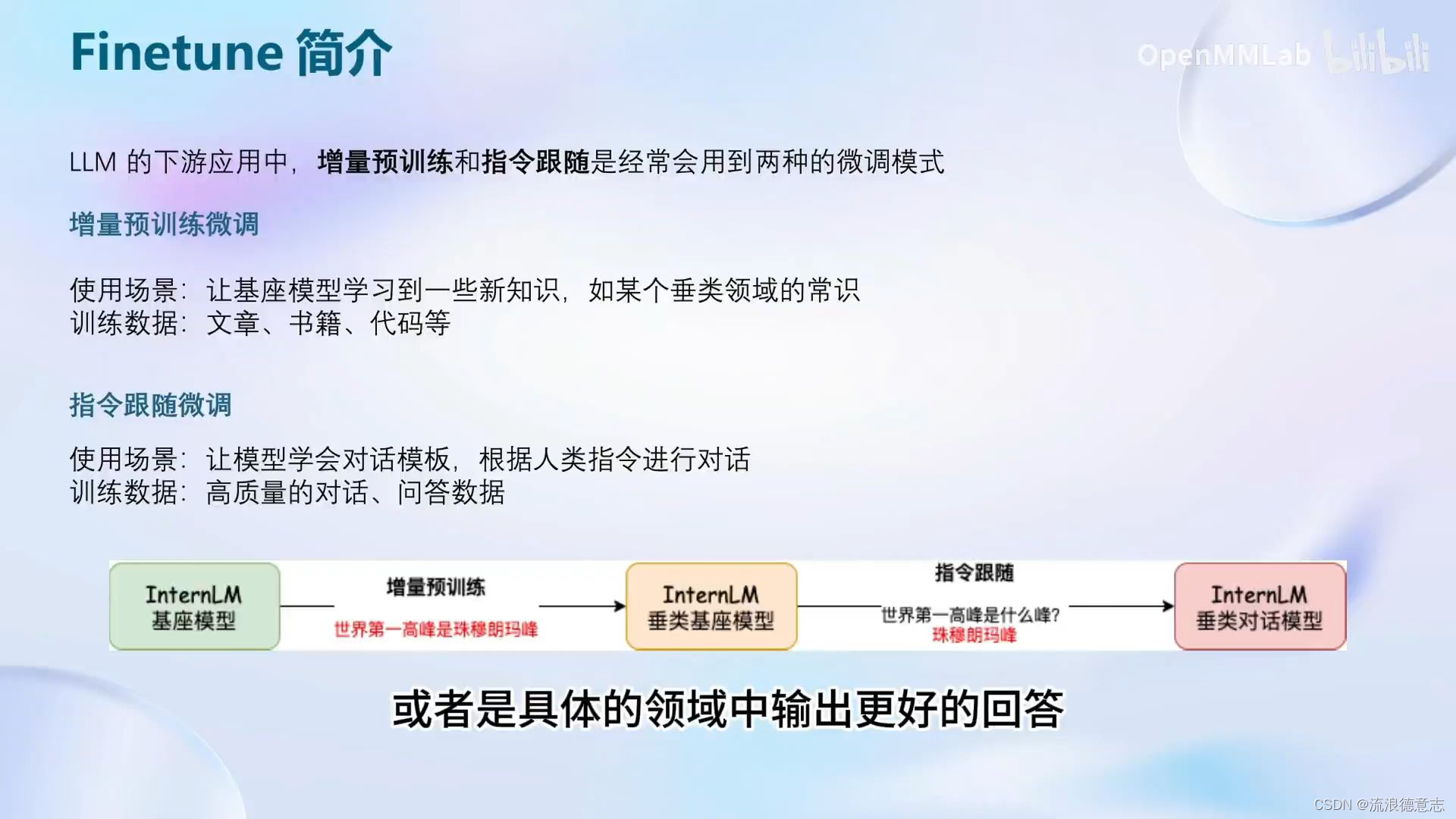
微调模式
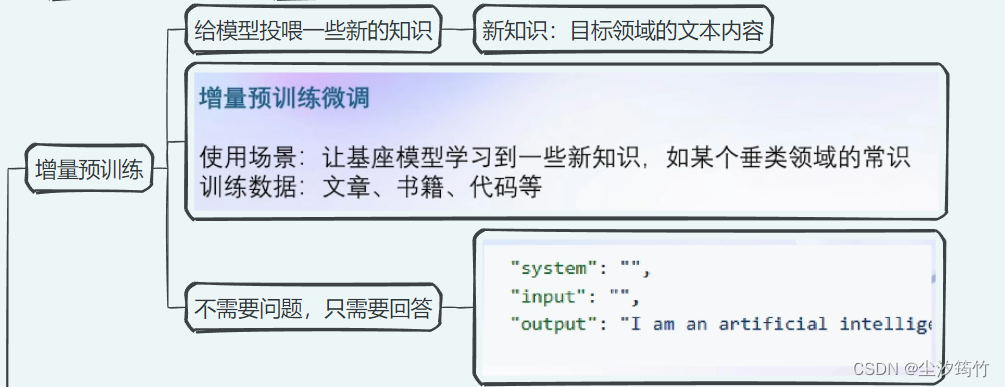
增量预训练
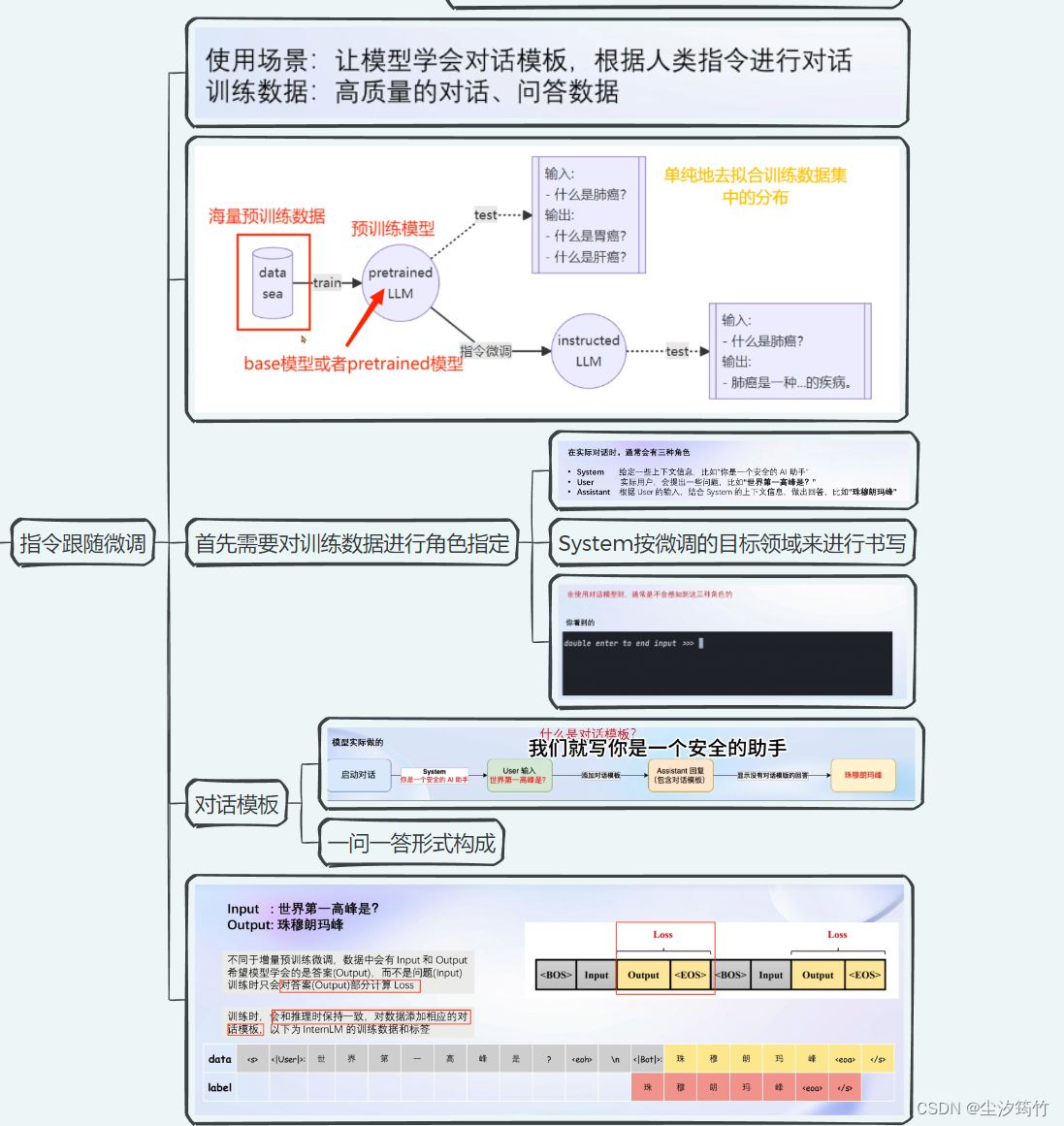
指令跟随微调
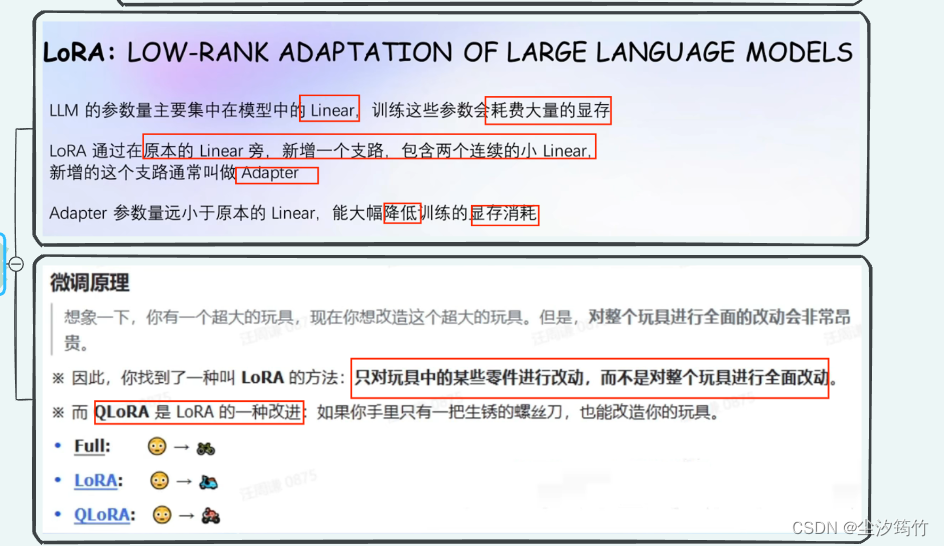
LoRA和QLoRA
Xtuner介绍

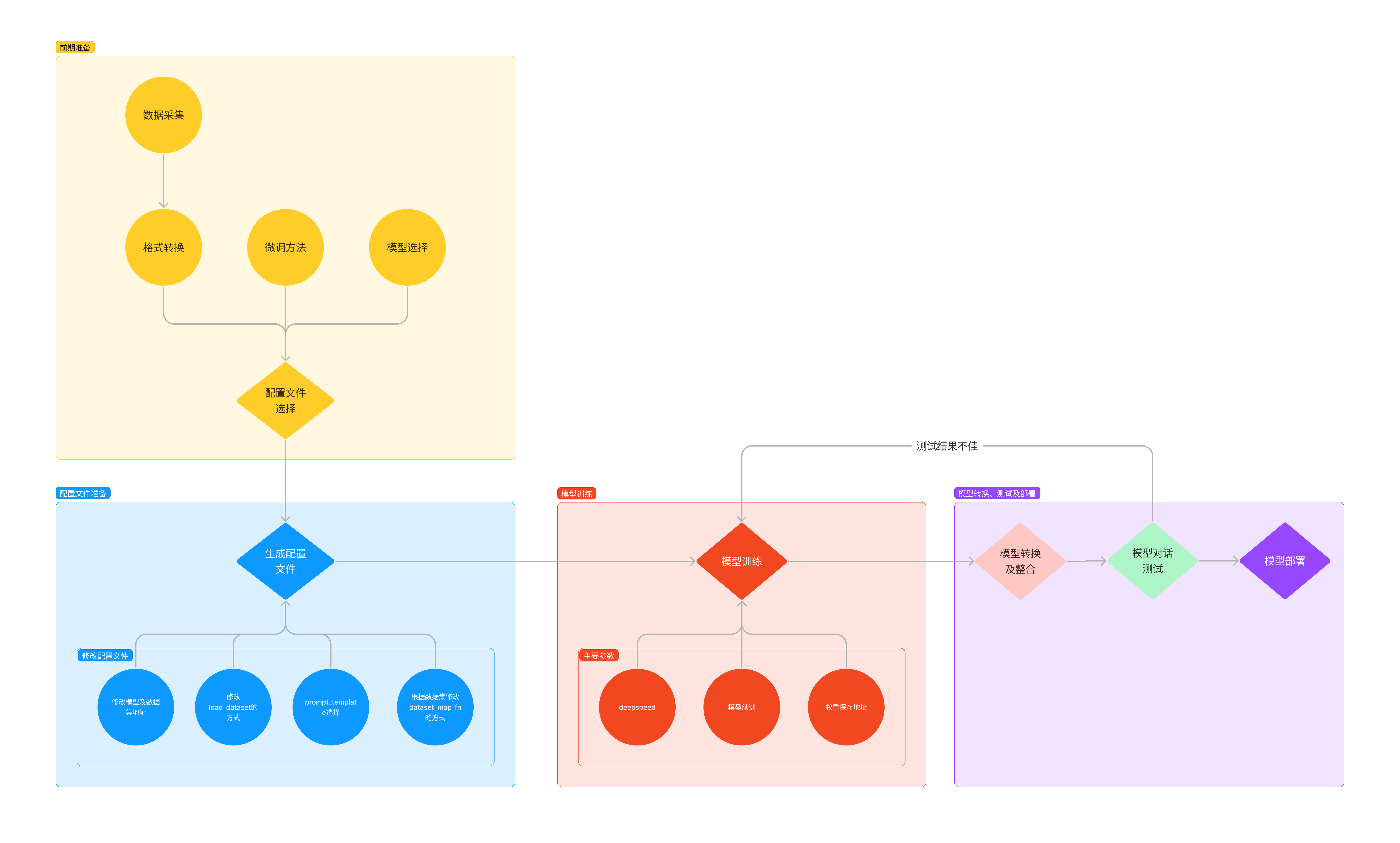
实战
自定义微调
