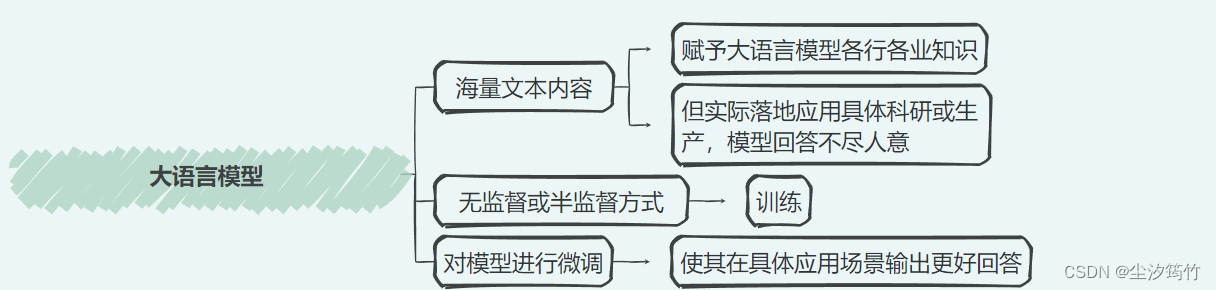
Finetune简介
增量预训练和指令跟随

通过指令微调获得instructed LLM
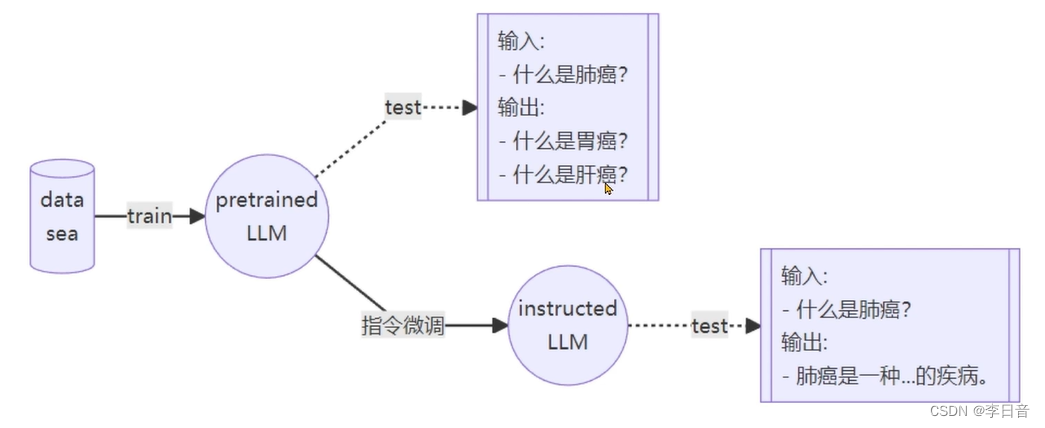