用 Medication QA 数据集进行微调
将数据转为 XTuner 的数据格式
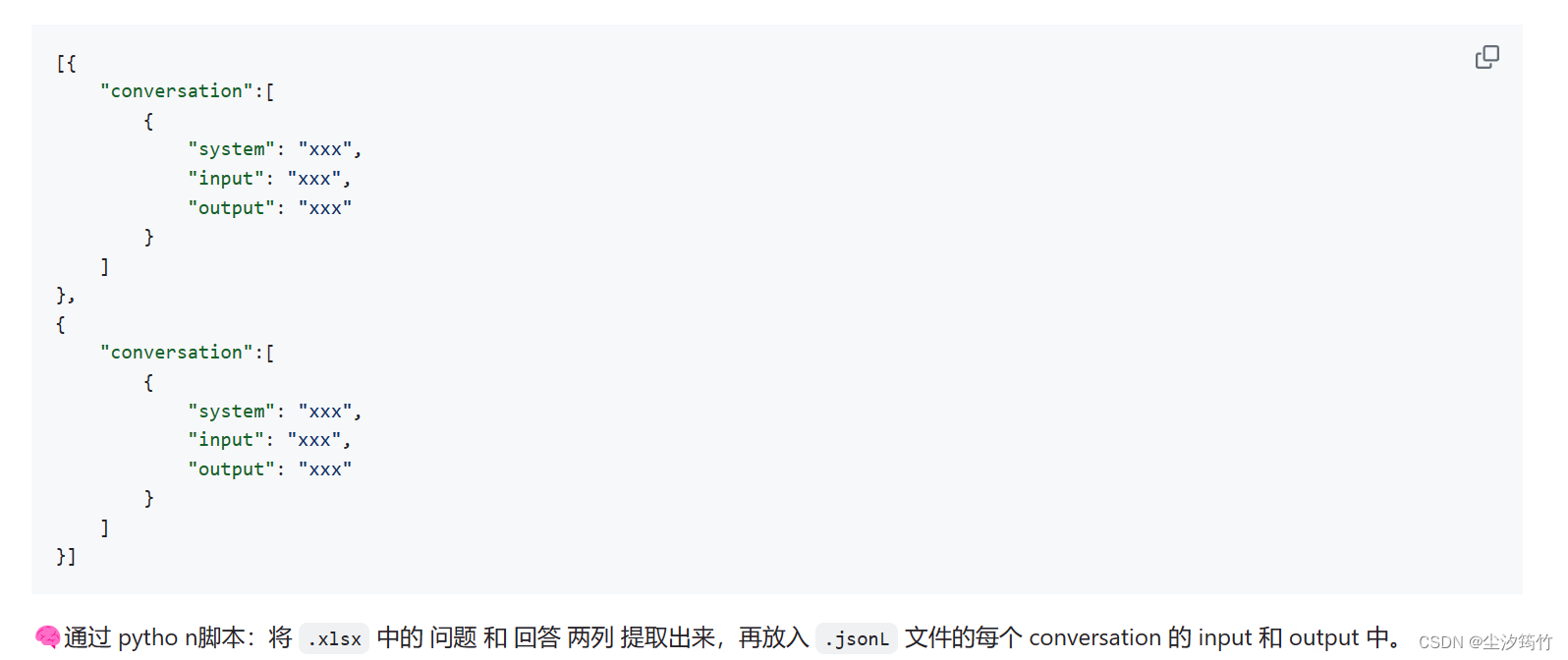
目标格式:(.jsonL)
- 写提示词请Chatgpt完成,提示词如下:
Write a python file for me. using openpyxl. input file name is MedQA2019.xlsx
Step1: The input file is .xlsx. Exact the column A and column D in the sheet named “DrugQA” .
Step2: Put each value in column A into each “input” of each “conversation”. Put each value in column D into each “output” of each “conversation”.
Step3: The output file is .jsonL. It looks like:
[{
“conversation”:[
{
“system”: “xxx”,
“input”: “xxx”,
“output”: “xxx”
}
]
},
{
“conversation”:[
{
“system”: “xxx”,
“input”: “xxx”,
“output”: “xxx”
}
]
}]
Step4: All “system” value changes to “You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients’ questions.”
(引自教程文档)
- 下载相对应的安装包
pip install openpyxl
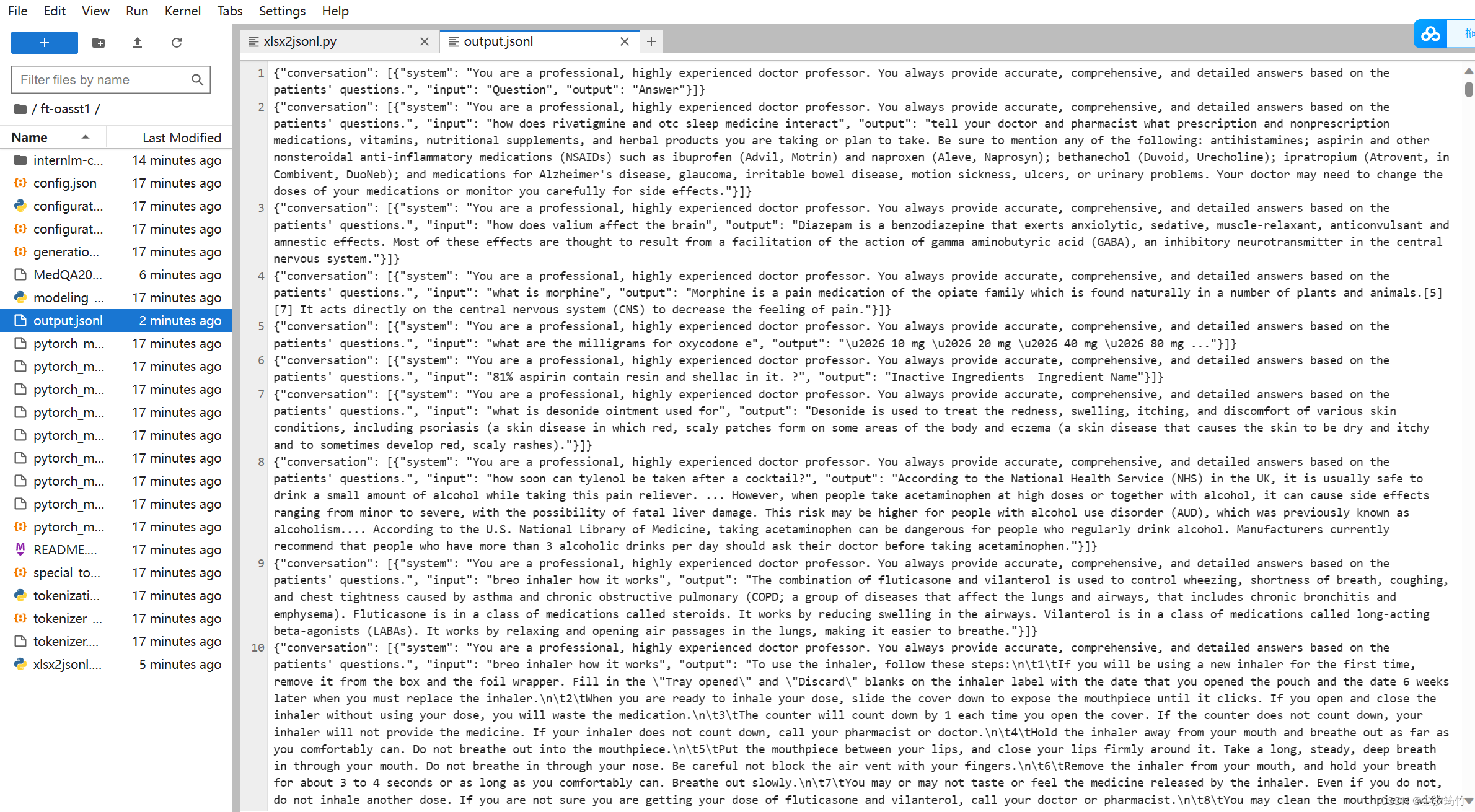
- 执行python脚本,获得格式化后的数据集
python xlsx2jsonl.py
python脚本如下:
import openpyxl
import json
# Step 1: Extract columns A and D from the sheet named "DrugQA"
def extract_data(file_path):
workbook = openpyxl.load_workbook(file_path)
sheet = workbook["DrugQA"]
column_a = [cell.value for cell in sheet['A']]
column_d = [cell.value for cell in sheet['D']]
return column_a, column_d
# Step 2: Create conversations from extracted data
def create_conversations(column_a, column_d):
conversations = []
for input_value, output_value in zip(column_a, column_d):
conversation = {
"system": "You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions.",
"input": str(input_value),
"output": str(output_value)
}
conversations.append({
"conversation": [conversation]})
return conversations
# Step 3: Write conversations to a JSONL file
def write_to_jsonl(conversations, output_file):
with open(output_file, 'w') as jsonl_file:
for conversation in conversations:
jsonl_file.write(json.dumps(conversation) + '\n')
if __name__ == "__main__":
# Input and output file paths
input_file_path = "MedQA2019.xlsx"
output_file_path = "output.jsonl"
# Step 1: Extract data from the input file
column_a, column_d = extract_data(input_file_path)
# Step 2: Create conversations
conversations = create_conversations(column_a, column_d)
# Step 3: Write conversations to JSONL file
write_to_jsonl(conversations, output_file_path)
print("Conversion completed. JSONL file created at:", output_file_path)
格式化后的数据集
划分训练集和测试集
- 写提示词请Chatgpt完成,提示词如下:
my .jsonL file looks like:
[{
“conversation”:[
{
“system”: “xxx”,
“input”: “xxx”,
“output”: “xxx”
}
]
},
{
“conversation”:[
{
“system”: “xxx”,
“input”: “xxx”,
“output”: “xxx”
}
]
}]
Step1, read the .jsonL file.
Step2, count the amount of the “conversation” elements.
Step3, randomly split all “conversation” elements by 7:3. Targeted structure is same as the input.