指令跟随微调
一问一答的方式进行
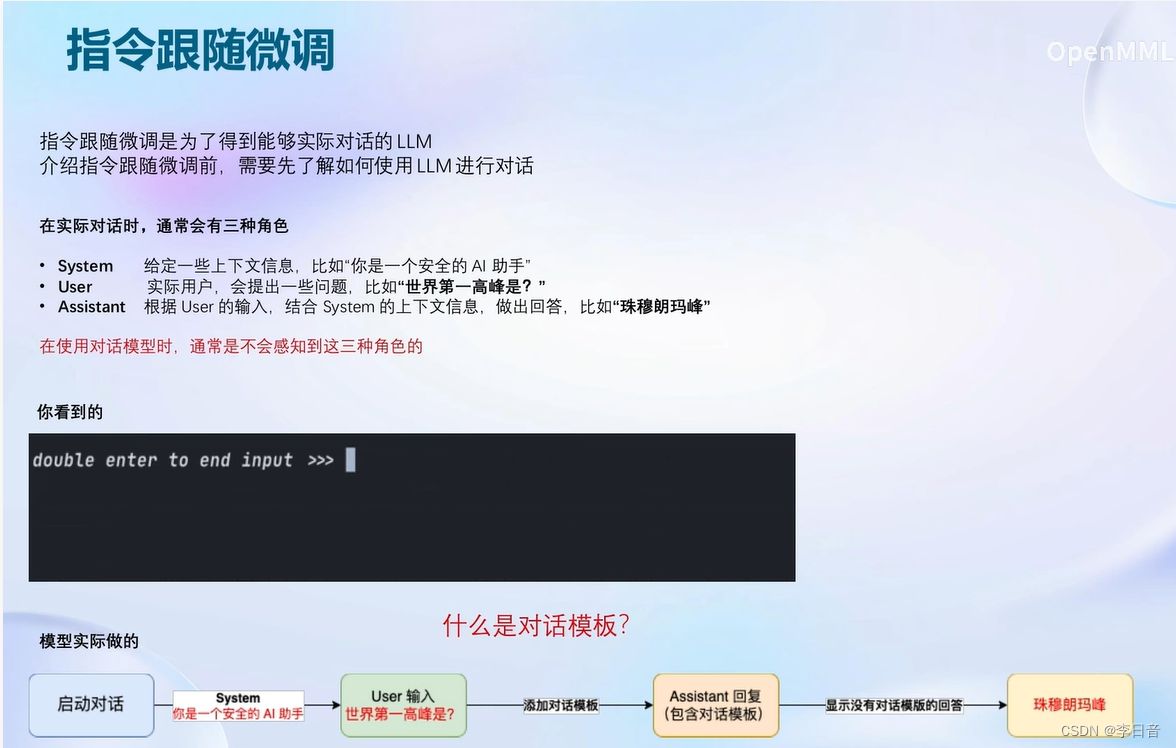
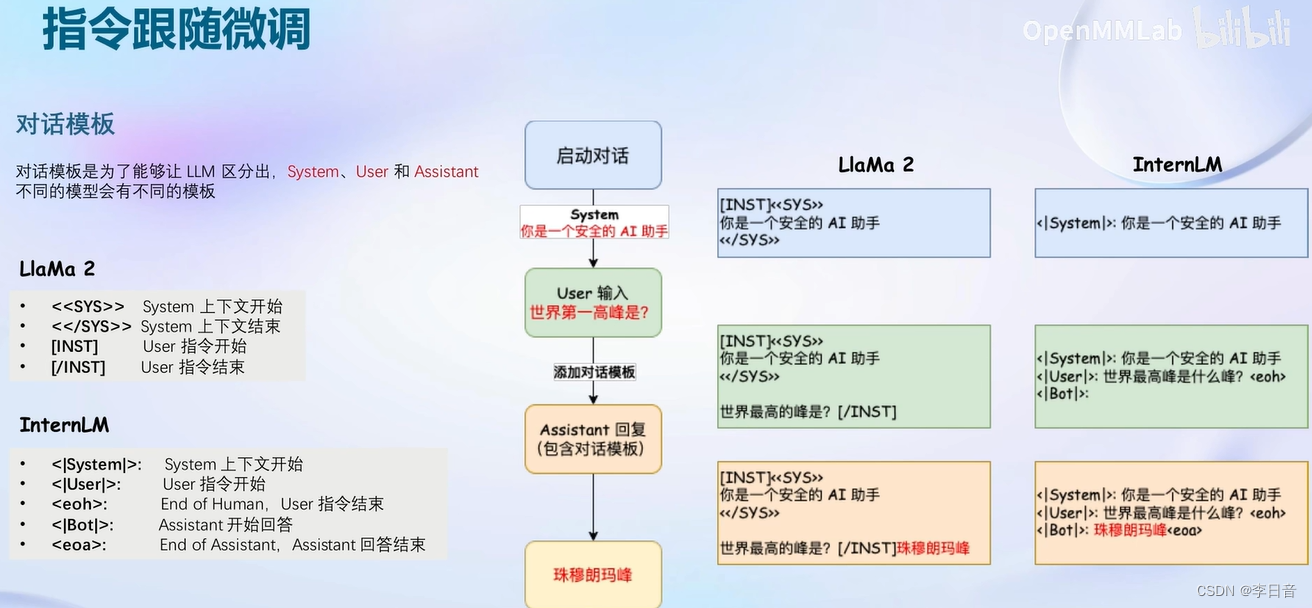
对话模板
计算损失