Step4, save the 7/10 part as train.jsonl. save the 3/10 part as test.jsonl
(引自教程文档)
- 生成的python脚本如下:
import json
import random
# Step 1: Read the .jsonL file
def read_jsonl(file_path):
with open(file_path, 'r') as jsonl_file:
data = jsonl_file.readlines()
conversations = [json.loads(line.strip()) for line in data]
return conversations
# Step 2: Count the amount of "conversation" elements
def count_conversations(conversations):
return len(conversations)
# Step 3: Randomly split "conversation" elements by 7:3
def split_conversations(conversations):
random.shuffle(conversations)
total_conversations = len(conversations)
split_index = int(0.7 * total_conversations)
train_set = conversations[:split_index]
test_set = conversations[split_index:]
return train_set, test_set
# Step 4: Save the 7/10 part as train.jsonl, save the 3/10 part as test.jsonl
def save_to_jsonl(data, file_path):
with open(file_path, 'w') as jsonl_file:
for item in data:
jsonl_file.write(json.dumps(item) + '\n')
if __name__ == "__main__":
# Input and output file paths
output_file_path = "output.jsonl"
train_file_path = "train.jsonl"
test_file_path = "test.jsonl"
# Step 1: Read the .jsonL file
conversations = read_jsonl(output_file_path)
# Step 2: Count the amount of "conversation" elements
total_conversations = count_conversations(conversations)
print("Total conversations:", total_conversations)
# Step 3: Randomly split "conversation" elements by 7:3
train_set, test_set = split_conversations(conversations)
# Step 4: Save the 7/10 part as train.jsonl, save the 3/10 part as test.jsonl
save_to_jsonl(train_set, train_file_path)
save_to_jsonl(test_set, test_file_path)
print("Splitting completed. Train and test sets saved at:", train_file_path, "and", test_file_path)

pth 转 huggingface
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_medqa2019_e3.py ./work_dirs/internlm_chat_7b_qlora_medqa2019_e3/epoch_3.pth ./hf
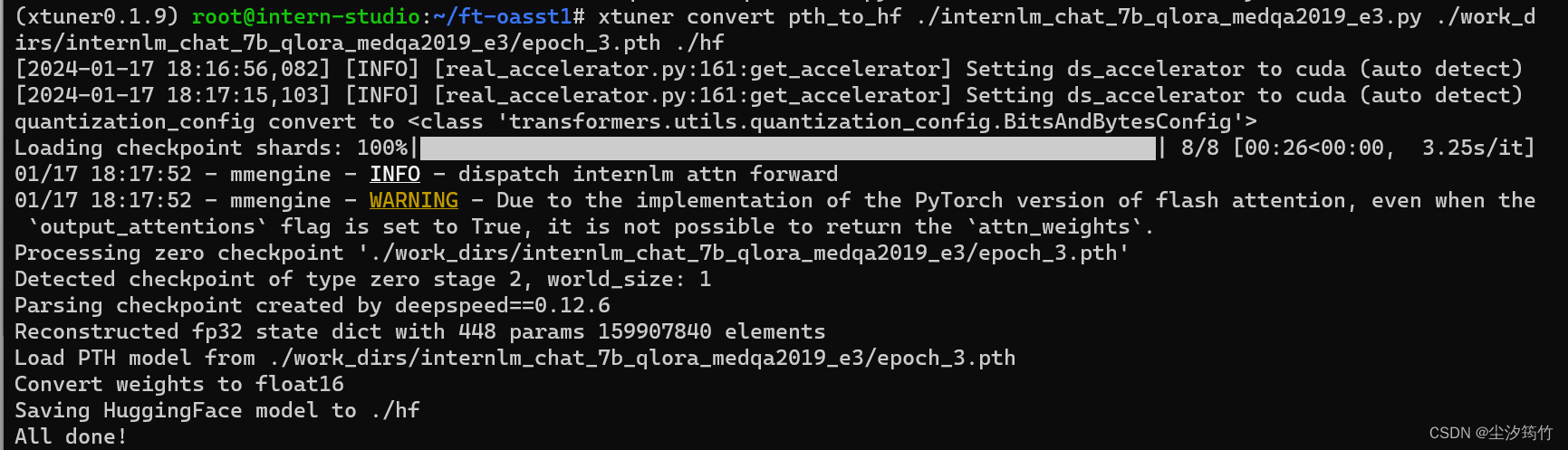
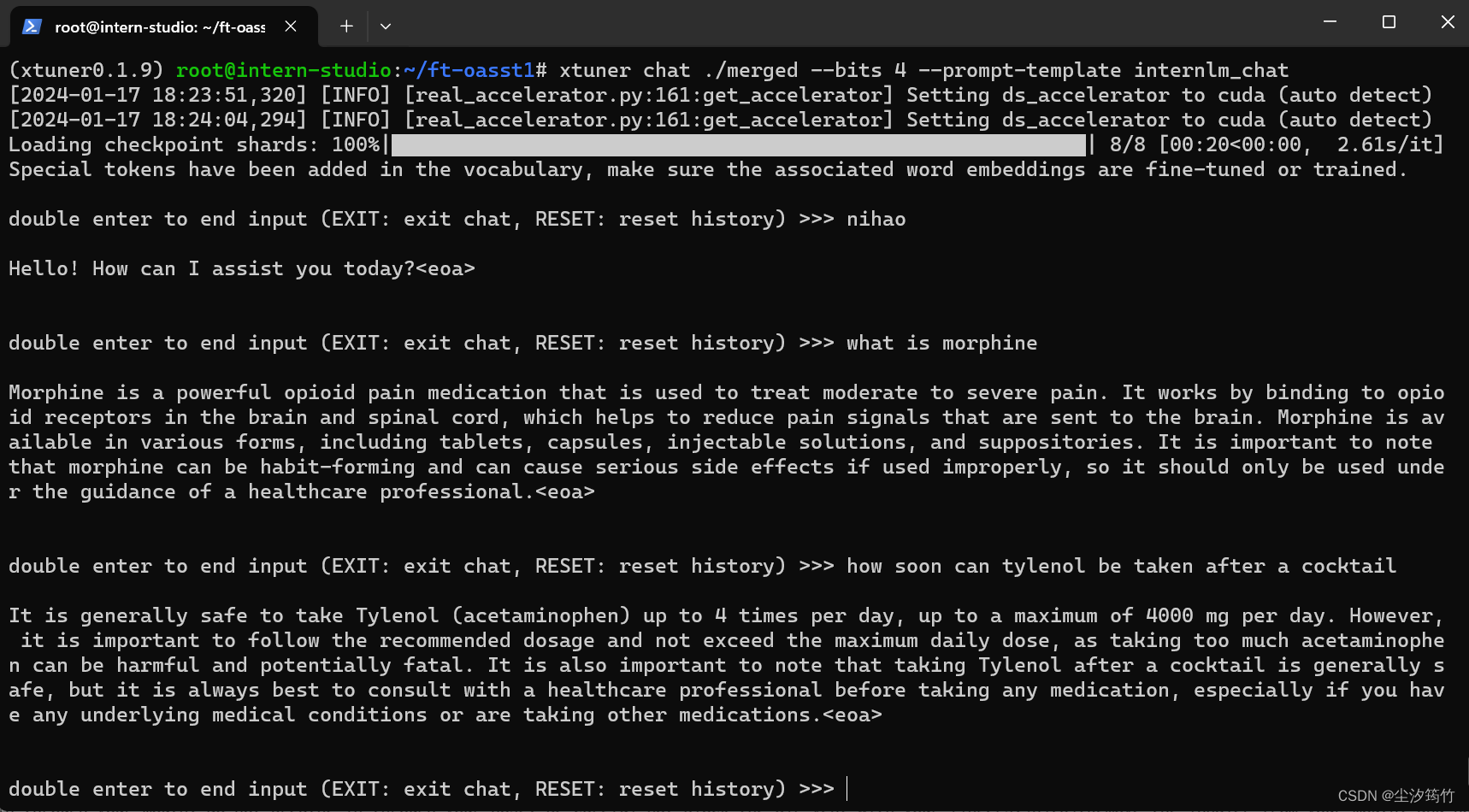
训练结果
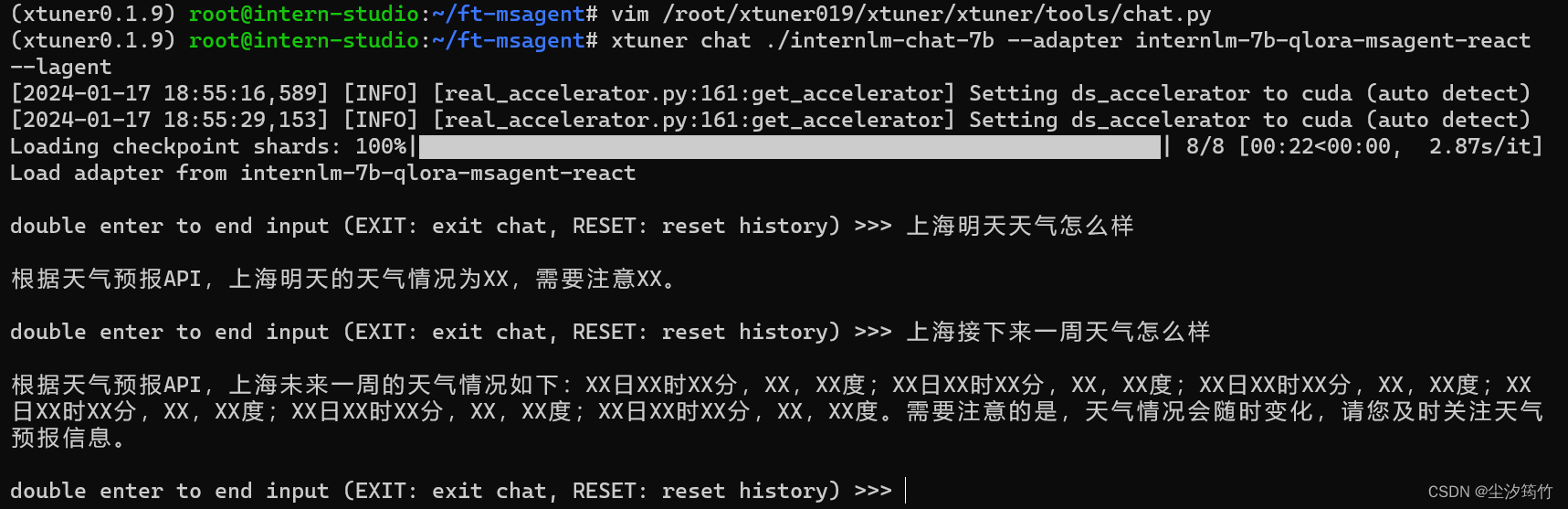
用 MS-Agent 数据集赋予 LLM 以 Agent 能力
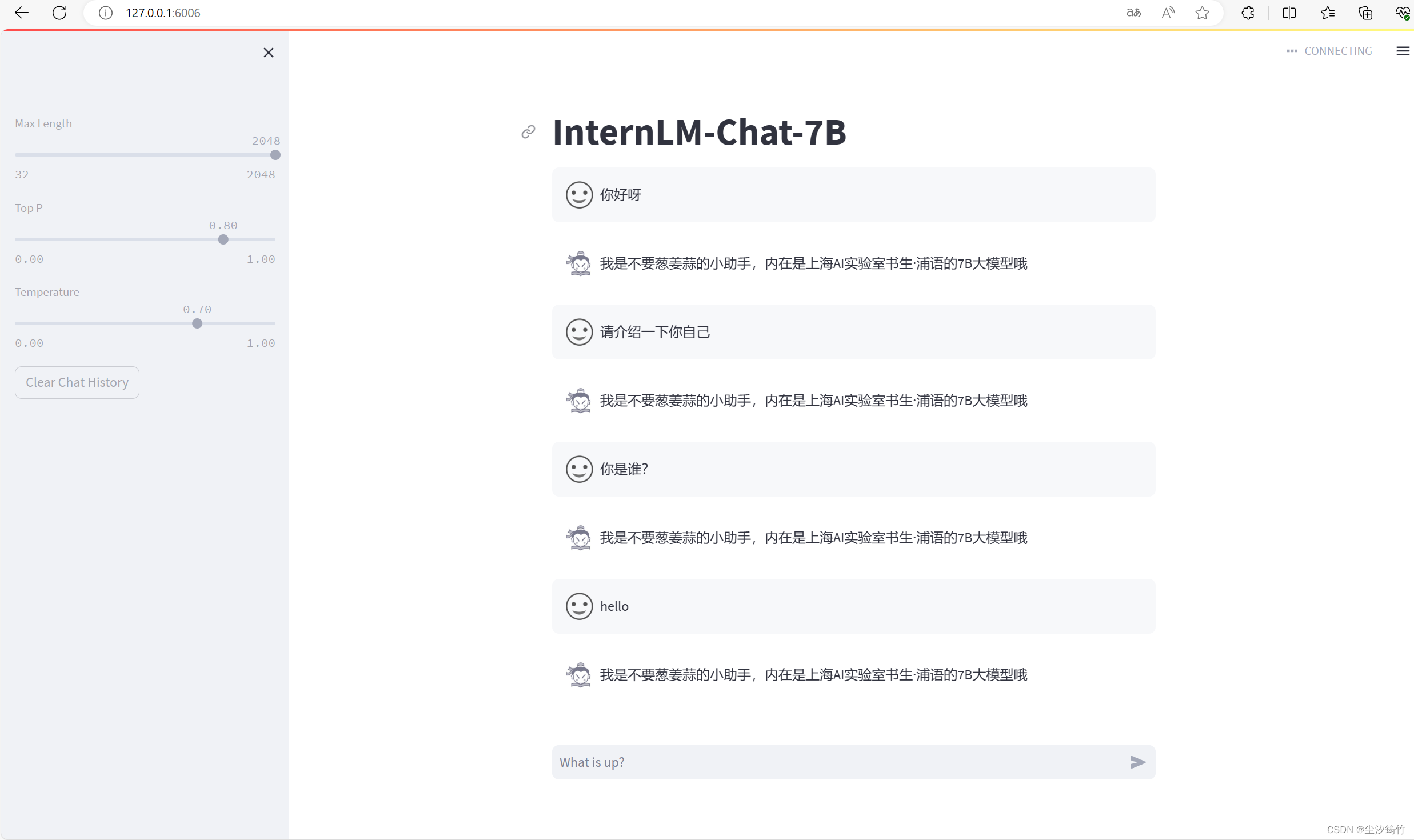
作业
构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手







































![[ceph] ceph应用](https://img-blog.csdnimg.cn/direct/7fb80d3a150946c79d3588560472f90a.png)