增量预训练微调
不需要问题只需要回答,都是陈述句。计算损失时和指令微调一样

LoRA QLoRA
不需要太大的显存开销。增加旁路分支Adapter。

比较:
- 全参数微调:整个模型加载到显存中,所有模型的参数优化器也要加载到显存中
- LoRA微调:模型也需要加载到显存中,但是参数优化器只需要LoRA部分
- QLoRA微调:加载模型时就4bit量化加载,参数优化器还可以在CPU和GPU之间调度,显存满了可以在内存里跑

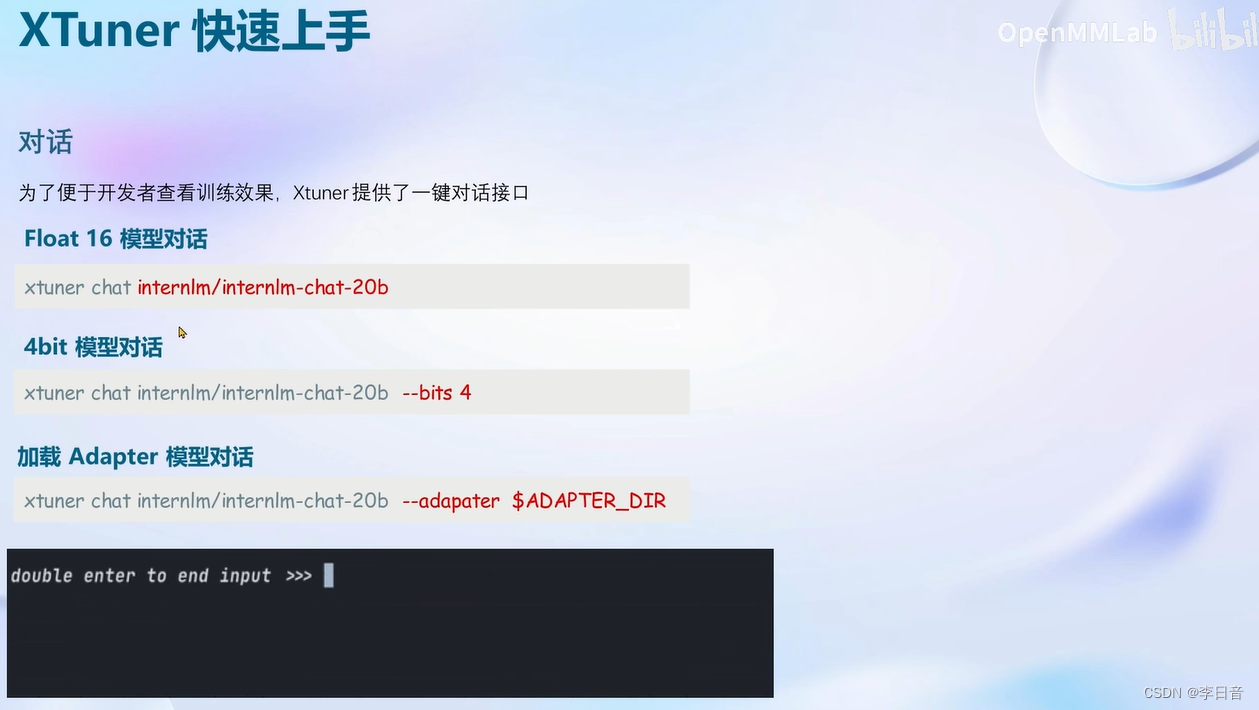
XTuner介绍

快速上手




























![[GDMEC-无人机遥感研究小组]无人机遥感小组-000-数据集制备](https://img-blog.csdnimg.cn/direct/c6c737dcb24f4095bcae99ced0ca38ee.png#pic_center)








![牛客网---------[USACO 2016 Jan S]Angry Cows](https://img-blog.csdnimg.cn/direct/28ff9e0c77214acfad39420256c6ea40.png)